
数据结构和算法-二叉树,AVL,红黑树
0 / 0 / 创建于 6年前 /
 Runtoweb3 的个人博客
Runtoweb3 的个人博客
二叉树
前序遍历(根在前,从左往右,一棵树的根永远在左子树前面,左子树又永远在右子树前面 )
中序遍历(根在中,从左往右,一棵树的左子树永远在根前面,根永远在右子树前面)
后序遍历(根在后,从左往右,一棵树的左子树永远在右子树前面,右子树永远在根前面)
二叉树的存储方式
链式存储法
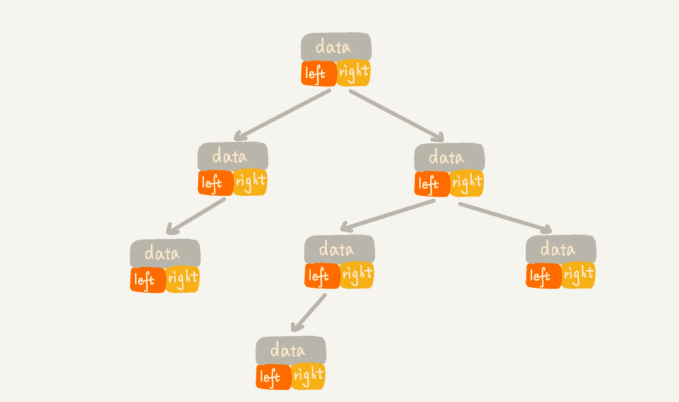
每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针。这种存储方式我们比较常用。大部分二叉树代码都是通过这种结构来实现的。
基于数组的顺序存储法,比较适合完全二叉树
根节点存储在下标 i = 1 的位置,那左子节点存储在下标 2 * i = 2 的位置,右子节点存储在 2 * i + 1 = 3 的位置。以此类推。
二叉查找树(一个有序的二叉树,中序遍历,是一个有序的排列)
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
查找:我们先取根节点,如果它等于我们要查找的数据,那就返回。如果要查找的数据比根节点的值小,那就在左子树中递归查找;如果要查找的数据比根节点的值大,那就在右子树中递归查找。
插入:二叉查找树的插入过程有点类似查找操作。新插入的数据一般都是在叶子节点上,所以我们只需要
从根节点开始,依次比较要插入的数据和节点的大小关系。
删除:但是它的删除操作就比较复杂了 。针对要删除节点的子节点个数的不同,我们需要分三种情况来处理
第一种情况是,如果要删除的节点没有子节点,直接删除节点,并把它的父节点指向null.
第二种情况是,如果要删除的节点只有一个子节点(只有左子节点或者右子节点),只需要把父节点的指针指向它的子节点,空开被删除的节点。
第三种情况是,如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子
树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没
有左子节点(如果有左子结点,那就不是最小节点了)
二叉查找树的优势
二叉查找树在比较平衡的情况下,插入、删除、查找操作时间复杂度才是 O(logn),和数组的二分查找相同。
第一,散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找
树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
第二,散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳
定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,
这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,
也不一定就比平衡二叉查找树的效率高。
第四,散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决
办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比
较成熟、固定。
最后,为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的散
列表,不然会浪费一定的存储空间
8.红黑树(可以看成不严格的AVL)
先认识一下平衡二叉查找树(AVL),平衡二叉树的严格定义是这样的:二叉树中任意一个节点的左右子树的高度相差不能大于 1。但是很多平衡二叉查找树其实并没有严格符合上面的定义,我们这个平衡的意思就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
平衡二叉查找树其实有很多,比如,Splay Tree(伸展树)、Treap(树堆)等,但是我们提到平衡二叉查找树,听到的基本都是红黑树。它的出镜率甚至要高于“平衡二叉查找树”这几个字,有时候,我们甚至默认平衡二叉查找树就是红黑树,那我们现在就来看看这个“明星树”。
一棵红黑树还需要满足这样几个要求:
根节点是黑色的;
每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;
每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
为什么不使用AVL而使用红黑树
最常见的回答是:红黑树相比于AVL树,牺牲了部分平衡性,以换取删除/插入操作时少量的旋转次数,整体来说,性能优于AVL树。
go实现二叉树
type Node struct {
data interface{}
left,right *Node
}
func (node *Node)Print() {
fmt.Println(node.data)
}
func CreateNode(data interface{}) *Node{
return &Node{data:data}
}
//前序遍历,先读自己,再读left,然后right
func (node *Node)PreOrder(){
if node==nil{
return
}
node.Print()
node.left.PreOrder()
node.right.PreOrder()
}
func main() {
root:= CreateNode(3)
root.left = CreateNode(1)
root.right = CreateNode(5)
root.right.right = CreateNode(6)
root.PreOrder()
}本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: