
《Learning ELK Stack》3 使用Logstash采集、解析和转换数据
0 / 0 / 创建于 6年前
 yeedomliu 的个人博客
yeedomliu 的个人博客
3 使用Logstash采集、解析和转换数据
- 理解
Logstash如何采集、解析并将各种格式和类型的数据转换成通用格式,然后被用来为不同的应用构建多样的分析系统
配置Logstash
- 输入插件将源头数据转换成通用格式的事件,过滤插件修改这些事件,最终输出插件将它们输出到其他系统

Logstash插件
列出Logstash的所有插件
bin/plugin list- 使用下面命令列出指定分组的插件
bin/plugin list --group <group_name>
bin/plugin list --group output插件属性的数据类型
数组(Array)
path => ["value1", "value2"]布尔值(Boolean)
periodic_flush => false编解码器(Codec)
- 编解码器实际上并不是一种数据类型,它是在输入或输出的时候对数据进行解码或编码的一种方式。上面例子指定在输出时,编解码器会将所有输出数据编码成
json格式
codec => "json"哈希(Hash)
- 由一系列键值对组成的集合
match => {
"key1" => "value1", "key2" => "value2"
}字符串(String)
value => "welcome"注释(Comment)
- 以字符#开头
# 这是一个注释字段引用
- 可使用[
field_name]的方式引用,嵌套字段可以使用[level1][level2]的方式指定
Logstash条件语句
- 在某些条件下
Logstash可以用条件语句来过滤事件或日志记录。Logstash中的条件处理和其他编程语言中的类似,使用if、if else和else语句。多个if else语句块可以嵌套
if <conditional expression1> {
# 一些处理语句
}
else if <conditional expression2> {
# 一些处理语句
}
else {
# 一些其他语句
}- 条件语句可以与比较运算符、逻辑运算符和单目运算符一起使用
- 比较运算符包括以下几种
- 相等运算符:==、!=、<、>、<=、>=
- 正则表达式:=
、! - 包含:
in、not in - 逻辑运算符:
and、or、nand、xor - 单目运算符:!
filter {
if [action] == "login" {
mutate { remove => "password" }
}
}output {
if [loglevel] == "ERROR" and [deployment] == "production" {
email {}
}
}Logstash插件的类型
- 输入(
Input) - 过滤器(
Filter) - 输出(
Output) - 编解码(
Codec)
输入插件
文件(file)
Logstash文件输入插件将文件读取的最新位点保存在$HOME/.sincdb*的文件中。文件路径和刷新频率可以通过sincedb_path和sincdb_write_interval配置
input {
file {
path => "/GOOG.csv"
add_field => {"input_time" => "%{@timestamp}"}
codec => "json"
delimiter => "\n"
exclude => "*.gz"
sincedb_path => "$HOME/.sincedb*"
sincedb_write_interval => 15
start_position => "end"
tags => ["login"]
type => ["apache"]
}
}| 选项 | 数据类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
add_field |
hash |
否 | {} | 增加字段 |
codec |
string |
否 | plain |
用于指定编解码器输入 |
delimiter |
string |
否 | `n ` | 分隔符 |
exclude |
array |
否 | [] | 排除指定类型文件 |
sincedb_path |
string |
否 | $HOME/.sincedb |
监视文件当前读取位点 |
sincedb_write_interval |
int |
否 | 15 | 指定sincedb文件写入频率 |
start_position |
string |
否 | end |
输入文件的初始读取位点 |
tags |
array |
否 | 给输入事件增加一系列标签 | |
type |
string |
否 | 给多个输入路径中配置的不同类型的事件指定type名称 |
|
path |
array |
是 | 日志文件路径 |
input {
file {
path => ["/var/log/syslog/*"]
type => "syslog"
}
file {
path => ["/var/log/apache/*"]
type => "apache"
}
}
filter {
if [type] == "syslog" {
grok{}
}
if [type] == "apache" {
grok{}
}
if "login" == tags[] {}
}
Redis
- 从
redis实例中读取事件和日志。经常用于输入数据的消息代理,将输入数据缓存到队列,等待索引器读取日志
| 选项 | 数据类型 | 是否必选 | 默认值 | 说明 |
|---|---|---|---|---|
add_field |
hash |
否 | {} | 增加字段 |
codec |
string |
否 | plain |
用于指定编解码器输入 |
data_type |
string |
否 | list |
list(BLPOP)、channel(SUBSCRIBE命令订阅key)、pattern_channel(PSUBSCRIBE命令订阅key) |
host |
string |
否 | 127.0.0.1 | |
key |
string |
否 | ||
password |
string |
否 | ||
port |
int |
否 | 6379 |
输出
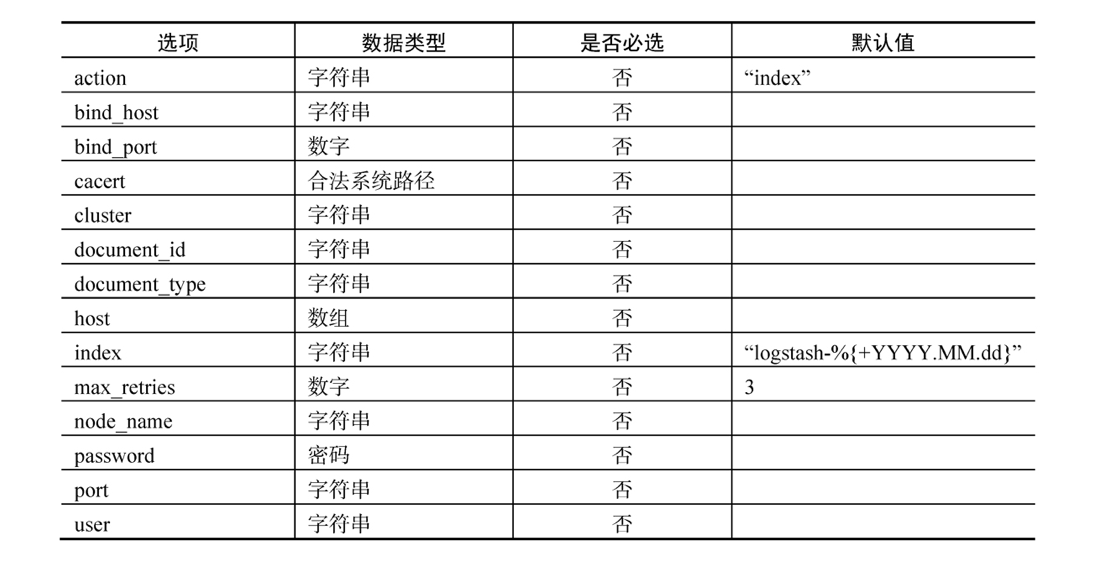
elasticsearch
- 最重要的输出插件
过滤器
- 用于在输出插件输出结果之前,对输入插件中读取的事件进行中间处理。常用于识别输入事件的字段,并对输入事件的部分内容进行条件判断处理
csv
- 用于将
csv文件输入的数据进行解析,并将值赋给字段
csv {
columns => ["date_of_record","open","high","low","close","volume","adj_close"]
separator => ","
}date
- 给事件赋予正确的时间戳非常重要,只有这样才能在
Kibana中使用时间过滤器对事件进行分析
date {
match => ["date_of_record", "yyyy-MM-dd"]
}drop
- 将满足条件的所有事件都丢弃掉,这个过滤插件有下面这些配置选项
add_fieldadd_tagremove_fieldremove_tag
filter {
if [fieldname == "test"] {
drop {}
}
}geoip
- 基于输入事件中的
IP地址给事件增加地理位置信息。这些信息从Maxmind数据库中读取
Maxmind是一个专门提供IP地址信息产品的公司。GeoIP是它们开发的智能IP产品,用于IP地址的位置跟踪。所有Logstash版本都自带一个Maxmind的GeoLite城市数据库。这个地址数据库可以从https://dev.maxmind.com/geoip/geoip2/geolite2/获取
geoip {
source => # 必选字符串,需要使用geoip服务进行映射的ip地址或主机名
}grok
- 目前为止最流行、最强大的插件。使用它可以解析任何非结构化的日志事件,并将日志转化成一系列结构化的字段,用于后续的日志处理和分析
- 可以用于解析任何类型的日志,包括
apache、mysql、自定义应用日志或者任何事件中非结构化的文本 Logstash默认包含了很多grok模式,可以直接用来识别特定类型的字段,也支持自定义正则表达式- 所有可用
grok模式从这里获取:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)
DAY (?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?)
YEAR (?>\d\d){1,2}
HOUR (?:2[0123]|[01]?[0-9])
MINUTE (?:[0-5][0-9])- 上面
grok模式可以使用下面这样的操作符直接识别这些类型的字段。希望将日志事件中代表主机名的文本赋值给host_name这个字段
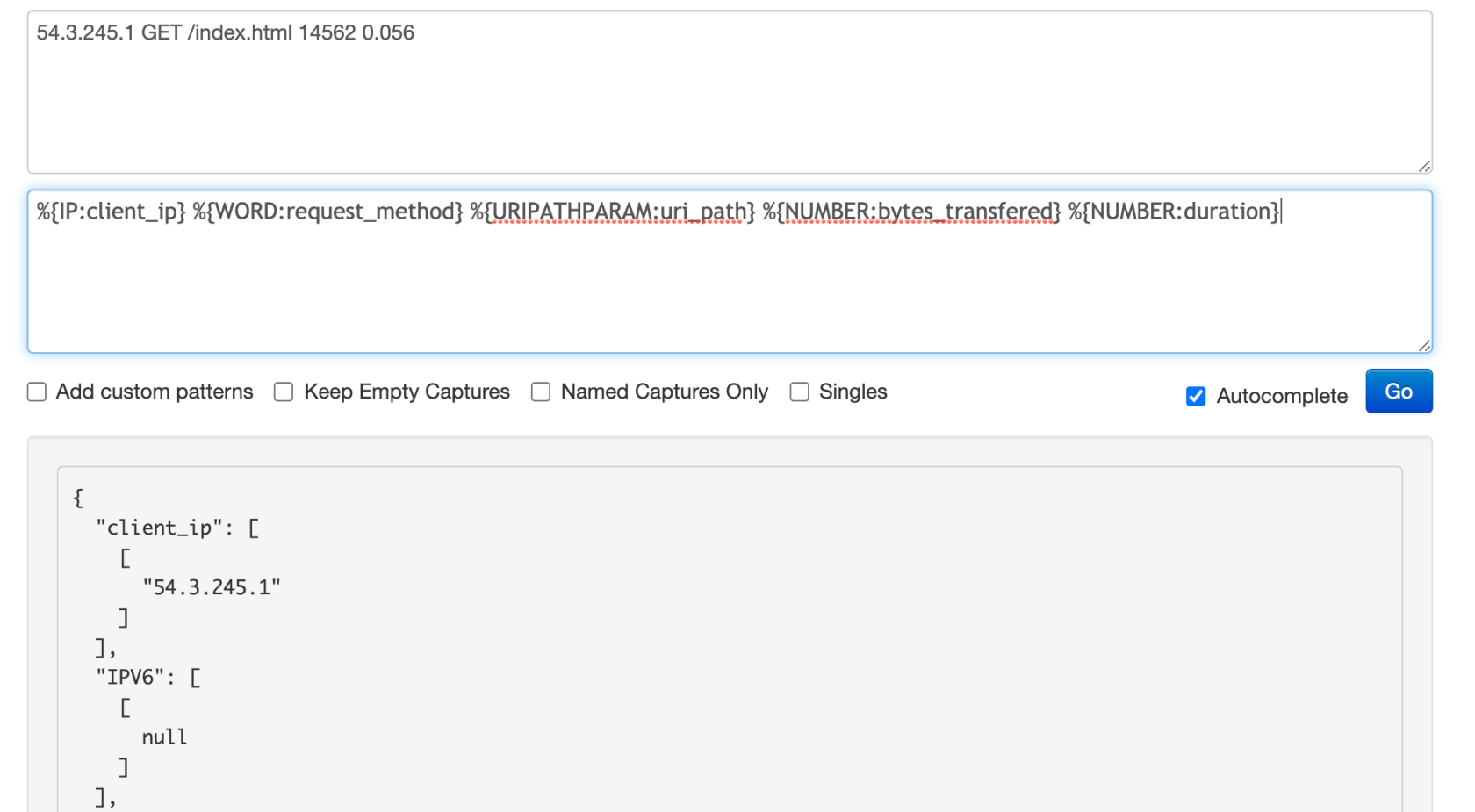
%{HOSTNAME:host_name}- 看一下如何用
grok模式表示一行HTTP日志
54.3.245.1 GET /index.html 14562 0.056grok模式是这样的
%{IP:client_ip} %{WORD:request_method} %{URIPATHPARAM:uri_path} %{NUMBER:bytes_transfered} %{NUMBER:duration}filter {
grok {
match => { "message" => "%{IP:client_ip} %{WORD:request_method} %{URIPATHPARAM:uri_path} %{NUMBER:bytes_transfered} %{NUMBER:duration}" }
}
}- 使用
grok过滤器处理上面的事件后,可以看到事件中增加了如下字段和值
client_ip:54.3.245.1request_method:GETuri_path:/index.htmlbytes_transferred:14562duration:0.056
- 如果
grok模式中没有需要的模式,可以使用正则表达式创建自定义模式
设计和测试grok模式
mutate
- 对输入事件进行重命名、移除、替换和修改字段。也用于转换字段的数据类型、合并两个字段、将文本从小写转换为大写等

sleep
- 将
Logstash置于sleep模式,时间由参数指定,也可以基于事件指定sleep频率 - 如果希望每处理五个事件就
sleep一秒,可以这样配置
filter {
sleep {
time => "1"
every => 5
}
}编解码
- 用于对输入事件进行解码,对输出事件进行解码,以流式过滤器的形式在输入插件和输出插件中工作,重要的编解码插件包括
avrojsonlinemultilineplainrubydebugspool
输入事件或输出事件是完整的json文档,可以这样配置(其中一种方式就可以)
input {
stdin { codec => "json" }
stdin { codec => json{} }
}将每行输入日志作为一个事件,将每个输出事件解码成一行
input {
stdin { codec => line{} }
stdin { codec => "line" }
}把多行日志作为一个事件处理
input {
file {
path => "/var/log/someapp.log"
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601}"
negate => true
what => previous
}
}
}rubydebug在输出事件时使用,使用Ruby Awesome打印库打印输出事件
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



