
《Learning ELK Stack》5 为什么需要Elasticsearch
0 / 0 / 创建于 6年前 /
 yeedomliu 的个人博客
yeedomliu 的个人博客
5 为什么需要Elasticsearch
为什么是Elasticsearch
es是一种在分布式环境中快速、可扩展的搜索和分析引擎。它建立在Apache Lucene上。Lucene定义如下
Apache Lucene是一种高性能、全功能的完全用java写的广西搜索引擎库。它是一种几乎适合于任何需要全文搜索,特别是跨平台的应用程序的技术
Elasticseaarch通过提供强大的RESTful API隐藏了Lucene背后的复杂性,使得查询索引数据更容易,并使其适用于任何编程语言。Elasticsearch可以基于PB级别的结构化或者非结构化数据建立跨多台服务器的分布式实时分析,这大大扩展了Lucene的能力
Elasticsearch的基本概念
索引
- 索引是具备某些共同特征的文档集
- 每一个索引包含多个类型,每个类型相应的包含多个文档,每个文档又包含多个字段。在
es中,一个索引包含多个JSON格式的文档。在es集群中的数量可以是任意的 - 在
ELK中,将Logstash的JSON文档发送到es时,它们被存储为默认的索引模式”logstash-%{+YYYY.MM.dd}” - 搜索和查询索引的
URL看起来如下
文档
es中的文档是指存储在索引里的JSON格式的文档。每一个文档都有一个类型和相应的唯一标识(ID)。例如,存储在es的文档看起来如下

字段
- 字段是文档内的基本单,基本字段是如下键值对
book_name : “learning elk”
类型
- 用于提供索引中的逻辑分区。它基本上代表一类类似的文档类型。一个索引可以有多个类型,可以根据上下文来定义它们。如,
Facebook的索引中可以使用post作为一种索引类型,使用comments作为另一种索引类型
映射
- 用来映射文档的每个字段,以及字段对应的数据类型,如
string、integer、float、double等
分片
- 存储索引的实际物理实体。每个索引可以有多个存储数据的主分片和副本分片。分片分布在集群的所有节点之间,并且在有节点失效或新节点加入时,可以从一个节点移动到另一节点
主分片和副本分片
- 索引文件先存储在主分片中,然后再存储到相应的副本分片中。默认情况下,每个索引的主分片数量是5,当然我们也可以根据需要自行配置
- 副本分片通常与主分片驻留在不同的节点上,以便于满足多个请求情况下的故障转移和负载均衡
集群
- 存储索引数据的节点集合。将数据存储在集群中来提供水平扩展能力。每个集群都有一个集群名称来表示,以便不同的节点辨识连接。集群名称在
elasticsearch.yml配置文件中名为cluster.name的属性配置,默认为Elasticsearch: cluster.name: elasticsearch
节点
- 是一个单一的
Elasticsearch运行实例,属于某个集群。节点可以扮演三种角色
数据节点:用于索引文档,以及对这些文档执行搜索操作。如果要提升性能或者扩展集群,通常建议添加更多的数据节点。在elasticsearch.yml配置文件设置节点属性就可以将节点变成数据节点
node.master = false
node.data = true主节点:负责集群的管理。对于大集群,建议有三个专用的主节点(一主两备),它们只作为主节点,不存储索引或执行搜索。配置如下
node.master = true
node.data = false路由节点或负载均衡节点:既不作为主节点也不担当数据节点角色。只用于负载均衡,或路由搜索请求,又或将文档索引到适当的节点。这对于高负荷的搜索或索引操作非常有用
node.master = false
node.data = false探索Elasticsearch API
- 查询集群
API常见语法
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>/<OPERATION_NAME>?<QUERY_STRING>' -d '<BODY>'VERB:请求方法类型,包括GET/POST/PUT/DELETE/HEAD
PROTOCOL:协议类型,http/https
HOST:集群中主机名
PORT:es实例运行的端口,默认是9200
PATH:索引名、类型和要查询的文档ID,例如:/index/type/id
OPERATION_NAME:执行操作的名称,例如:_search,_count等
QUERY_STRING:查询参数中指定可选参数。如?pretty用于完美输出json文档
BODY:用于请求正文文本
curl -XGET 'http://localhost:9200/logstash-2020.08.08/_search?pretty'列出所有可用索引
- 显示存储在集群的节点所有索引、索引相关信息,如健康值 、索引名称、大小、文档的数量、主分片的数量等等
curl -XGET 'localhost:9200/_cat/indices?v'列出集群中的所有节点
curl -XGET 'http://localhost:9200/_cat/nodes?v'检查集群的健康状态
curl -XGET 'http://localhost:9200/_cluster/health?pretty'- 从集群层面、分片层面,或者索引层面来检查健康状态,使用类似如下的
URL即可
curl -XGET 'http://localhost:9200/_cluster/health?level=cluster&pretty=true'
curl -XGET 'http://localhost:9200/_cluster/health?level=shareds&pretty=true'
curl -XGET 'http://localhost:9200/_cluster/health?level=indices&pretty=true'集群的健康状态由三个参数表示
- 红色:部分或全部的主分片尚未准备好提供服务
- 黄色:所有的主分片已成功分配,但部分或全部的分片尚未分配。一般情况下,单节点集群始终是黄色的健康状态,因为没有副本分片节点
- 绿色:所有的主分片和副本分片分配成功,并且集群正常动作
创建索引
- 在
ELK中,索引是根据在Logstash的es输出插件中提供的索引名称自动创建的。尽管如此,还是来看一下如何手工创建索引
curl -XPUT 'http://localhost:9200/<index_name>?pretty'- 假如要创建一个名为
packtpub的索引,可以执行以下命令
curl -XPUT 'http://localhost:9200/packtpub?pretty'- 还可以在往索引内写入文档的同时,直接创建索引
curl -XPUT 'http://localhost:9200/packtpub/elk/1?pretty' -d '
{
book_name : "learning elk"
}'- 执行命令后的返回结果如下
{
"_index" : "packtpub",
"_type" : "elk",
"_id" : "1",
"_version" : 1,
"created" : true
}检索文档
curl -XGET 'http://localhost:9200/packtpub/elk/1?pretty'- 执行以上命令后的返回结果如下
{
"_index" : "packtpub",
"_type" : "elk",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
book_name : "learning elk"
}
}- _
source字段包含了完整的文档
删除文档
curl -XDELETE 'http://localhost:9200/packtpub/elk/1?pretty'- 返回如下
{
"acknowledged" : true
}Elasticsearch Query DSL
es查询语句的强大之处在于,其是一个基于json的领域特定语言,称为Query DSL。Kibana为了得到特定格式的结果,广泛使用了Query DSL
curl -XPOST 'http://localhost:9200/logstash-*/_search' -d '
{
"query" : { "match_all" : {} },
"size" : 3
}'- 如果按照某个字段进行排序的话,可以如下处理
curl -XPOST 'http://localhost:9200/logstash-*/_search' -d '
{
"query" : { "match_all" : {} },
"sort" : { "open" : { "order" : "desc" } },
"size" : 3
}'更详细的Query DSL相关资料请参考官方文档
Elasticsearch插件
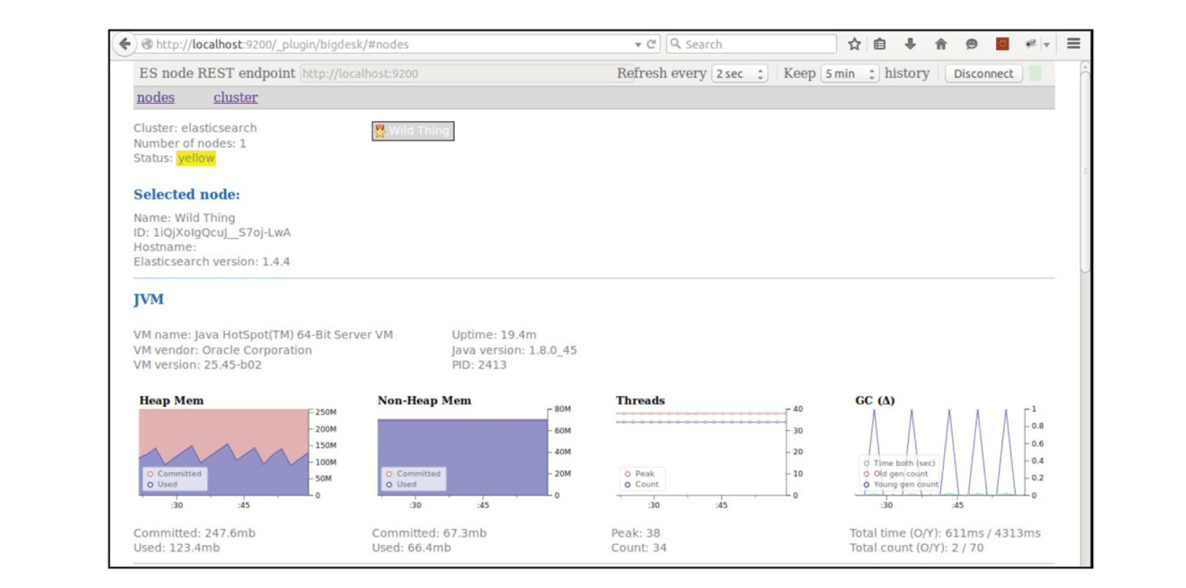
Bigdesk插件
- 借助于实时图表和
JVM、CPU、OS、主分片以及副本分片相关的各种统计信息,有助于分析集群节点信息
Elastic-Hammer插件
- 可作为
es的前端界面。可用于查询集群,并在输入查询语句时提供语法检查
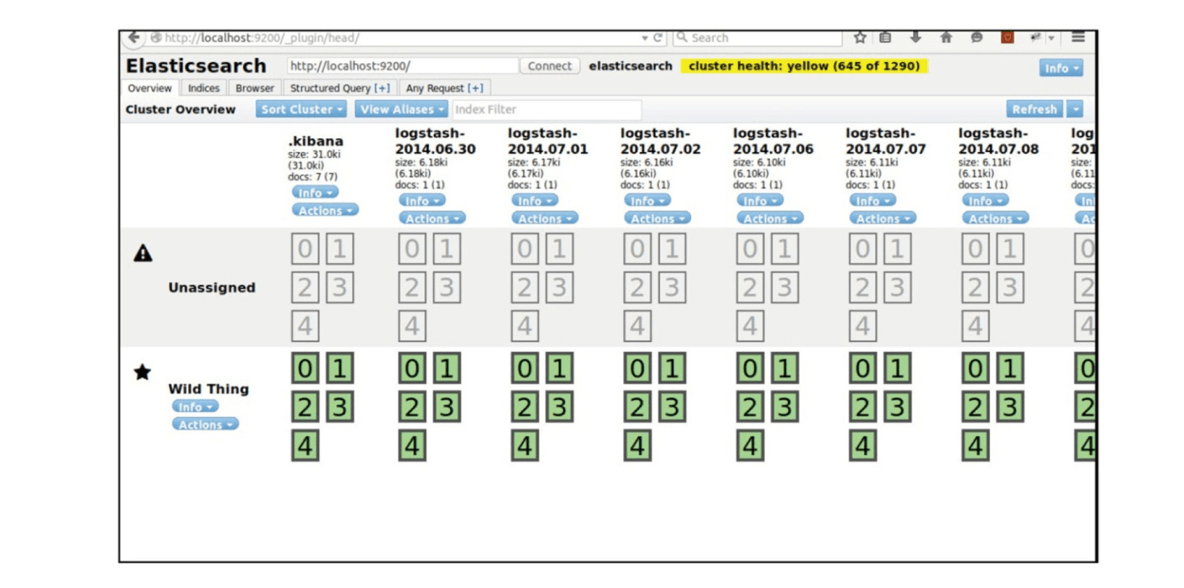
Head插件
- 能够生成集群的统计数据,并提供浏览器查询,同时还能对
es索引进行结构化查询
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



