
数据结构和算法-go 实现散列表 (HashTable)
0 / 0 / 创建于 6年前 /
 Runtoweb3 的个人博客
Runtoweb3 的个人博客
我们知道数组是顺序存储的,通过下标可获取值的时间复杂度是O(1)。HashTable随机访问元素的复杂度也是O(1)。
我们通过散列函数把元素的键映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。散列函数
顾名思义,它是一个函数。我们可以把它定义成hash(key),其中 key表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。
该如何构造散列函数呢?我总结了三
点散列函数设计的基本要求:
1. 散列函数计算得到的散列值是一个非负整数;
2. 如果 key1 = key2,那 hash(key1) == hash(key2);
3. 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)(理论上没有hash函数能够满足这个条件,hash冲突需要其他方式解决)
散列冲突
当我们用不同的键经过hash函数得到的散列值相同时,我们称之为散列冲突。一般有两种解决方法
1.开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。比如线性探测(Linear Probing),当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
举个例子,有两个键”cat”,”dog”; 经过hash(“cat”),hash(“dog”)得到的值都是10。所以”cat”会存在下标为10的位置,存”dog”键时,发现10已经有值,会顺序往后找空闲位置,然后存进去。当用”dog”键获取数据时,先通过hash(“dog”)得到10,10下标放的是”cat”!=”dog”,就会顺序往下找,直到找到”dog”。
但是删除操作稍微有些特别。我们不能单纯地把要删除的元素设置为空,而是特殊标记为 deleted。插入元素时,当线性探测空闲位置时,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
2. 链表法
在散列表中,每个“桶(bucket)”或者“槽(slot)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
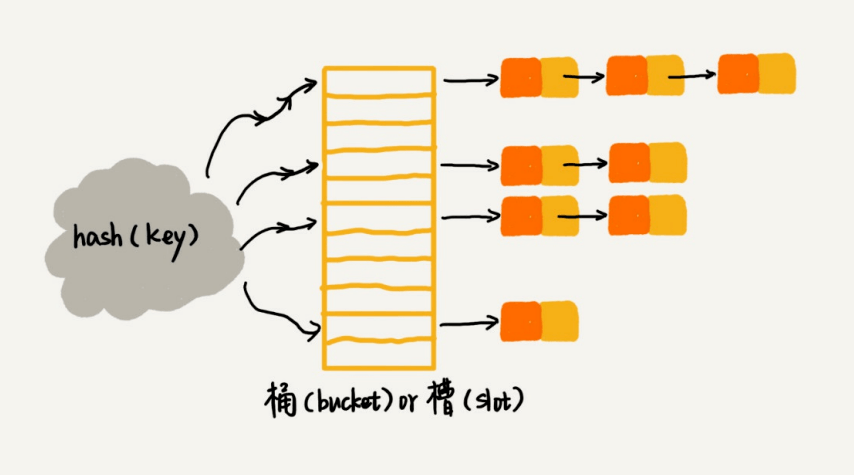
当插入的时候,我们只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,所以插入的时间复杂度是 O(1)。当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。
散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
HashTable和链表一起使用
HashTable的特点是通过key值查找目标数据的复杂度是O(1),而链表却很方便我们把数据按照一定顺序连接起来,很多情况下使用链表时,再把数据放入HashTable保存起来。
LRU缓存算法改进
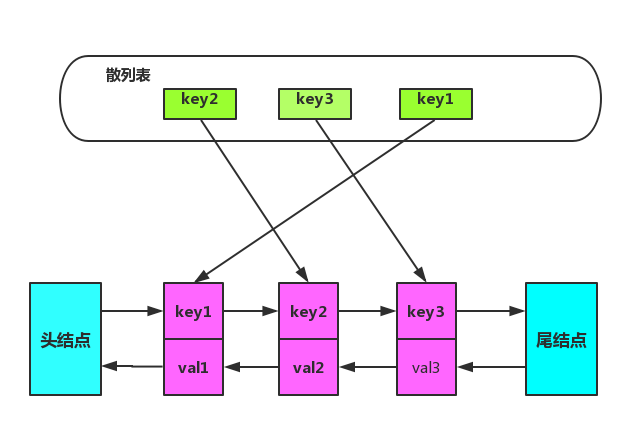
如果单用链表实现
新增一个缓存key,先查询链表是否有key,如果有就把这个key节点移动到表头。
如果没有,表未满,直接加到表头。链表已满,就先删除表尾一个节点,再把新增的key节点插入到表头。
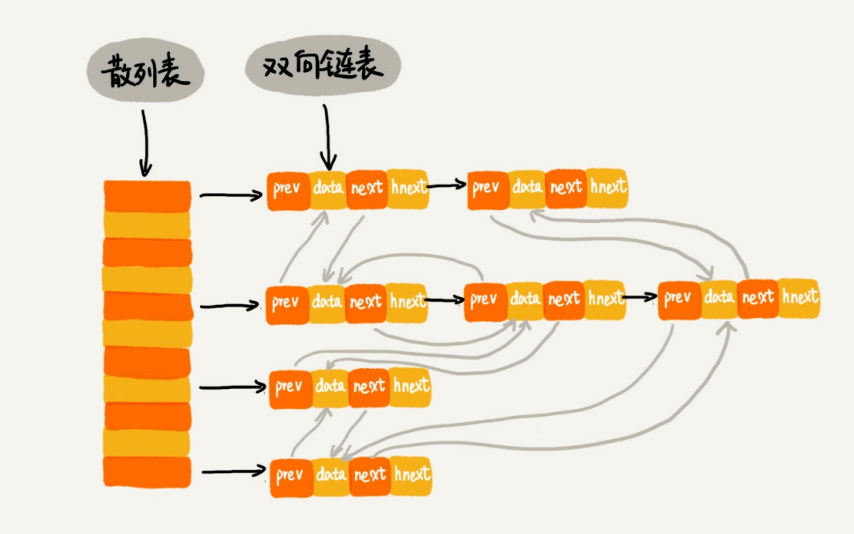
改进后:链表+HashTable
新增key节点,直接查询HashTable是否有key,如果有,就把key节点加到链表头。
如果没有,表未满,直接加到表头。链表已满,就先删除表尾一个节点,再把新增的key节点插入到表头。
数据虽然是写到两个表中,其实一个数据只有一个数据节点,两个表共用了数据节点,链表只是靠指针串起来的。
底层实现
const (
expandFactor = 0.75
)
type HashMap struct{
m []*KeyPairs //hash表的桶
cap int
len int
}
type KeyPairs struct{ //键值对
key string
value interface{}
next *KeyPairs
}
//初始化一个hashmap
func NewHashMap(cap int) *HashMap{
if cap < 16 {
cap = 16
}
hashMap := new(HashMap)
hashMap.m = make([]*KeyPairs,cap,cap)
return hashMap
}
func (h *HashMap)Index(key string) int{
return BKDRHash(key, h.cap) //计算键的哈希值
}
//写入一个键值对
func (h *HashMap)Put(key string, value interface{}) {
index := h.Index(key)
element := h.m[index]
if element == nil { //该下标没有值,直接写入
h.m[index] = &KeyPairs{key,value, nil}
}else{ //有值,找到最后一个节点
for element.next != nil {
if element.key == key { //如果是相同的键就进行修改操作
element.value = value
return
}
element = element.next
}
element.next = &KeyPairs{key,value,nil}
}
h.len++
if (float64(h.len)/float64(h.cap))>expandFactor { //需要扩容,把切片容量变为2倍
newH := NewHashMap(2*h.cap)
for _,pairs := range h.m {
for pairs != nil {
newH.Put(pairs.key,pairs.value)
}
}
h.cap = newH.cap
h.m = newH.m
}
}
//获取值
func (h *HashMap)Get(key string) interface{}{
index := h.Index(key)
pairs := h.m[index]
if pairs.key == key {
return pairs.value
}
for pairs.next != nil {
if pairs.key == key {
return pairs.value
}
pairs = pairs.next
}
return nil
}
//go实现hash表
func main() {
h := NewHashMap(32)
h.Put("aa","bb")
res := h.Get("aa")
fmt.Println(res)
}
func BKDRHash(str string, cap int) int {
seed := int(131) // 31 131 1313 13131 131313 etc..
hash := int(0)
for i := 0; i < len(str); i++ {
hash = (hash * seed) + int(str[i])
}
return hash%cap
}
注意:1.初始化hashMap中的切片m时,需要保证hashMap.m = make([]*KeyPairs,cap,cap)长度和容量一致,不然用index去获取m[index]会越界
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: