
网站爬取时出现乱码该怎么办?本人以py的request来开始讲解.包括了分析乱码的由来与奥秘
0 / 0 / 创建于 5年前
 wangchunbo 的个人博客
wangchunbo 的个人博客
本人代码实际测试
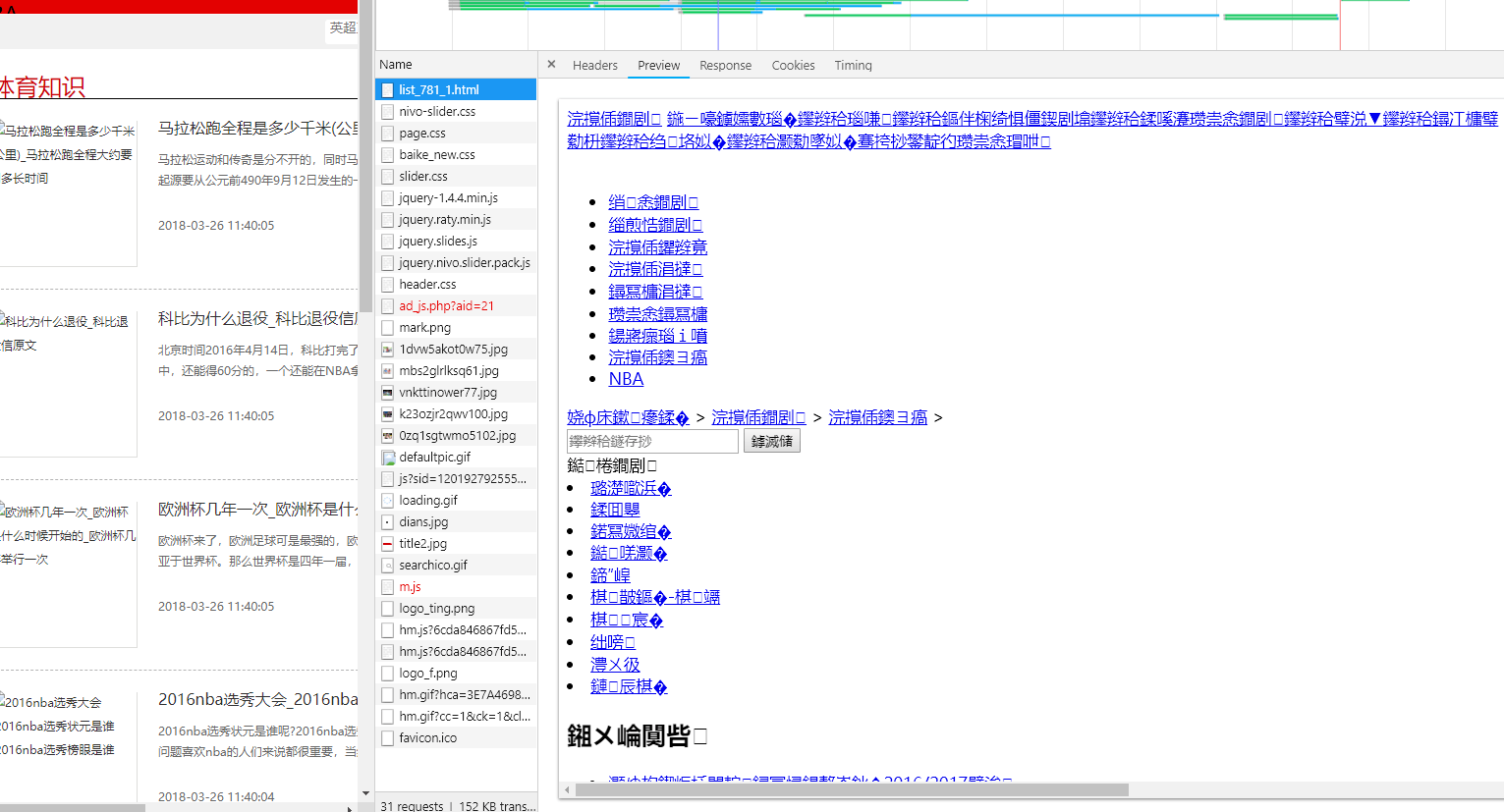
通过 request 的get 请求某目标页面,发现中文全部乱码
网页显示:
命令行显示: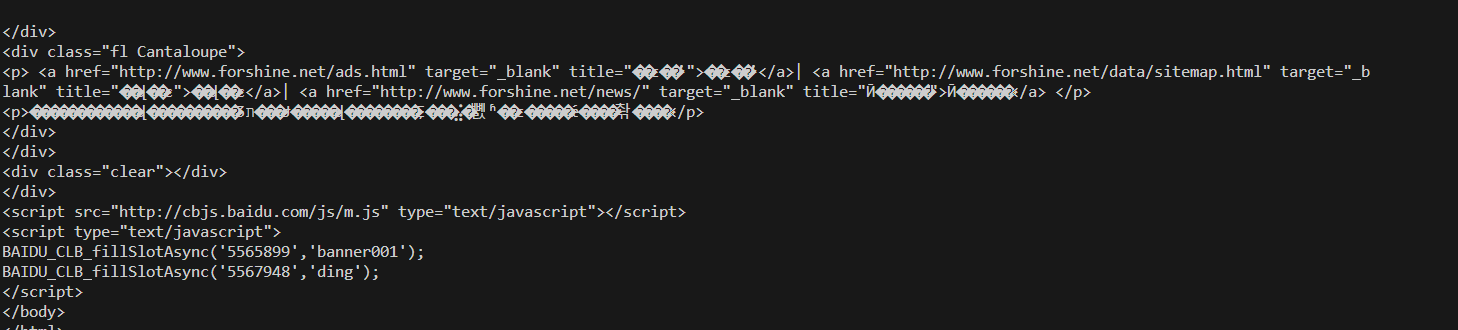
来查看一下网页返回的字符集类型
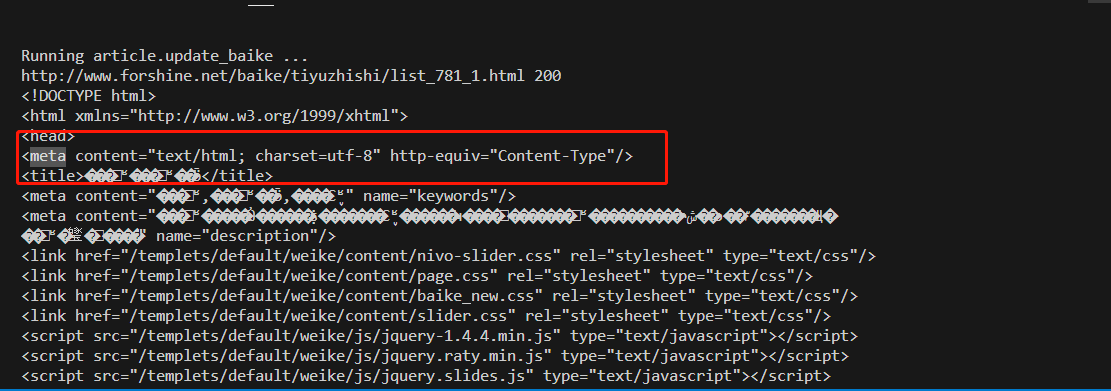
老硬币了,这里显示utf8
通过request 返回的属性来看
print(resp.encoding) #查看网页返回的字符集类型
print(resp.apparent_encoding) #自动判断字符集类型

发现问题!
接下来的我们就进行编码解码来搞他
def get(url, transform):
resp = requests.get(url, timeout=10)
print(resp.url, resp.status_code)
print(resp.encoding) #查看网页返回的字符集类型 这里返回ISO-8859
print(resp.apparent_encoding) #自动判断字符集类型 发现这里返回 GB2312! 我们进行转换gbk
html = resp.text.encode('iso-8859-1').decode('gbk')
print('html: ', html)搞定,可以继续爬虫了.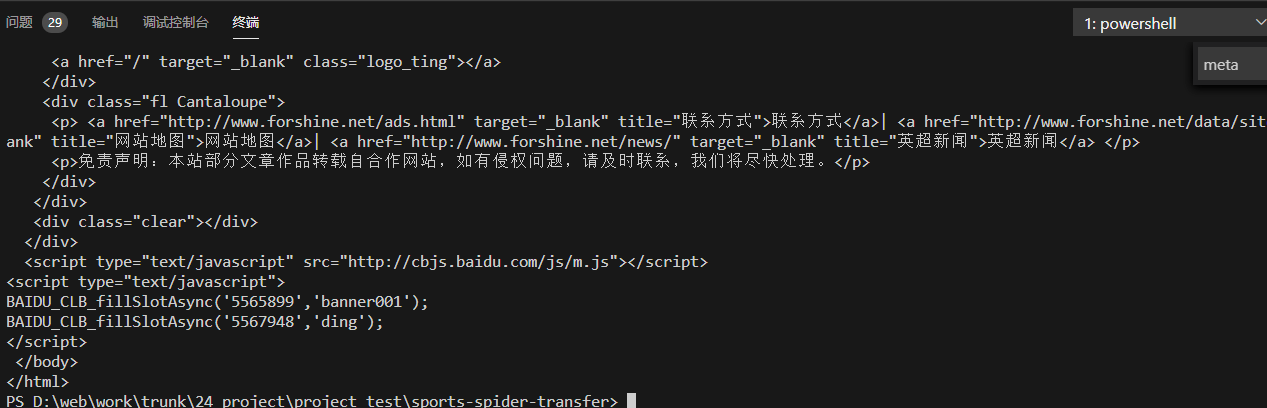
乱码问题的由来
关于网络爬虫的乱码处理。注意,这里不仅是中文乱码,还包括一些如日文、韩文 、俄文、藏文之类的乱码处理,因为他们的解决方式 是一致的,故在此统一说明。
一、乱码问题的出现
就以爬取51job网站举例,讲讲为何会出现“乱码”问题,如何解决它以及其背后的机制。
代码示例:
import requests
url = “http://search.51job.com"
res = requests.get(url)
print(res.text)
显示结果:
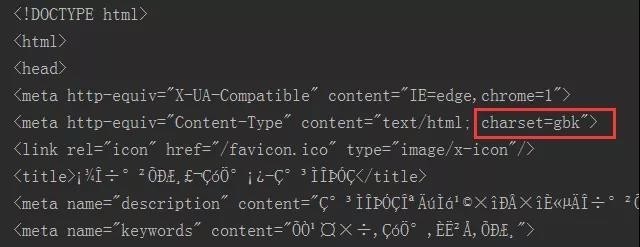
打印res.text时,发现了什么?中文乱码!!!不过发现,网页的字符集类型采用的gbk编码格式。
我们知道Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 r.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用r.encoding 属性来改变它。
接下来,我们一起通过resquests的一些用法,来看看Requests 会基于 HTTP 头部对响应的编码方式。
print(res.encoding) #查看网页返回的字符集类型
print(res.apparent_encoding) #自动判断字符集类型
输出结果为:

可以发现Requests 推测的文本编码(也就是网页返回即爬取下来后的编码转换)与源网页编码不一致,由此可知其正是导致乱码原因。
乱码背后的奥秘
当源网页编码和爬取下来后的编码转换不一致时,如源网页为gbk编码的字节流,而我们抓取下后程序直接使用utf-8进行编码并输出到存储文件中,这必然会引起乱码,即当源网页编码和抓取下来后程序直接使用处理编码一致时,则不会出现乱码,此时再进行统一的字符编码也就不会出现乱码了。最终爬取的所有网页无论何种编码格式,都转化为utf-8格式进行存储。
注意:区分源网编码A-gbk、程序直接使用的编码B-ISO-8859-1、统一转换字符的编码C-utf-8。
在此,我们拓展讲讲unicode、ISO-8859-1、gbk2312、gbk、utf-8等之间的区别联系,大概如下:
最早的编码是iso8859-1,和ascii编码相似。但为了方便表示各种各样的语言,逐渐出现了很多标准编码。iso8859-1属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。
1981年中国人民通过对 ASCII 编码的中文扩充改造,产生了 GB2312 编码,可以表示6000多个常用汉字。但汉字实在是太多了,包括繁体和各种字符,于是产生了 GBK 编码,它包括了 GB2312 中的编码,同时扩充了很多。中国又是个多民族国家,各个民族几乎都有自己独立的语言系统,为了表示那些字符,继续把 GBK 编码扩充为 GB18030 编码。每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。终于,有个叫 ISO 的组织看不下去了。他们一起创造了一种编码 UNICODE ,这种编码非常大,大到可以容纳世界上任何一个文字和标志。所以只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编码就可以被其他电脑正常解释。UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8个位和 16个位。于是就会有人产生疑问,UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间比较多,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以。
也可以这样来理解:字符串是由字符构成,字符在计算机硬件中通过二进制形式存储,这种二进制形式就是编码。如果直接使用 “字符串↔️字符↔️二进制表示(编码)” ,会增加不同类型编码之间转换的复杂性。所以引入了一个抽象层,“字符串↔️字符↔️与存储无关的表示↔️二进制表示(编码)” ,这样,可以用一种与存储无关的形式表示字符,不同的编码之间转换时可以先转换到这个抽象层,然后再转换为其他编码形式。在这里,unicode 就是 “与存储无关的表示”,utf—8 就是 “二进制表示”。
乱码的解决方法
根据原因来找解决方法,就非常简单了。
方法一:直接指定res.encoding
import requests
url = "http://search.51job.com"
res = requests.get(url)
res.encoding = "gbk"
html = res.text
print(html)方法二:通过res.apparent_encoding属性指定
import requests
url = "http://search.51job.com"
res = requests.get(url)
res.encoding = res.apparent_encoding
html = res.text
print(html)方法三:通过编码、解码的方式
import requests
url = "http://search.51job.com"
res = requests.get(url)
html = res.text.encode('iso-8859-1').decode('gbk')
print(html)输出结果:
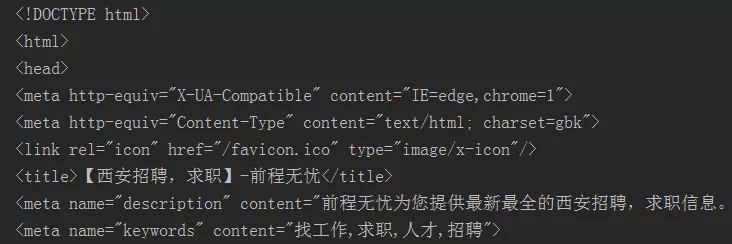
基本思路三步走:确定源网页的编码A—gbk、程序通过编码B—ISO-8859-1对源网页数据还原、统一转换字符的编码C-utf-8。至于为啥为出现统一转码这一步呢? 网络爬虫系统数据来源很多,不可能使用数据时,再转化为其原始的数据,假使这样做是很废事的。所以一般的爬虫系统都要对抓取下来的结果进行统一编码,从而在使用时做到一致对外,方便使用。
比如如果我们想讲网页数据保存下来,则会将起转为utf-8,代码如下:
with open("a.txt",'w',encoding='utf-8') as f:
f.write(html)
参考文章: www.sohu.com/a/289375951_420744
本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: