
MySQL 优化三(优化规则)(高级篇)
0 / 1 / 创建于 6年前 /
 huxiaobai_001 的个人博客
huxiaobai_001 的个人博客
在看下边的内容的时候一定要保证你已经会用explain分析sql了!
索引单表优化案例:
问题:
比如我们要查询密码=666并且age>30的按照username倒叙排序的第一条记录;经过分析会发现sql内部优化器进行了全表扫描type=ALL extra当中还有using filesort的存在说明利用了外部的索引进行排序而没有用本表的索引进行排序 所以优化是必须要做的!
解决:
A:我们现在给where后边涉及到的字段都建立上索引 比如:
create index idx_pau on admin(password,age,username);
然后再进行分析:
我们发现type=range 避免了type=all这种全表扫描情况的发生 但是 在extra当中还是存在using filesort情况产生 这是因为我们创建的索引没有起作用 你会问 那不是在key字段当中有idx_pau索引说明索引起作用了啊!? 我们在查的时候where后边是password = 常量 age > 常量 然后order by username,password会用到符合索引当中的内容 age也会用到符合索引当中的内容 但是哟一条规则就是范围之后的索引是失效了的 前提是你创建的是复合索引 目前看来是这样的额! 因为我们创建索引的顺序是password age username 因为age是取的范围 所以后边的索引 username就会失效 所以才会造成using filesort情况还是存在的情况发生!
B.第一种正确解决方法:
为where后边涉及到的每个字段都建立上索引 比如:
create index idx_p on admin(password);
create index idx_p on admin(age);
create index idx_u on admin(username);
这样我们单独为where后边涉及到的字段都加上索引 那么首先type=all的问题一定解决了的 另外order by username的问题 之前我们讲过order by后边的字段建立索引的规则 最好和order by前边的字段名称相同 如果不同就和前边的字段一起创建复合索引 并且保持顺序相同 详见using filesort !但是这里出现另外一种情况就是单独给order by后边的字段创建上了索引 也没有出现using filesort情况的发生!
C.第二种正确解决方法:
那就是只为password 和 username创建复合索引
create index idx_pu on admin(password,username);
那么age > 0 没有走索引也就不会影响到order by后边的索引的使用了!那么age > 0 没有走索引也就不会影响到order by后边的索引的使用了!


索引两张表关联优化:
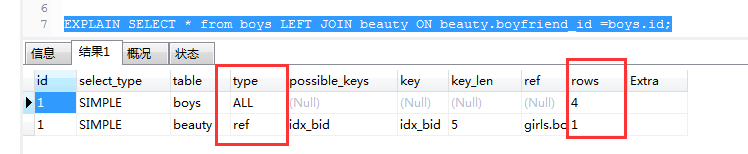
问题:boys当中的id=beauty当中的boyfriend_id 利用left join查询 我们常规的写法 然后通过explain进行分析得出下边的结论 发现type = all进行了全表扫描所以我们得要去优化一下!
如何优化呢?
总结:如果是left join那么给右表相应的字段添加索引 如果是right join 那么给左表相应的字段添加索引!
所以我们这里使用left join 那么给右边的表当中的字段添加索引 给beauty当中的boyfriend_id创建索引 然后再分析看看:
我们发现type当中有ref存在 并且rows的行数也减少了很多 完美的完成了优化任务!我们发现type当中有ref存在 并且rows的行数也减少了很多 完美的完成了优化任务!

三张表的关联优化:
原则就是保证join语句中被驱动表上join条件字段已经被索引
left join 左边为主表也就是驱动表 右边为被驱动表
right join相反
尽可能减少join语句中的循环总次数 原则就是永远用小结果集驱动大的结果集
myslq如何优化left join:https://www.cnblogs.com/zedosu/p/6555981.h...
索引优化正式环节
A.如何避免索引失效?A.如何避免索引失效?
对于上边总结的解释:
全值匹配:
比如我们为admin表创建了复合索引
create index idx_upa on admin(username,password,age);//为username password age 三个字段创建了复合索引
执行sql:
explain select * from admin where username=’john’ and password=8888 and age=29;
我们发现索引被充分的利用上了! 最好的避免索引失效的一个方法就是全值匹配 比如我们创建了idx_upa复合索引 那么我们在查询的时候字段的顺序和我们创建复合索引的顺序是一样的 开始末尾中间一个都不少的全写上 这样效率是最高也是绝对可以避免索引失效的 这就叫全值匹配!
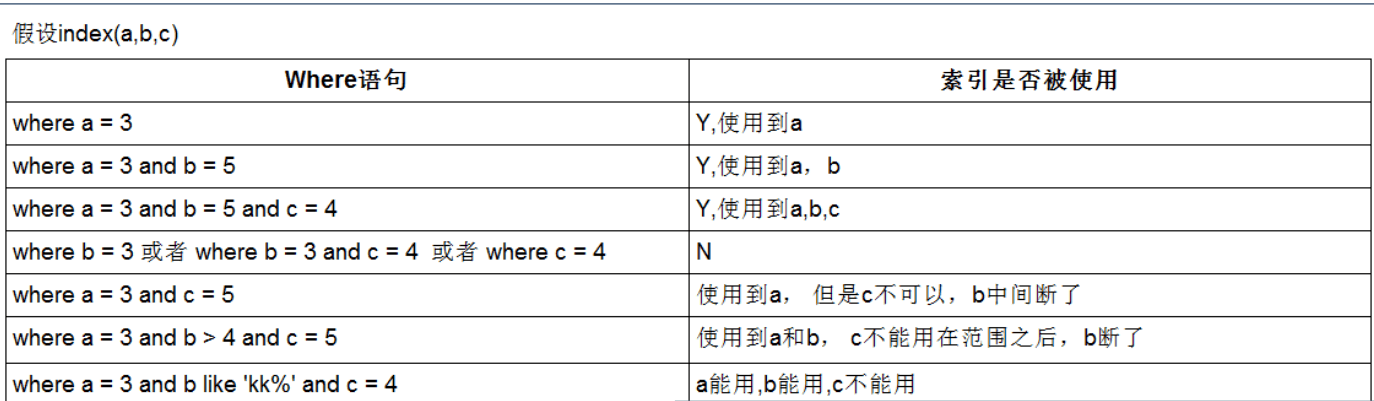
最佳左前缀法:(如果索引了多列也就是创建了复合索引 那么要遵守最左前缀法则 指的是查询从索引的最左前列开始并且不跳过索引中的列)
还是拿上边的案例来讲:
我们创建了idx_upa复合索引 在查询的时候不可能都是全值匹配 比如我们现在不查找username=‘’ password=‘’ age=‘’的了 我们要查找其中的任意两个 那么就会出现索引失效的情况发生!
A.比如:select * from admin where username=’’ and password=’’;
我们查的条件是username=’’ and password=’’ 因为username 和 password和复合索引idx_upa当中都是按照顺序来的 u代表username p代表password 顺序一致 所以不会出现索引失效
B.如果我们查select * from admin where password=’’ and age=’’ 那么就会出现索引失效的情况 因为违背了左前缀法则 在找索引的时候会先匹配最左侧的 然后往后找 第一个索引可以理解成火车头 火车头都找不到那么后边的也就不能用了!
C.如果我们查找的是select * from admin where username=’john’ and age=29; 那么虽然不会出现索引失效的提示 key当中也有索引的值 但是 但是 在之前索引不失效的前提下ref当中的const都是两个const 但是现在是一个const 说明其中有一个没有用上索引 这种情况数据量多了的话也是影响性能的 并且key_len的长度和我们单独去查找username=’’的时候的长度是一致的 所以可以肯定的是后边这个没有用上索引
D.如果我们单独查找select * from admin where age = 29;或者单独查找password=8888的这种情况也是会出现索引失效的情况的 因为我们是复合索引 越过第一个单独去找第二个第三个是绝对会失效的索引;
所以有句口诀:
带头大哥不能少!
中间兄弟不可断!
除了大哥其他兄弟单独行动都得死!
带头大哥舍弃中间几个兄弟 带着后边几个兄弟 结果就是只有带头大哥能活 其他都得死!
不在索引列上做任何操作(计算 函数 类型转换) 会导致索引实现转向全表扫描
复合索引idx_upa 我们从火车头上username上 它也是索引列上使用了函数 那么直接导致索引失效!
mysql当中不能使用索引中范围条件右边的列:
全职匹配的情况下:ref级别 并且ref列有三个const表示常量
索引当中存在范围:(如果不创建索引那一定是全表扫描 创建完索引有的索引不起作用 )
最后的结果是range范围级别 明显不如ref级别高 另外ref当中为空 说明有的索引列没起作用! 解决方法上边讲过!
如果我们不使用复合索引而是为三个字段单独创建索引那么就变成了ref级别
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)减少select *)
以上讲的都是复合索引的前提下哈!
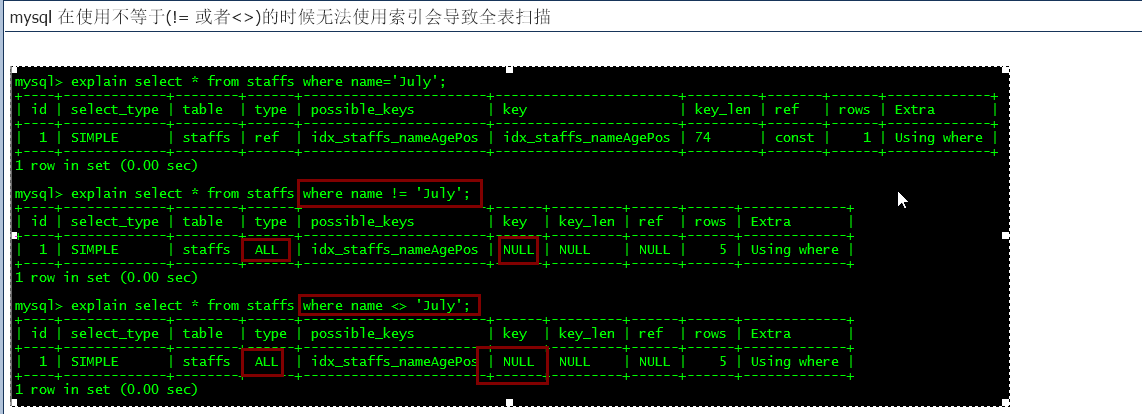
mysql当中使用不等于!=或者<>的时候无法使用索引并且会导致全表扫描
is null in not null 也无法使用索引
并且is not null会进行全表扫描
所以 我们可以给字段约上默认值 这样就不会产生null的情况 也就避免了使用is null和is not null情况的发生!
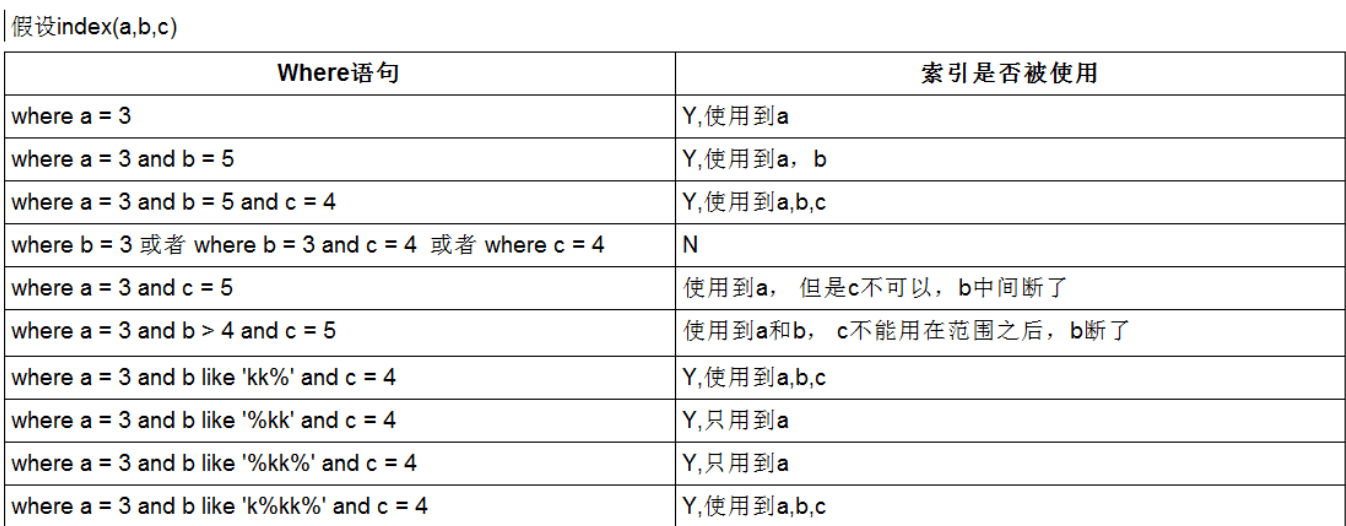
like以通配符开头(%adb% 或者 %abc)的情况 mysql索引会失效并且变成全表扫描 但是 like ‘abc%’是不会造成索引失效的情况发生的
但是在开发过程当中我们经常会遇到必须是%abc%的情况 又该如何解决索引失效的问题呢?
那就是使用覆盖索引!什么是覆盖索引之前上边讲过
比如:
create index idx_username on admin(username); 我们给username列创建了索引
然后发现 select username from admin where username like ‘%h%’;
但是如果我们这么查:select * from admin where username lilke ‘%abc%’;
那么就会造成索引失效的现象并且会全表扫描 因为没有用上覆盖索引!
并且但是如果我们这么查找 select password from admin where username like ‘%abc%’;也是会全表扫描并且索引失效
但是如果我们这么查找 select id,username from admin where username like ‘%abc%’; 就不会造成全表扫描和索引失效 因为id始终是主键也是从index索引表当中去查找相当于也是覆盖索引!
注意:如果我们创建的是复合索引 那么只要是查询的列在复合索引范围内的都是可以避免全表扫描并且避免索引失效问题产生的!
varchar类型的列字符串如果不加单引号则索引失效
比如varchar类型我们平时都是存储的字符串 但是有时候迫不得已存放个2000 或者其他数字 如果在查询的时候不注意没有加上单引号 那么sql优化器就会首先进行隐式的类型转换然后再去搜索并且最主要的是索引失效并且进行了全表扫描
少用or,用它来链接的时候会造成索引失效
如果用or来连接 比如 select * from admin where username=a or username=b;这样也会造成索引失效并且造成全表扫描;解决的方式不如分开查 然后到php当中再去拼接成一个数组
简单小测试 配合理解一下:












面试题精讲 有助于理解更好的去使用:
前提是我们创建好了复合索引 idx_test03_c1234 c1 c2 c3 c4这么一个顺序的复合索引哦!
A:索引顺序不同 第一个是c1 c2 c3 c4
第二个是c1 c2 c4 c3
第三个是c4 c3 c2 c1
结果都是一样的 都被用上了索引 也就是说索引有没有被用到和复合索引的顺序无关
B:当中出现了范围查询 我们看到结果是range范围级别 那么说明 c1 c2 c3都被用上了 但是ref为空 按照道理来说应该ref为4个const 但是ref为null 并且key_len的长度正好比四个都用上少一个的长度 那么就是说明c4索引失效了! 这也验证了范围之后全失效的原则
C.c1=’a1’ and c2=‘a2’ and c4>’a4’ and c3 = ‘a3’
这种情况下虽然我们的sql指令顺序变了 但是sql优化器内部会按照c1 c2 c3 c4的索引顺序去查找 虽然c4是范围查找但是它是在最后被sql优化器找到的 所以4个索引都是有效果的
D:c1=’a1’ and c2=‘a2’ and c4=‘a4’ order by c3 中间兄弟不能断 看来这里明显是断开了 所以肯定的是c1 c2是绝对被用到了的 order by c3其实c3也是被用到了的 只不过是被用到了排序上 在explain当中是不体现的! c4是绝对没有被用上的! 如果c3也没有被用上 那么extra当中是要有usging filesort的 前边讲过 这种using filesort九死一生效率极差!
E:c1=a1 and c2=a2 order by c3 结果和D是一样的 c4肯定没被用上 c3去排序去了不在explain当中显示 c1 c2是绝对被用上了的!
F:c1=a1 and c2=a1 order by c4; 结果是c1 c2被使用 c3 c4不被使用 并且还产生了using filesort
G:c1=a1 and c5=a5 order by c2,c3 结果是c1被使用 c2和c3被使用但是去排序去了 不会产生using filesort
H:c1=a1 and c5=a5 order by c3,c2 结果是c1被使用 因为索引顺序是1234 但是order by 的时候出现了3 然后再2 所以会导致using filesort的发生
I:c1=a1 and c2=a2 order by c2,c3 结果是c1 c2都被使用了 并且排序也是按照c2 c3顺序排序 没毛病 非常完美
c2=a2是一个常量了已经 order by 常量,c3 那么这个常量排序也就是死的 其实就是按照c3排序 c3在索引当中 所以没毛病
(前提是我们从前边查找出了c2=a2是一个常量)
j: c5=a5只是用来迷惑你的 娃哈哈
K:c1=a1 and c5=a5 order by c3,c2 一定是用到了c1 但是c3 c2 顺序和索引不一致也会导致filesort的产生
L:c1=a1 and c4=a4 group by c2,c3 ; c1一定是被用到了索引 c4绝对没被用到 group by当中c2 c3也被用到了 因为也是符合我们的索引顺序的 1234 2 3是符合这么个顺序的 但是在explain当中是不显示的哦
M::c1=a1 and c4=a4 group by c3,c2 c1一定是被使用了索引的 c4绝对没有被使用 group by 后边 c3 c2因为违背了我们的索引顺序 所以会产生临时表以及using filesort的产生 情况很不妙!













小总结:
explain分析先看定值也就是常量 然后看范围 范围之后的索引必失效 然后看order by order by的顺序要和索引顺序保持一致如果不一致会产生filesort情况的发生 啥意思呢 我们规定了索引的顺序 但是我们在写sql指令的时候不是按照找个顺序执行的 那么sql优化器就会在内部进行产生内排序 也就是我们看到的using filesort情况的发生
group by 基本上都需要进行排序 如果使用的字段索引不正确也是和order by 一样 在内部先进行排序 然后排序完成之后要么进行搬家 要么进行删除 于是乎就产生了临时表
所以索引的使用非常的重要 尤其是正确使用索引!
优化口诀:

查询优化:
永远小表驱动大表
如图所示 也许在php程序当中两个for循环的结果是一样的 但是在mysql当中确是不一样的 第一个会建立5次mysql的链接 而 第二个则会建立1000次链接 对于mysql来说最伤身的就是建立连接释放连接这玩意了 所以永远要小表驱动大表
优化原则:小表驱动大表 即小的数据集驱动大的数据集
in的右边小结果集 existx的右边是大的结果集

order by 详解:
order by 子句 尽量使用index方式排序order by 子句 尽量使用index方式排序 避免使用using filesort方式排序
对于order by的研究 我们主要就是看会不会产生using filesort 出现就不好了哦
接下来看我们自己的案例:
create index idx_p_u on admin(password,username);创建password username 复合索引
特别注意:只要用到order by 那么前边就不要使用select * 而是按需查找 要什么字段就写什么字段 因为你一旦写上select * 下边的总结就都不准了
第一种情况:
explain select username,password from admin order by username;//有带头大哥存在username order by后边复合最左前缀法则所以 没毛病
第二种情况:
explain select username,password from admin where username=’john’ order by username;//加上where条件也是带头大哥存在 order by后边复合最左前缀法则 没毛病
第三种情况:
explain select username,password from admin where password > 10 order by username;//我们索引的顺序是username password 虽然我们在指令当中写的顺序不对 但是sql优化器会自动给我们对索引排序 order by后边复合最左前缀法则
第四种情况:
explain select username,password from admin where username=’john’ order by password;//符合 使用where子句与order by子句条件列组合满足索引最左前缀法则!
我们再来看下边这个经典案例:
默认我们创建的索引列的排序都是升序排序的asc 虽然这里我们order by的顺序没有变 age birth 但是排序方式变了 birth是desc方式排序 索引sql内部也是会进行一次外部排序 所以也会产生filesort情况的发生的 总结:要么同升要么同降
order by 满足两种情况 会使用index方式排序:
第一个的解释:order by 后边使用和索引列相同顺序的字段 比如idx_name_age 我们order by name或者order by name,age都不会出现filesort情况的产生
第二个的解释:使用where 子句与order by 子句条件列组合 比如我们创建了name age的复合索引 select * from admin where name=’a’ order by age; 这就是where子句和order by子句条件列组合满足索引的最左前缀法则;
也就是说尽可能在索引列上完成排序操作 遵照索引建的最佳左前缀法则;
最终我们对order by做最后的总结(非常重要):







group by 详解:
其他的都和order by一样
最大的区别就是where 高于 having 能写在where限定的条件就不要去having限定了!

本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: