
操作系统—I/O 模型
0 / 0 / 创建于 5年前 /
 it_was 的个人博客
it_was 的个人博客
1. 什么是 I / O ?
在Unix系统中,一切都是文件,都是二进制流。在信息交换的过程中,我们都是对这些流进行操作,即我们通常所说的
I/O(input output)操作,计算机通过对每个流记录一个文件描述符——fd(file descriptor)来区分对每个文件的操作!
2. I / O 如何操作?
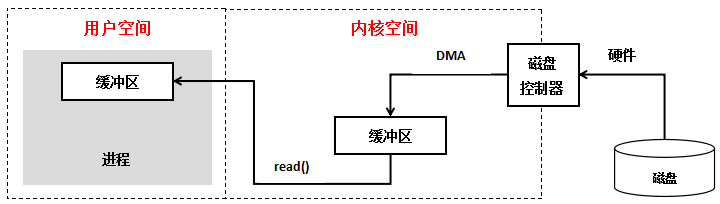
下图为最基本的 I/O 操作
下图为系统调用
3. I / O 模型
3.1 Blocking I/O Model
阻塞的I/O模型是最传统,最基本的模型,即当进程调用读取操作时,会一直阻塞到内核数据返回!
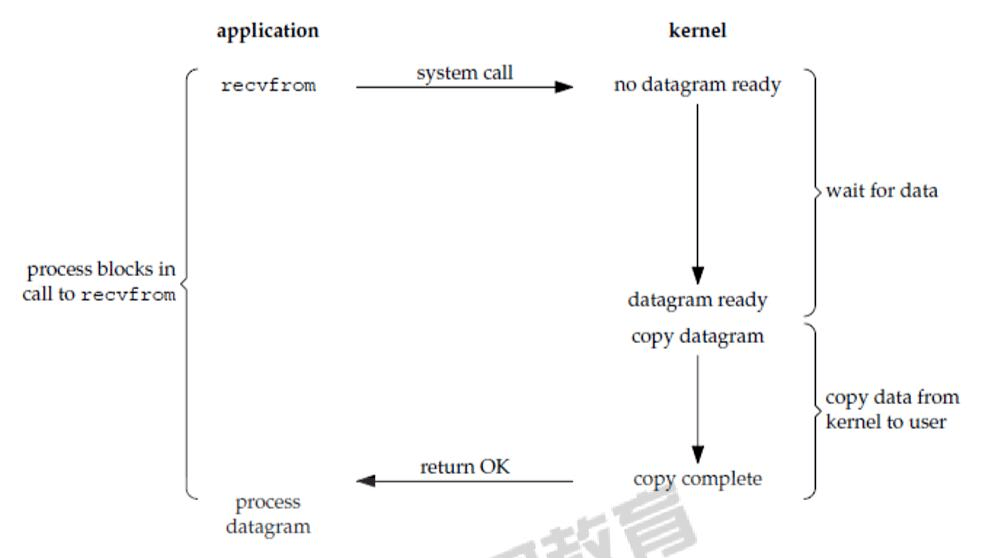
上图展示了当进程执行recvfrom函数时,通过系统调用,由用户态转入内核态,由于数据迟迟未到,所以内核一直会等待数据,直到数据准备好便将全部数据拷贝给用户进程!此情况用户进程是全程陷入阻塞状态
阻塞I/O——当你下楼拿快递,发现快递小哥没有来,ok没办法,我原地等,直到快递小哥来了,拿到了快递我再回宿舍!
3.2 Nonblocking I/O Model
非阻塞 I/O 即当用户进程调用读取操作时,如果内核数据准备好了则直接复制并返回;如果没有准备好,那就返回一个错误提示进程,并不断的去轮询是否准备好!
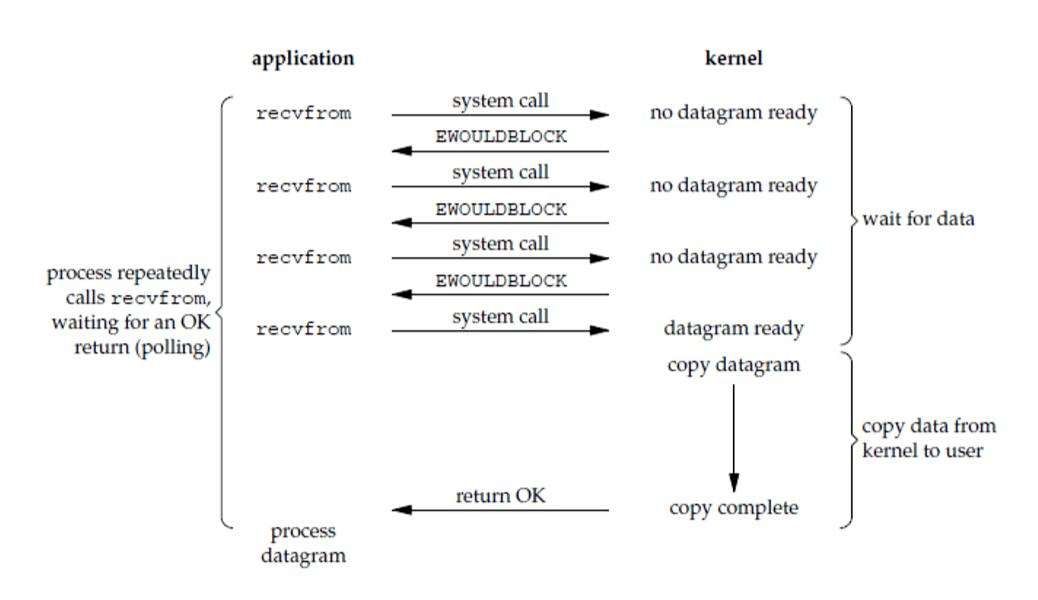
上图展示了当进程执行recvfrom函数时,通过系统调用,由用户态转入内核态,由于数据迟迟未到,所以内核不会等待数据,直接返回一个错误给用户进程!然后用户进程不断去轮询,检查数据是否准备好此情况用户进程不断去轮询内核数据是否准备好,浪费CPU时间片
非阻塞I/O-当你下楼拿快递,发现快递小哥没来,好吧我先回宿舍。刚回宿舍我心想:万一此时恰好来了呢?于是我又马上下楼去检查,重复这个过程直到快递小哥来!
3.3 I/O Multiplexing Model 
I/O 多路复用即通过执行 select 或者 poll 函数来对多个文件描述符进行监控,一旦内核发现某个数据准备好,便通知相对应的用户进程进行读取
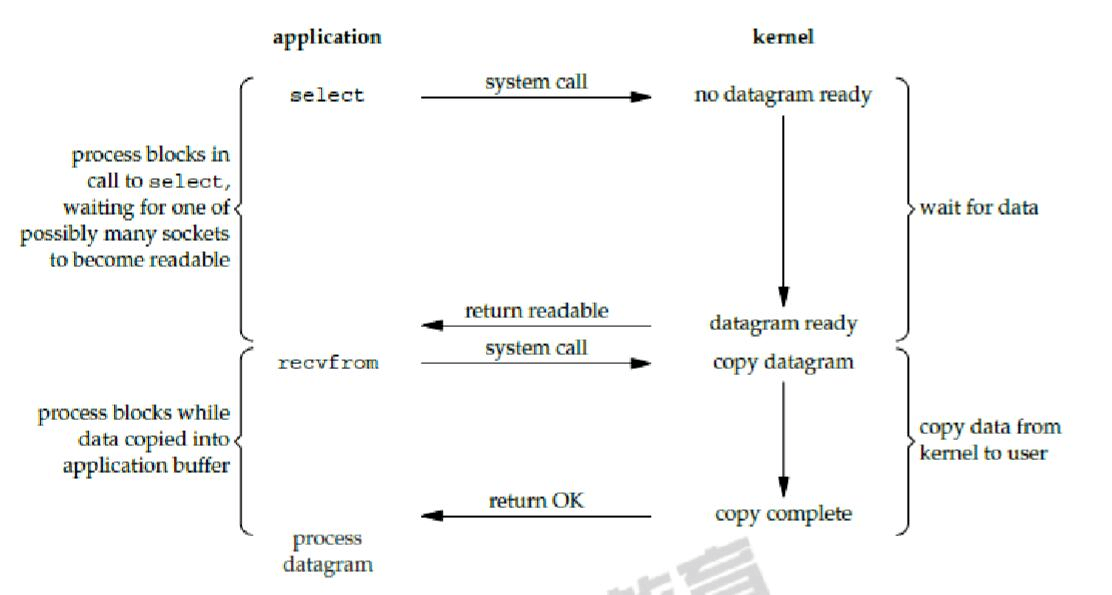
上图展示了进程一直阻塞在对 select 或者 poll 函数的调用上,等待直到某个 socket 可读,此时进程便对数据进行读取。这种模型有个明显的缺点:需要两次系统调用。而且当一个连接来了,就必须遍历所有已经注册的文件描述符,来找到那个需要处理信息的文件描述符,如果已经注册了几万个文件描述符,那会因为遍历这些已经注册的文件描述符,导致cpu爆炸。但其优势在于可以对多个socket进行监控
I/O多路复用的优势并不是对于单个连接能处理的更快,而是在于可以在单个线程/进程中处理更多的连接。与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
select,poll 和 epoll 比较
1. 支持一个进程所能打开的最大连接数
select:单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll:poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的。
epoll:虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。
2. fd 剧增后带来的IO效率问题
select:因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll:同上
epoll:因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3. 消息传递方式
select:内核需要将消息传递到用户空间,都需要内核拷贝动作
poll:同上
epoll:epoll通过内核和用户空间共享一块内存来实现的。
I/O 多路复用——同样去拿快递,但是有中通,申通,韵达等多个快递都快来了,于是我一直等电话,当某个快递小哥给我打电话的时候我就去拿。
3.4 Signal-Driven I/O Model
信号驱动型I/O即进程在IO访问时,通过使用信号告诉内核,当socket上的数据准备好了的时候,通过信号
通知一声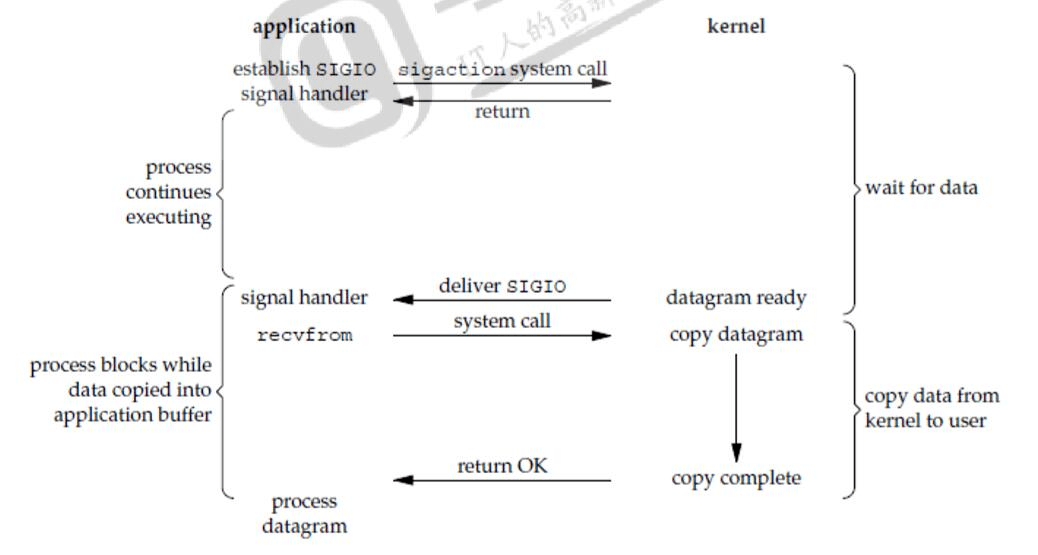
上图展示了用户进程先通过sigaction系统调用,创建一个信号处理函数,立即返回。之后进程并不阻塞,而是转而执行其他事情。当内核准备好数据后,产生一个SIGIO信号(电平触发)并投递给信号处理函数。可以在此函数中调用recvfrom函数操作数据从内核空间复制到用户空间,这段过程进程阻塞。无论我们如何处理信号,这个模型的优点是在等待数据报到达时不会阻塞。主循环可以继续执行并等待信号处理程序通知数据已准备好处理或数据报已准备好读取。
信号驱动型I/O——同样去拿快递,而且有中通,申通,韵达等多个快递都快来了,我不等电话了(这个电话与上面电话不同,此处的电话需要专用的快递电话),我先收拾宿舍卫生,一旦电话响了即某个快递来了,那我就去拿!
3.5 Asynchronous I/O Model
异步 I/O 模型即在进程发起异步IO请求,立即返回。当内核完成IO时,内核给进程发一个信号。
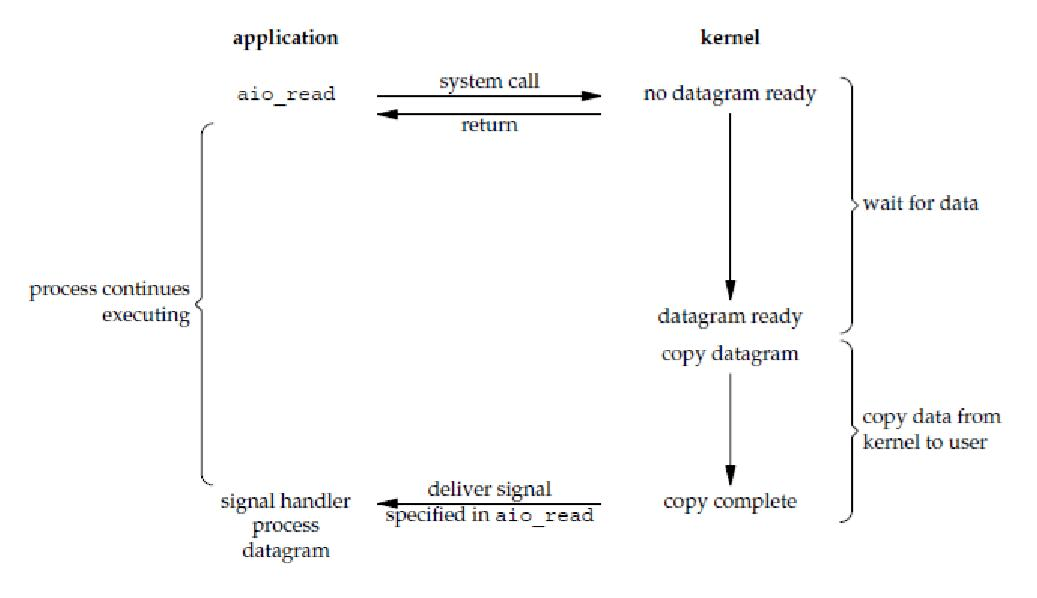
上图展示了用户进程 会首先调用 aio_read函数执行系统调用,并向内核传递描述符、缓冲区指针、缓冲区大小(与read相同的三个参数)、文件偏移量(与lseek类似),以及如何在整个操作完成时通知我们。这个系统调用立即返回,我们的进程并没有阻塞而是继续执行其他事情,直到数据全部写入缓冲区!!!
异步 I/O ——同样拿快递,我太忙了,委托给我同学去拿,并把快递的单号,类型告诉他,然后我去吃饭或者干其他事
,当他拿到快递时通知我一下,舒服
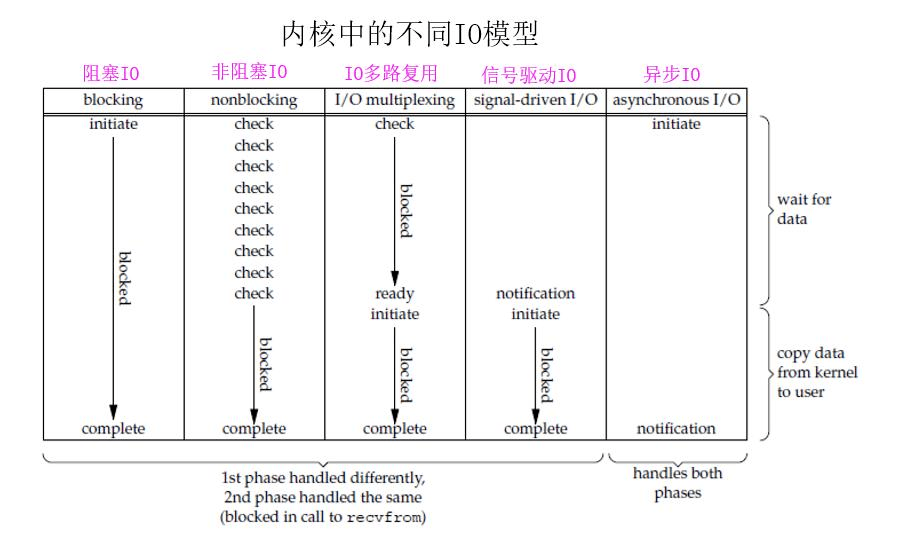
综上,前四个I/O模型都是同步型 I/O,即都会在数据从内核写入到缓冲区这个阶段阻塞,即同步I/O操作会导致请求进程被阻塞,直到I/O操作完成。异步I / O操作不会引起请求进程被阻塞
4. 关于Java中的 BIO , NIO ,AIO推荐阅读博文gitee.com/SnailClimb/JavaGuide/blo...
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



