
算法之KMP
0 / 0 / 创建于 4年前 /
 it_was 的个人博客
it_was 的个人博客
KMP算法
kmp算法是为了解决传统字符串匹配问题而诞生的
有以下两个字符串A和B,长度分别为 N 和 M,判断B是否是A的子串,以及开始匹配的位置,不匹配就返回-1
A:”ababababca”
B:”abababca”
传统的方法就是主串和目标串对位比较,不对则主串重新从下一位开始,时间复杂度接近 O( N × M )
而kmp算法精妙之处在于通过找寻目标串 B 每一位的信息,利用这个信息,使得在字符不匹配的情况下,不需要整体重新来过,只需要移动一定的位置,然后继续匹配即可。
而这个信息就是——前缀与后缀相等的最大长度
下面介绍一下kmp到底如何加速字符串匹配的!
- 首先生成字符串B的
next数组,而这个数组的含义是:next[i]表示next[0....i-1]上前缀与后缀相等的最大长度,举个例子:”abababca”这个字符串中 字符 ‘c’ 的前缀和后缀相同的有 前缀”abab” 和 后缀 “abab”是最大的,故 字符”c” 的next数组位置就是 4
下图展示了”abababca”的next数组:
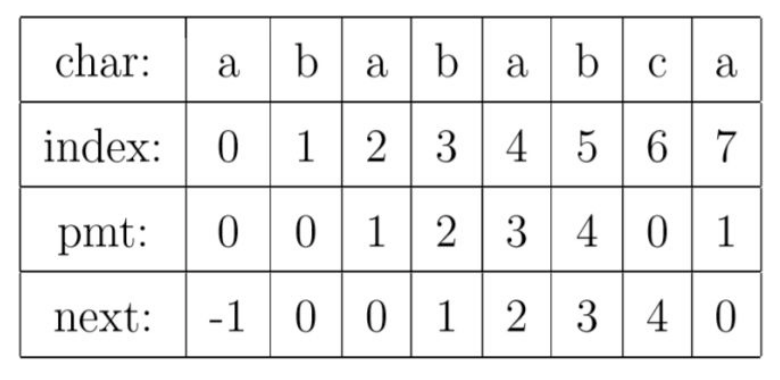
- 生成了这个next数组之后,我们就可以加速主串和目标串的匹配过程了
对于主串”ababababca”,当目标串”abababca”匹配到下标为 j 时,发现'a' != 'c',此时主串并没有重新从i = 1开始匹配,而是让目标串的 j 开始跳,跳到next[j]的下标,即j = 4,即从 j = 4开始与i继续匹配!如下图所示
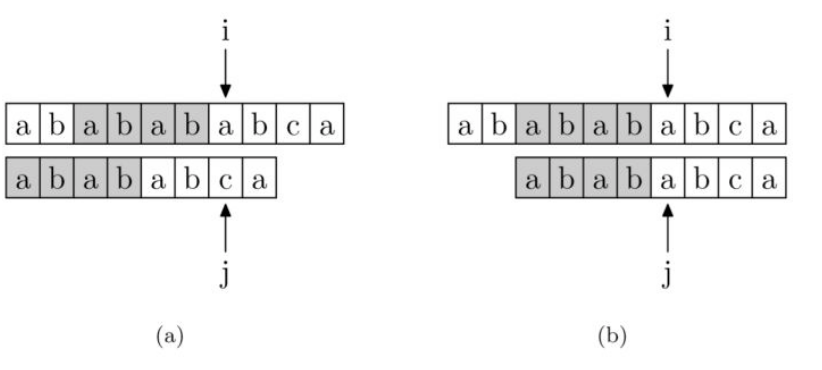
那这样做的原理是什么呢 
如下图
首先当主串和目标串匹配到A 和 B 字符的时候发生不匹配,我们知道 1 区域等于3 区域,而 3 区域等于2区域,故1区域一定等于2区域,因为next的数组的定义就是这样,前缀和后缀相等的最大长度,所以这次不需要主串重新回到 i + 1 的 位置,只需要目标串退回到2区域最后位置 + 1 ,直接从目标串的 C字符开始和 A 字符匹配即可
理解了之后,直接上代码!
public class Main(){
public static void main(String[] args){
}
public int kmp(String s1, String s2){
if(s1 == null || s2 == null || s2.length() > s1.length() || s2.length() == 0){
return -1;
}
char[] arr1 = s1.toCharArray();
char[] arr2 = s2.toCharArray();
int len1 = arr1.length;
int len2 = arr2.length;
int[] next = getNext(arr2);
int i = 0;
int j = 0;
while(i < len1 && j < len2){
if(arr1[i] == arr2[j]){
i++;
j++;
}else if(next[j] == -1){
i++;
}else{ //加速的过程体现在这,如果两个字符不相等,j 是跳到 最大前缀长度的下一个位置
j = next[j];
}
}
return j == len2 ? i - j : -1;
}
public int[] getNext(char[] arr){
if(arr.length == 1){
return new int[]{-1};
}
int len = arr.length;
int[] next = new int[len];
next[0] = -1;
next[1] = 0;
int pos = 0;
int cur = 2;
while(cur < len){
if(arr[pos] == arr[cur - 1]){
next[cur] = pos + 1;
cur++;
pos++;
}else if(next[pos] > 0){
pos = next[pos];
}else{
next[cur] = 0;
cur++;
}
}
return next;
}
}kmp的应用可以用在判断一棵树是否是另一颗树的子树!!!时间复杂度控制在O(M + N) M和N为两个树的结点数。感觉树的拓扑结构复杂的情况下用kmp不错,用递归的话接近O(M × N)
public boolean isSubTree(TreeNode A, TreeNode B) {
if(A==null||B==null){
return false;
}
return kmp(preString(A),preString(B)) != -1; //kmp一判断,完事!
}
public String preString(TreeNode root1) {
//先找到两棵树的先序序列
if (root1 == null) {
return "!_";
}
String s = root1.val + "_";
s += preString(root1.left);
s += preString(root1.right);
return s;
}
此题的递归解法:
public boolean isSubtree(TreeNode s, TreeNode t) {
if(s == null && t != null){
return false;
}
if(s == null && t == null){
return true;
}
//无非就是,两个树相同,t是s的左子树,t是s的右子树!这三种情况
return isSameTree(s,t) || isSubtree(s.left,t) || isSubtree(s.right,t);
}
public boolean isSameTree(TreeNode s, TreeNode t){
if(s == null && t == null){
//两树都一起到达底部
return true;
}
if(s == null || t == null){
//一个树有值,另一个树为空,则一定不为子树
return false;
}
if(s.val != t.val){
//不相等则更不用说
return false;
}
return isSameTree(s.left,t.left) && isSameTree(s.right,t.right);
}
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu




推荐文章: