
《Learning ELK Stack》2 构建第一条ELK数据管道
0 / 0 / 创建于 6年前
 yeedomliu 的个人博客
yeedomliu 的个人博客
2 构建第一条ELK数据管道
本章将使用ELK技术栈来构建第一条基本的数据管道。这样可以帮助我们理解如何将ELK技术栈的组件简单地组合到一起来构建一个完整的端到端的分析过程
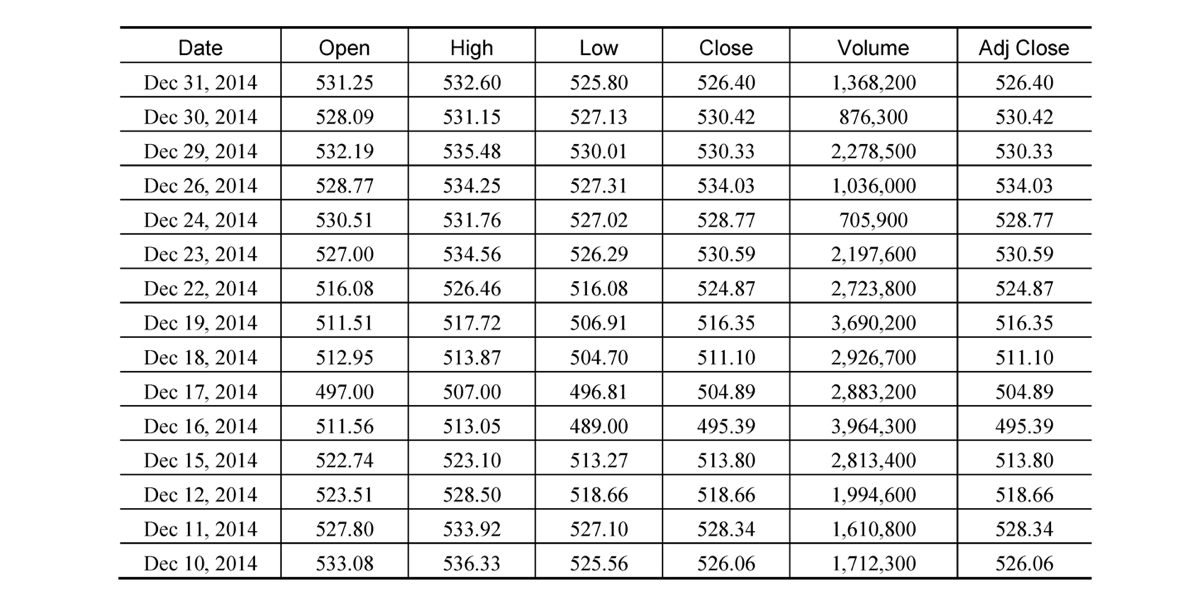
输入的数据集
- 在我们的例子中,要使用的数据集是
google每天的股票价格数据
输入数据集的数据格式
- 字段包括
Date(日期)、Open Price(开盘价)、Close Price(收盘价)、High Price(最高价)、Volume(成交量)和Adjusted Price(调整价格)
配置Logstash的输入
- 文件输入插件可以从文件中读取事件到输入流里,文件中的每一行会被当成一个事件处理。它能够自动识别和处理日志轮转。如果配置正确,它会维护读取位置并自动检测新的数据。它读取文件的方式就类似于
tail -0f
input {
file {
path => "文件路径(必选项)"
start_position => "读取数据的开始位置"
tags => "任意字符串数组,能在随后针对事件做一些过滤和处理"
type => "标记事件的特定类型"
}
}path:文件输入插件唯一必填的配置项start_position:从源文件读取数据的开始位置,可以是beginning或end。默认是end,这样可以满足读取活动的流数据的场景需求。如果需要读取历史数据,可以设置为beginningtags:可以是任意数量的字符串数组,在随后基于tags来针对事件做一些过滤和处理type:标记事件的特定类型,可以在随后的过滤和搜索中有所帮助 。type字段会保存在es的文档中,并通过kibana的_type字段来进行展现
如,可以将type设置为error_log或者info_logs
input {
file {
path => "/opt/logstash/input/GOOG.csv"
start_position => "beginning"
}
}因为是历史数据,所以需要设置start_position为beginning
过滤和处理输入数据
- 接下来可以根据需要对输入数据进行过滤,以便识别出需要的字段并进行处理,以达到分析的目的
- 因为我们输入文件是
CSV文件,所以可以使用csv过滤插件。csv过滤器可以对csv格式的数据提取事件的字段进行解析并独立存储
filter {
csv {
columns => #字段名数组
separator => # 字符串;默认值,
}
}columns属性指定了csv文件中的字段的名字,可选项。默认将字段命名为column1、column2等等separator属性定义了输入文件中用来分割不同字段的分割符。默认是逗号,也可以是其他任意的分割符
filter {
csv {
columns => ["date_of_record", "open", "high", "low", "close", "volumn", "adj_close"]
separator => ","
}
}- 我们需要指定哪个列代表日期字段,以便它可以被显式地索引为日期类型,这样可以用于基于日期的过滤。
Logstash中有一个叫date的过滤器可以完成上述任务
filter {
date {
match => # 默认值是[]
target => # 默认值是@timestamp
timezone => ","
}
}match:是一个[域,格式],可为每个字段设置一种格式timestamp:在上述例子中,我们采用了历史数据,不希望使用时间捕获时的时间作为@timestamp,而是使用记录生成时的时间,所以我们将date字段映射为@timestamp。这不是强制的,但建议这样做- 可以使用
mutate过滤器将字段转换为指定的数据类型,这个过滤器可以用于对字段做各种常见的修改,包括修改数据类型、重命名、替换和删除字段。另外也可以用来合并两个字段、转换大小写、拆分字段等等 date过滤器可以配置如下
date {
match => ["date_of_record", "yyyy-MM-dd"]
target => "@timestamp"
}- 我们的案例中,因为我们采用了历史数据,不希望使用时间捕获时的时间作业
@timestamp,而是使用记录生成时的时间,所以我们将date字段映射为@timestamp,这不是强制的,但建议这样做 - 我们使用
mutate过滤器将字段转换为指定的数据类型。这个过滤器可以用于对字段做各种常见的修改,包括修改数据类型、重命名、替换和删除字段。另外也可以用来合并两个字段、转换大小写、拆分字段等等
filter {
mutate {
convert => # 列以及数据类型的Hash值(可选项)
join => # 用于关联的列的Hash值(可选项)
lowercase => # 用于转换的字段数组
merge => # 用于合并的字段的Hash值
rename => # 用于替换的字段的Hash值
replace => # 用于替换的字段的Hash值
split => # 用于分割的字段的Hash值
strip => # 字段数组
uppercase => # 字段数组
}
}- 这是例子的实际配置
mutate {
convert => ["open", "float"]
convert => ["high", "float"]
convert => ["low", "float"]
convert => ["close", "float"]
convert => ["volume", "float"]
convert => ["adj_close", "float"]
}- 使用了
convert功能来将价格和成交量字段转换为浮点数和整数类型
将数据存储到Elasticsearch
- 我们配置好使用
Logstash的CSV过滤器(用来处理数据),并且已根据数据类型对数据进行解析和处理。接下来将处理后的数据存储到Elasticsearch,以便对不同字段做索引,这样后续就可以使用Kibana来展现
output {
elasticsearch {
action => # 字符串(可选项),默认值:"index"(索引),delete(根据文档ID删除文档)
cluster => # 字符串(可选项),集群名字
hosts=> # 字符串(可选项)
index=> # 字符串(可选项),默认值:"logstash-%{+YYYY.MM.dd}"
index_type => # 字符串(可选项),事件写入的索引类型,确保相同类型的事件写入相同类型的索引
port => # 字符串(可选项)
protocol => # 字符串,协议类型,取值为["node","transport","http"]
}
}- 来看一下完整的
Logstash配置
input {
file {
path => "/GOOG.csv"
start_position => "beginning"
}
}
filter {
csv {
columns => ["date_of_record","open","high","low","close","volume","adj_close"]
separator => ","
}
date {
match => ["date_of_record", "yyyy-MM-dd"]
}
mutate {
convert => ["open", "float"]
convert => ["high", "float"]
convert => ["low", "float"]
convert => ["close", "float"]
convert => ["volume", "float"]
convert => ["adj_close", "float"]
}
}
output {
elasticsearch {
hosts=>"localhost"
}
}- 保存并命名为
logstash.conf
bin/logstash -f logstash.conf使用Kibana可视化
运行
- 运行如下程序,然后打开浏览器地址
http://localhost:5601,默认使用logstash-*索引
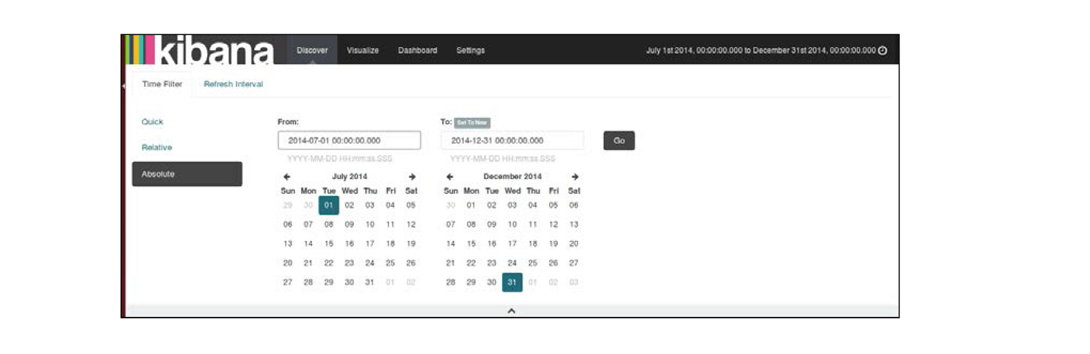
bin/kibana- 首先,需要在数据的日期范围内设置日期过滤器,以构建我们的分析。点击右上角的时间过滤器(
Time Filter),根据数据的日期范围来设置绝对时间过滤器
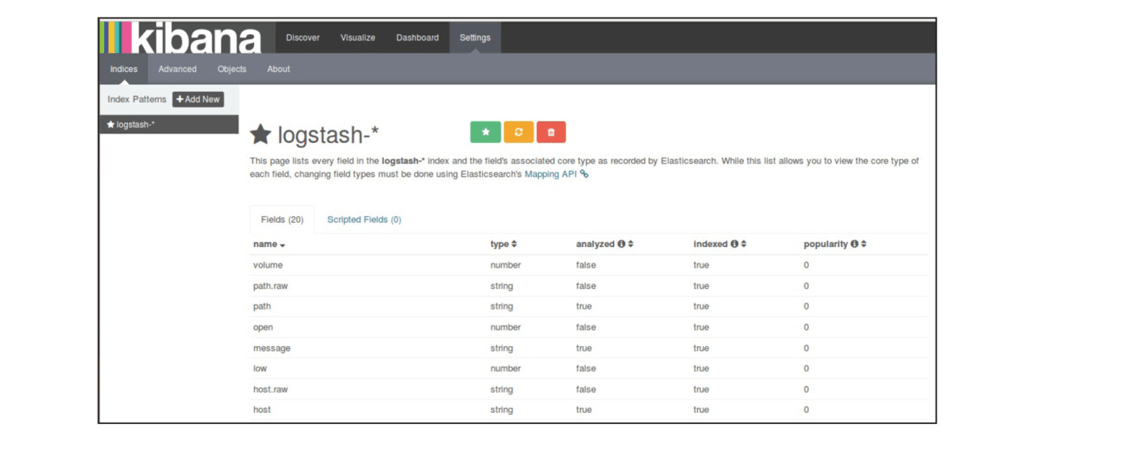
- 在构建可视化报表之前,需要先确认所有的字段是否已经根据其数据类型建立了正确的索引,这样才能对这些字段执行合适的操作
- 点击屏幕上方的
Settings页面链接,然后选择屏幕左边的logstash-*索引模式
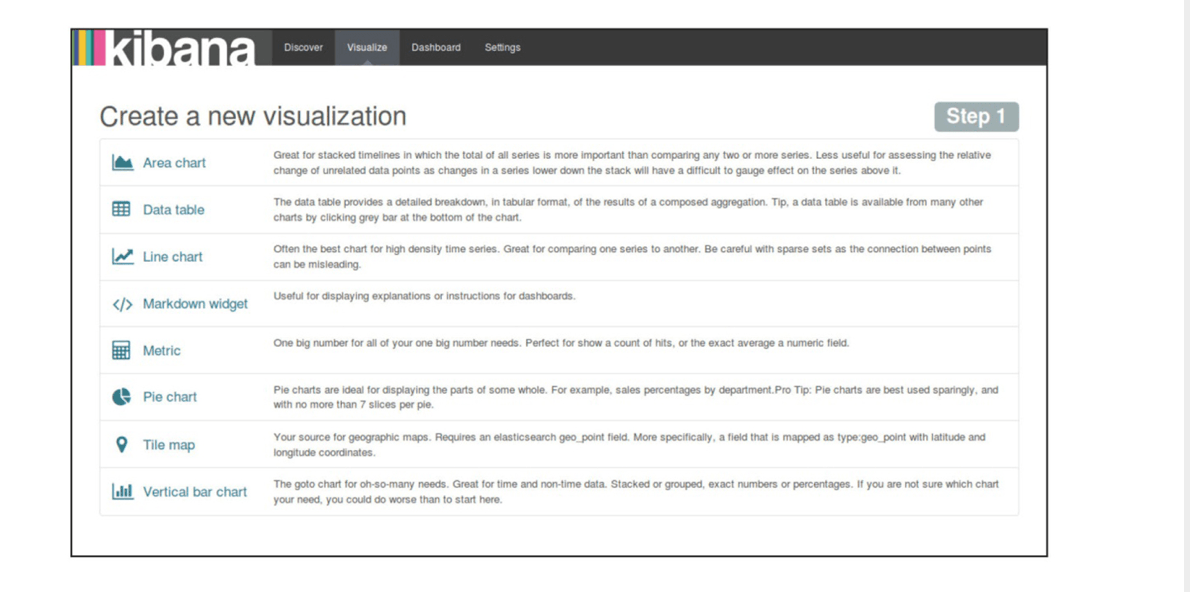
可视化组件
Kibana主页上方点击可视化(Visualize)页面链接,然后点击新建可视化的图标- 此页显示多种可视化组件都可以用
Kibana接口来实现
构建折线图
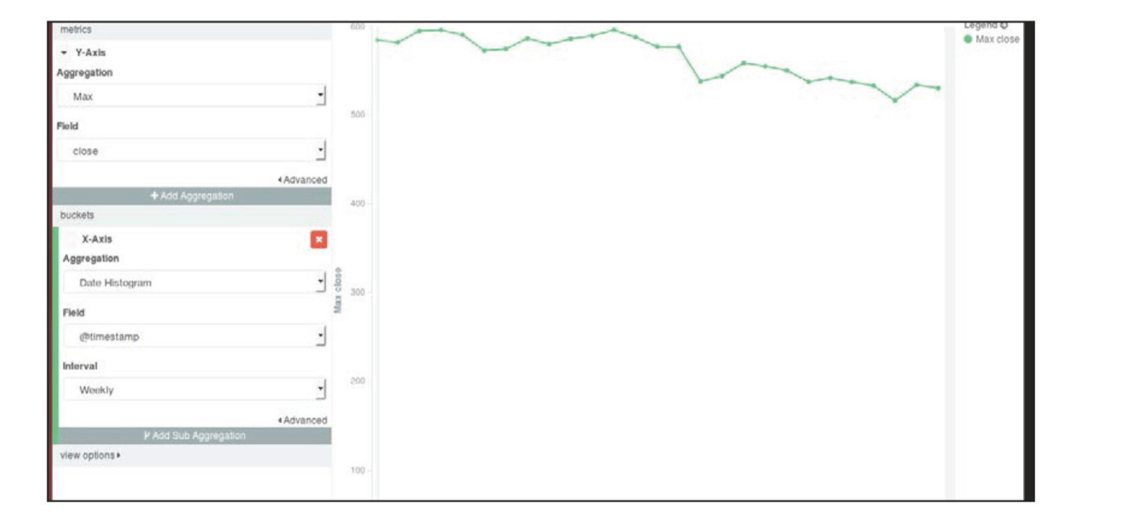
- 首先构建一个折线图,用来显示六个月来
GOOG每周收盘价的指数趋势 - 从上图可视化菜单中选择折线图,然后选择Y轴(
Y-Axis)的聚合函数为Max,字段为close。在桶(buckets)的区域,选择聚合(Aggregation)为基于@timestamp字段的日期直方图(Date Histogram),间隔(Interval)选择每周(Weekly),点击应用(Apply)。将上述折线图保存并命名,随后可在仪表盘中使用
构建柱状图
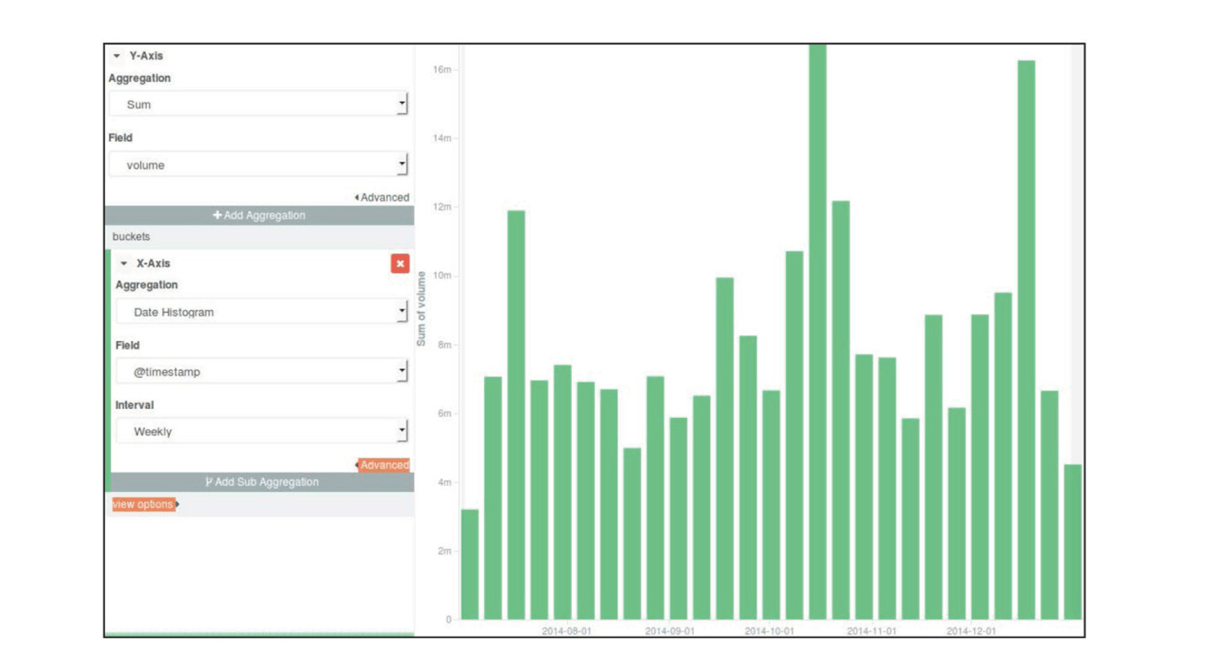
- 构建一个垂直柱状图呈现六个月内的成交量变化趋势
- 在可视化菜单中选择垂直柱状图,选择Y轴的聚合函数为
Sum,字段为volume。在桶的区域,选择X轴的聚合函数为基于@timestamp字段的日期直方图,间隔选择每周
构建度量
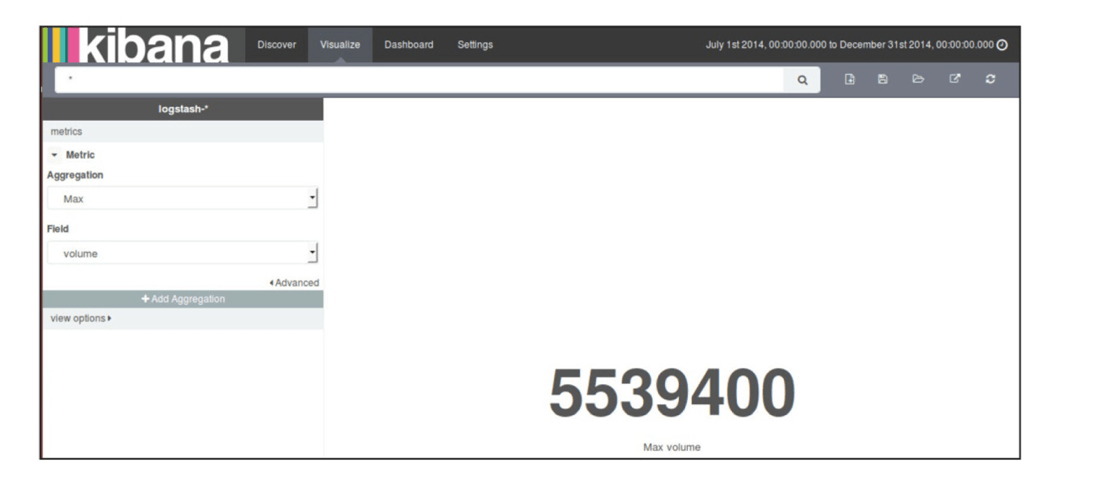
- 用度量显示过去六个月每天的单日最高交易量
- 点击可视化菜单中的度量,选择度量的聚合函数为
Max,字段为volume,然后点击应用
构建数据表
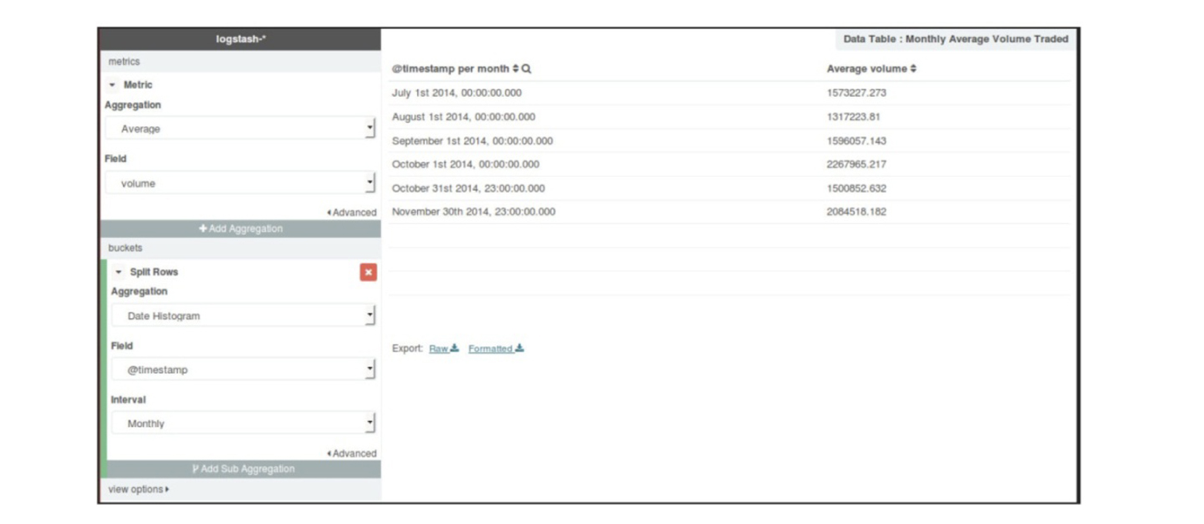
- 数据表以表格的形式显示某些组合聚合结果的详细数据
- 创建一个六个月内的月度平均成交量的数据表
- 在可视化菜单中的数据表,点击拆分行(
split rows),选择度量值 的聚合函数为求平均值 (Average),字段为volume。在桶的区域,选择聚合函数为基于@timestamp字段的日期直方图,间隔为月度(Monthly)
- 在页面的顶部选择仪表盘页面链接,点击增加可视化(
Add Visualization)链接,选择已保存的可视化组件并在仪表盘页面上进行布局 - 下图是一个包含了折线图、柱状图、数据表和度量值 的仪表盘
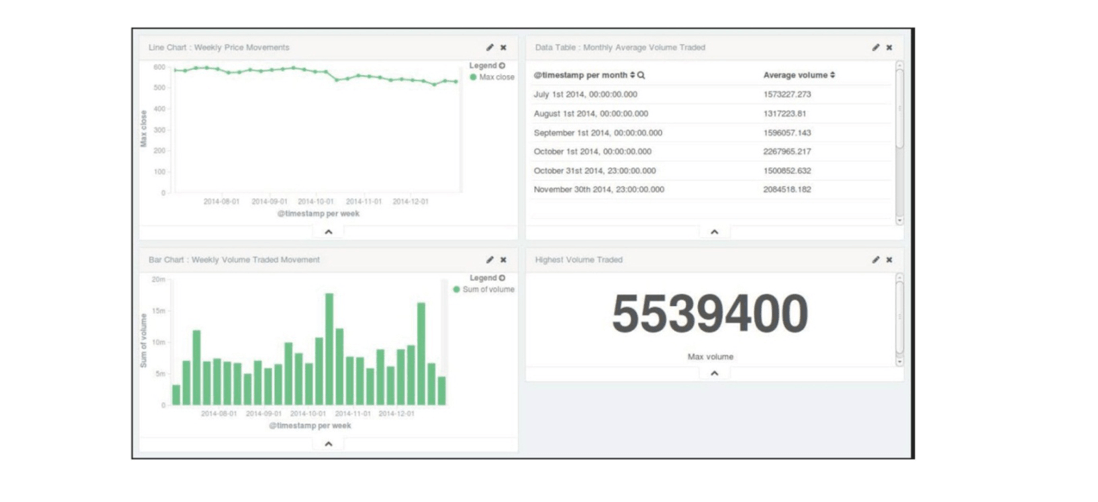
- 仪表板可在其他系统里作为内嵌框架,或者直接以链接的形式分享
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



