
Java基础——序列化
0 / 1 / 创建于 5年前 /
 it_was 的个人博客
it_was 的个人博客
1.为什么序列化?
引自《Java 编程思想》
当创建对象时,在程序运行期间可以获取,但是程序终止时,所有的对象都会被清除,我们是无法再获取的。当然,你可以通过将信息写入文件或者数据库来达到目的。但是为了更方便,Java为我们提供了序列化机制,并且屏蔽了大部分细节。 ——Bruce Eckel
Java提供序列化作用:
- Java的远程方法调用-RMI。
- Java Beans的使用。
2.什么是序列化?
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
3. 如何序列化?
2.1 序列化机制一: Serializable 接口
Serializable接口是最简单的实现序列化的方式,如果类实现了Serializable接口,那么就可以表明该类的对象可被序列化!否则就会报错。常见的默认实现该接口的有所有基本类型的封装类型,String,容器类甚至Class 对象!
//可以看到源码中Serializable接口内部没有任何东西,只是一个标识!
public interface Serializable {
//nothing!
}
序列化与反序列化方法:调用 ObjectOutputStream 和 ObjectInputStream 
package ddx.序列化;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person = new Person(18,"ddx");
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.out") );
out.writeObject("person storage\n");
out.writeObject(person);
out.close();
System.out.print("序列化"+"person storage\n"+ person);
ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.out"));
String title = (String)in.readObject(); //注意反序列化顺序与序列化顺序保持一致
Person person1 = (Person) in.readObject();
in.close();
System.out.print("反序列化"+title+ person1);
}
}
class Person implements Serializable{
public int age;
public String name;
Person(int age , String s){
this.age = age;
this.name = s;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
运行结果
序列化person storage
Person{age=18, name='ddx'}
反序列化person storage
Person{age=18, name='ddx'}输出文件
注意点:再强调一下,对象序列化的主体是成员变量,而不包括静态变量 一个类序列化,另一个类反序列化,分别执行!
一个类序列化,另一个类反序列化,分别执行!
ackage ddx.序列化;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person = new Person(18,"ddx");
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.out") );
out.writeObject("person storage\n");
out.writeObject(person);
out.close();
System.out.println("序列化"+"person storage\n"+ person);
}
}
class Person implements Serializable{
public int age;
public String name;
public static int count = 0;
Person(int age , String s){
this.age = age;
this.name = s;
count++;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
",count='"+count+'\'' +
'}';
}
}package ddx.序列化;
import java.io.*;
public class test {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.out"));
String title = (String) in.readObject();
Person person1 = (Person) in.readObject();
in.close();
System.out.println("反序列化" + title + person1);
}
}
序列化person storage
Person{age=18, name='ddx',count='1'}
反序列化person storage
Person{age=18, name='ddx',count='0'}
//通过以上输出可以发现序列化不对静态变量做任何操作,只会保留初始值!!!!2.2 Serializable 的序列化规则
使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。这种情况被称为对象网所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
2.3 Externalizable接口
Externalizable继承于Serializable,当使用该接口时,序列化的细节需要由程序员去完成。
两者的区别除了上面需要手动完成还包括下面这点:
- 使用Serializable接口的对象反序列化恢复对象时,是完全以存储它的二进制位构造的
- 而使用Externalizable 接口的对象反序列化恢复对象时,必须至少要有一个默认的公共的构造函数!!!!然后调用readExternal方法!
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException,ClassNotFoundException;
}演示代码:
package ddx.序列化;
import java.io.*;
public class Main1 {
public static void main(String[] args ) throws IOException, ClassNotFoundException {
info info1 = new info(10,"ddx");
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("info.out"));
out.writeObject(info1);
System.out.println("序列化之前\n"+info1);
out.close();
ObjectInputStream in = new ObjectInputStream(new FileInputStream("info.out"));
info info2 = (info) in.readObject();
System.out.println("序列化之后\n"+info2);
}
}
class info implements Externalizable{
public int id;
public String name;
public info(int id, String name){
this.id = id;
this.name = name;
System.out.println("info正在执行带参构造函数");
}
public info(){
System.out.println("info正在执行无参构造函数");
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeInt(this.id);
out.writeObject(name);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
//1
//in.readInt();
//in.readObject();
id = in.readInt();
name = (String)in.readObject();
}
@Override
public String toString() {
return "info{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}2.4 transient 关键字
使用transient关键字选择不需要序列化的字段。比如一些敏感的私有的信息,可以选择使用改关键字,虚拟机会忽略该字段!!!
package ddx.序列化;
import java.io.*;
public class Main2 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Message message = new Message(201792237,533534);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("Self_Message.out"));
out.writeObject(message);
out.close();
System.out.println("序列化之前" + message);
ObjectInputStream in = new ObjectInputStream(new FileInputStream("Self_Message.out"));
Message message1 = (Message) in.readObject();
System.out.println("序列化之后" + message1);
}
}
class Message implements Serializable {
private int id;
private transient int password; //transient 关键字修饰!!!
Message(int id, int password){
this.id = id;
this.password = password;
}
@Override
public String toString() {
return "message{" +
"id=" + id +
", password=" + password +
'}';
}
}序列化之前message{id=201792237, password=533534}
序列化之后message{id=201792237, password=0}从输出我们看到,使用transient修饰的属性,java序列化时,会忽略掉此字段,所以反序列化出的对象,被transient修饰的属性是默认值。对于引用类型,值是null;基本类型,值是0;boolean类型,值是false。
2.5 序列化持久性
同一对象序列化多次,会将这个对象序列化多次吗?答案是否定的。
package ddx.序列化;
import java.io.*;
public class Main3 {
public static void main(String[] args) throws Exception {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("teacher.txt"))) {
Person person = new Person(20,"路飞");
Teacher t1 = new Teacher("雷利", person);
Teacher t2 = new Teacher("红发香克斯", person);
//依次将4个对象写入输入流
oos.writeObject(person);
oos.writeObject(t1);
oos.writeObject(t2);
oos.writeObject(t2);//重复序列化同一个对象!!!!!!
oos.close();
ObjectInputStream in = new ObjectInputStream(new FileInputStream("teacher.txt"));
Person p = (Person) in.readObject();
Teacher tt1 = (Teacher)in.readObject();
Teacher tt2 = (Teacher)in.readObject();
Teacher tt3 = (Teacher)in.readObject();
System.out.println(p);
System.out.println(tt1);
System.out.println(tt2);
System.out.println(tt3);
}
}
}
class Teacher implements Serializable{
public String name;
public Person person;
Teacher(String name, Person person){
this.name = name;
this.person = person;
}
@Override
public String toString() {
return "Teacher{" +super.toString()+
"name='" + name + '\'' +
", person=" + person +
'}';
}
}
正在初始化
ddx.序列化.Person@6f496d9f
Teacher{ddx.序列化.Teacher@723279cf name='雷利', person=ddx.序列化.Person@6f496d9f}
Teacher{ddx.序列化.Teacher@10f87f48 name='红发香克斯', person=ddx.序列化.Person@6f496d9f}
Teacher{ddx.序列化.Teacher@10f87f48 name='红发香克斯', person=ddx.序列化.Person@6f496d9f}
//可以发现person并没有被多次序列化,而t2也只被序列化了一次!!!地址都相同!从输出结果可以看出,Java序列化同一对象,并不会将此对象序列化多次得到多个对象。
Java序列化算法
- 所有保存到磁盘的对象都有一个序列化编码号
- 当程序试图序列化一个对象时,会先检查此对象是否已经序列化过,只有此对象从未(在此虚拟机)被序列化过,才会将此对象序列化为字节序列输出。
- 如果此对象已经序列化过,则直接输出编号即可。
图示上述序列化过程(顺序不同!原理一致)

4.版本控制
我们知道,反序列化必须拥有class文件,但随着项目的升级,class文件也会升级,序列化怎么保证升级前后的兼容性呢?
java序列化提供了一个private static final long serialVersionUID 的序列化版本号,只有版本号相同,即使更改了序列化属性,对象也可以正确被反序列化回来。
public class Person implements Serializable {
//序列化版本号
private static final long serialVersionUID = 1111013L;
private String name;
private int age;
//省略构造方法及get,set
}如果反序列化使用的class的版本号与序列化时使用的不一致,反序列化会报InvalidClassException异常。
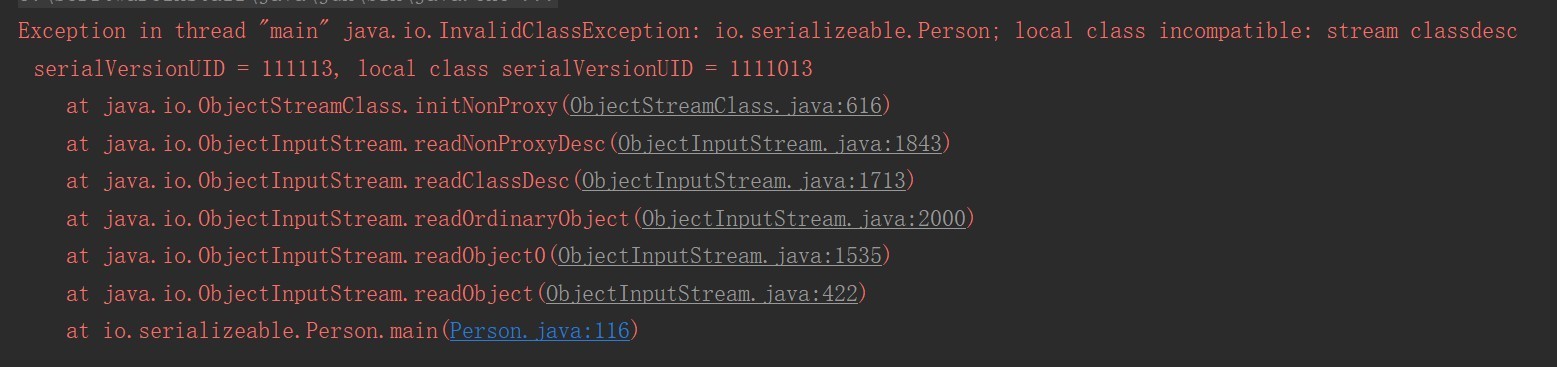
序列化版本号可自由指定,如果不指定,JVM会根据类信息自己计算一个版本号,这样随着class的升级,就无法正确反序列化;不指定版本号另一个明显隐患是,不利于jvm间的移植,可能class文件没有更改,但不同jvm可能计算的规则不一样,这样也会导致无法反序列化。
什么情况下需要修改serialVersionUID呢?分三种情况
- 如果只是修改了方法,反序列化不容影响,则无需修改版本号;
- 如果只是修改了静态变量,瞬态变量(transient修饰的变量),反序列化不受影响,无需修改版本号;
- 如果修改了非瞬态变量,则可能导致反序列化失败。如果新类中实例变量的类型与序列化时类的类型不一致,则会反序列化失败,这时候需要更改serialVersionUID。如果只是新增了实例变量,则反序列化回来新增的是默认值;如果减少了实例变量,反序列化时会忽略掉减少的实例变量。
5.总结
- 所有需要网络传输的对象都需要实现序列化接口,通过建议所有的javaBean都实现Serializable接口。
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化。
- 如果想让某个变量不被序列化,使用transient修饰。
- 序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
- 反序列化时必须有序列化对象的class文件。
- 当通过文件、网络来读取序列化后的对象时,必须按照实际写入的顺序读取。
- 单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
- 建议所有可序列化的类加上serialVersionUID 版本号,方便项目升级。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




文档写的非常优秀 :+1: