
微服务概览与治理
2 / 4 / 创建于 5年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
前言
最新一直在跟着 毛剑 大佬去学习 GO 的一些知识点 做了自己的笔记
微服务概念
你可以把微服务想成是 SOA 你可以把微服务想成是 SOA 的一种实践的一种实践
- 小即是美:小的服务代码少,bug 也少,易测试,易维护,也更容易不断迭代完善的精致进而美妙。
- 单一职责:一个服务也只需要做好一件事,专注才能做好。
- 尽可能早地创建原型:尽可能早的提供服务 API,建立服务契约,达成服务间沟通的一致性约定,至于实现和完善可以慢慢再做。
- 可移植性比效率更重要:服务间的轻量级交互协议在效率和可移植性二者间,首要依然考虑兼容性和移植性。
微服务定义
围绕业务功能构建的,服务关注单一业务,服务间采用轻量级的通信机制,可以全自动独立部署,可以使用不同的编程语言和数据存储技术。微服务架构通过业务拆分实现服务组件化,通过组件组合快速开发系统,业务单一的服务组件又可以独立部署,使得整个系统变得清晰灵活:
优点
- 原子服务
- 独立进程
- 隔离部署
- 去中心化服务治理
缺点:
- 基础设施的建设、复杂度高
组件服务化
通过服务来实现组件,意味着将应用拆散为一系列的服务运行在不同的进程中,那么单一服务的局部变化只需重新部署对应的服务进程。我们用 Go 实施一个微服务:
- kit:一个微服务的基础库(框架)。
- service:业务代码 + kit 依赖 + 第三方依赖组成的业务微服务
- rpc + message queue:轻量级通讯
本质上等同于,多个微服务组合(compose)完成了一个完整的用户场景(usecase)。
按业务组织服务
YOU BUILD IT , YOU FIX IT
开发团队对软件在生产环境的运行负全部责任
事实上传统应用设计架构的分层结构正反映了不同角色的沟通结构。所以若要按微服务的方式来构建应用,也需要对应调整团队的组织架构。每个服务背后的小团队的组织是跨功能的,包含实现业务所需的全面的技能。
去中心化
- 数据去中心化
- 治理去中心化
- 技术去中心化
每个服务独享自身的数据存储设施(缓存,数据库等),不像传统应用共享一个缓存和数据库,这样有利于服务的独立性,隔离相关干扰
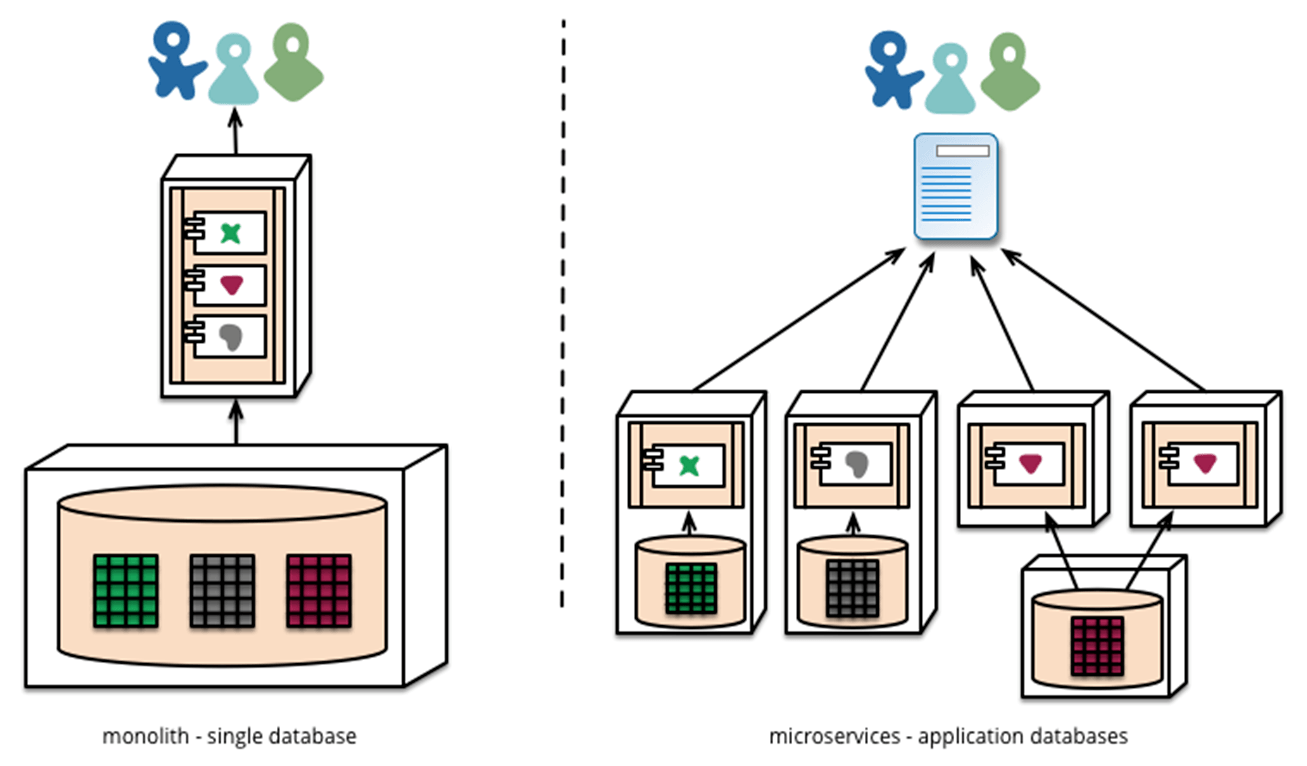
基础设置自动化
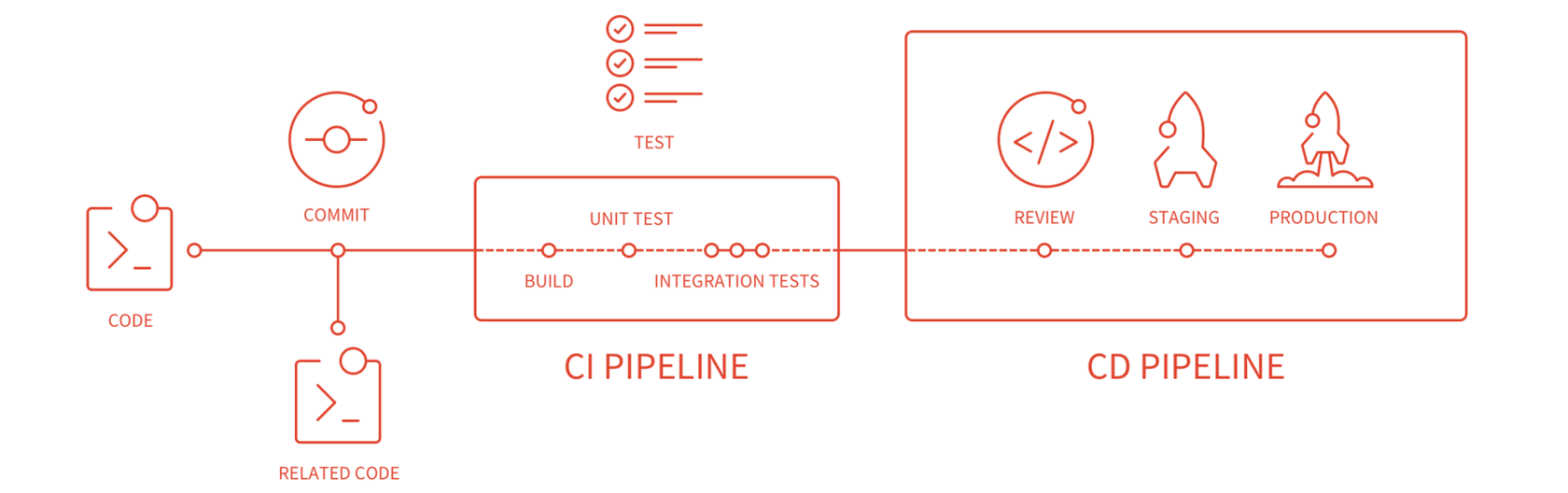
无自动化不微服务,自动化包括测试和部署。单一进程的传统应用被拆分为一系列的多进程服务后,意味着开发、调试、测试、监控和部署的复杂度都会相应增大,必须要有合适的自动化基础设施来支持微服务架构模式,否则开发、运维成本将大大增加。
- CICD:Gitlab + Gitlab Hooks + k8s
- Testing:测试环境、单元测试、API自动化测试
- 在线运行时:k8s,以及一系列Prometheus、ELK、Conrtol Panle
可用性 & 兼容器
著名的 Design For Failure 思想,微服务架构采用粗粒度的进程间通信,引入了额外的复杂性和需要处理的新问题,如网络延迟、消息格式、负载均衡和容错,忽略其中任何一点都属于对“分布式计算的误解”。
- 隔离
- 超时控制
- 负载保护
- 限流
- 降级
- 重试
- 负载均衡
一旦采用了微服务架构模式,那么在服务需要变更时我们要特别小心,服务提供者的变更可能引发服务消费者的兼容性破坏,时刻谨记保持服务契约(接口)的兼容性。
Be conservative in what you send, be liberal in what you accept.
发送时要保守,接收时要开放。按照伯斯塔尔法则的思想来设计和实现服务时,发送的数据要更保守,意味着最小化的传送必要的信息,接收时更开放意味着要最大限度的容忍冗余数据,保证兼容性。
微服务设计
API Gateway
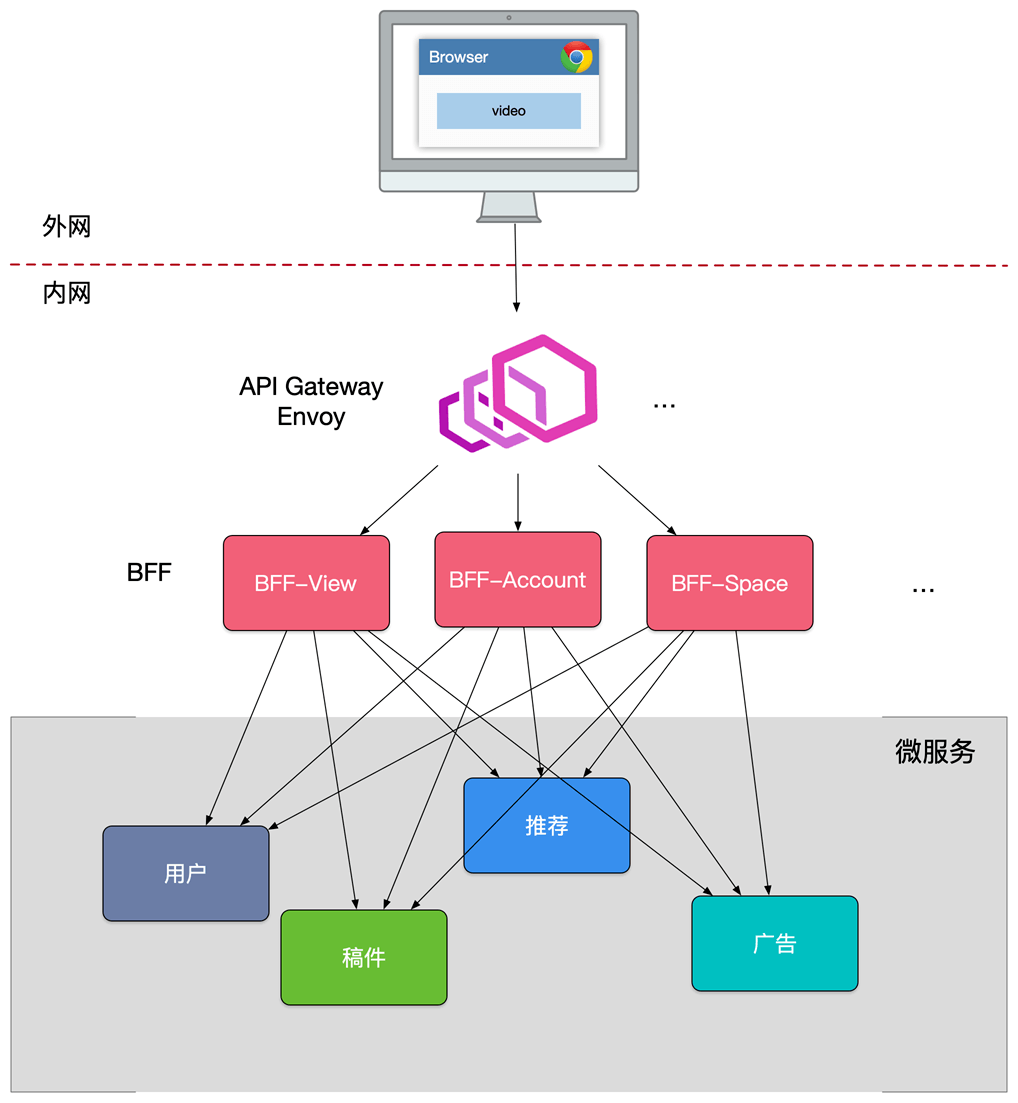
需要一个 Backend for frontend 数据聚合
在服务内进行大量的dataset join,按照业务场景来设计粗粒度的 API,给后续服务的演进带来的很多优势:
- 轻量交互:协议精简、聚合。
- 差异服务:数据裁剪以及聚合、针对终端定制化API。
- 动态升级:原有系统兼容升级,更新服务而非协议。
- 沟通效率提升,协作模式演进为移动业务+网关小组。
BFF 可以认为是一种适配服务,将后端的微服务进行适配(主要包括聚合裁剪和格式适配等逻辑),向无线端设备暴露友好和统一的 API,方便无线设备接入访问后端服务。
Mircoservice**划分**
在实际项目中通常会采用两种不同的方式划分服务边界,即通过业务职能(Business Capability)或是 DDD 的限界上下文(Bounded Context)。
Business Capability
由公司内部不同部门提供的职能。例如客户服务部门提供客户服务的职能,财务部门提供财务相关的职能。
Bounded Context
限界上下文是 DDD 中用来划分不同业务边界的元素,这里业务边界的含义是“解决不同业务问题”的问题域和对应的解决方案域,为了解决某种类型的业务问题,贴近领域知识,也就是业务。
这本质上也促进了组织结构的演进:Service per team
CQRS(查询职责分离),将应用程序分为两部分:命令端和查询端。
- 命令端处理程序创建,更新和删除请求,并在数据更改时发出事件。
- 查询端通过针对一个或多个物化视图执行查询来处理查询,这些物化视图通过订阅数据更改时发出的事件流而保持最新
Mircoservice 安全
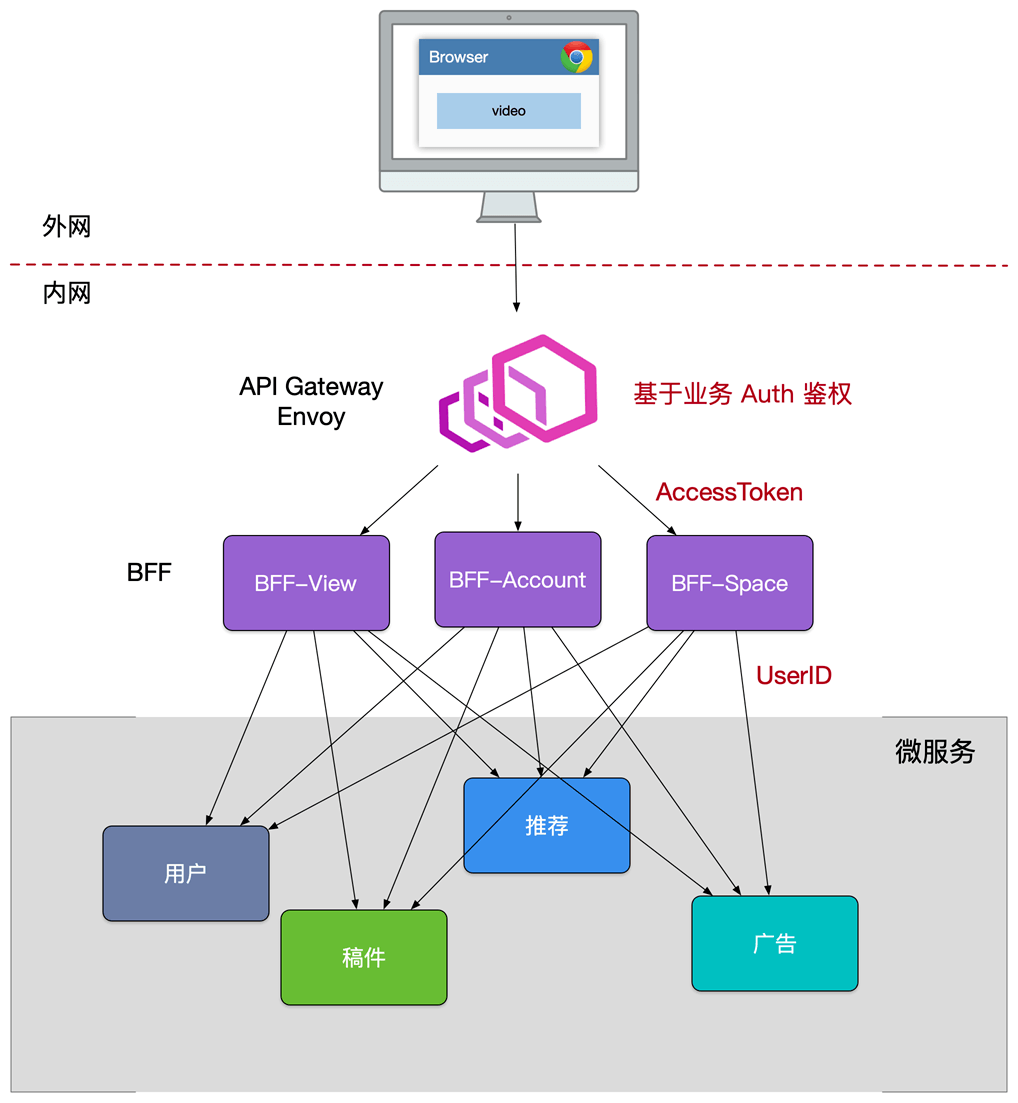
在 API Gateway 进行统一的认证拦截,一旦认证成功,我们会使用 JWT 方式通过 RPC 元数据传递的方式带到 BFF 层,BFF 校验 Token 完整性后把身份信息注入到应用的 Context 中,BFF 到其他下层的微服务,建议是直接在 RPC Request 中带入用户身份信息(UserID)请求服务。
API Gateway -> BFF -> Service
Biz Auth -> JWT -> Request Args
对于服务内部,一般要区分身份认证和授权。
- Full Trust
- Half Trust
- Zero Trust
GRPC
gRPC 是什么可以用官网的一句话来概括
“A high-performance, open-source universal RPC framework”
- 多语言:语言中立,支持多种语言。
- 轻量级、高性能:序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能序列化框架。
- 可插拔
- IDL:基于文件定义服务,通过 proto3 工具生成指定语言的数据结构、服务端接口以及客户端 Stub。
- 设计理念
- 移动端:基于标准的 HTTP2 设计,支持双向流、消息头压缩、单 TCP 的多路复用、服务端推送等特性,这些特性使得 gRPC 在移动端设备上更加省电和节省网络流量
- 服务而非对象、消息而非引用:促进微服务的系统间粗粒度消息交互设计理念。
- 负载无关的:不同的服务需要使用不同的消息类型和编码,例如 protocol buffers、JSON、XML 和 Thrift。
- 流:Streaming API。
- 阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端间交互的消息序列。
- 元数据交换:常见的横切关注点,如认证或跟踪,依赖数据交换。
- 标准化状态码:客户端通常以有限的方式响应 API 调用返回的错误。
HealthCheck
gRPC 有一个标准的健康检测协议,在 gRPC 的所有语言实现中基本都提供了生成代码和用于设置运行状态的功能。
主动健康检查 health check,可以在服务提供者服务不稳定时,被消费者所感知,临时从负载均衡中摘除,减少错误请求。当服务提供者重新稳定后,health check 成功,重新加入到消费者的负载均衡,恢复请求。health check,同样也被用于外挂方式的容器健康检测,或者流量检测(k8s liveness & readiness)。
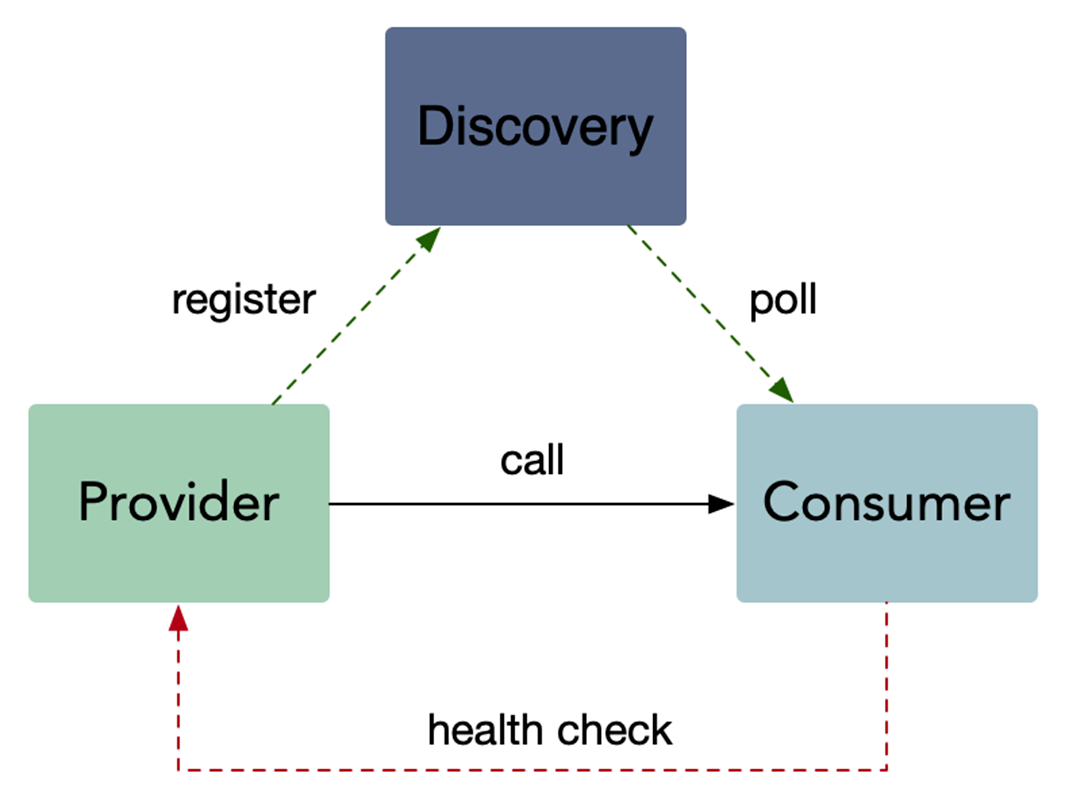
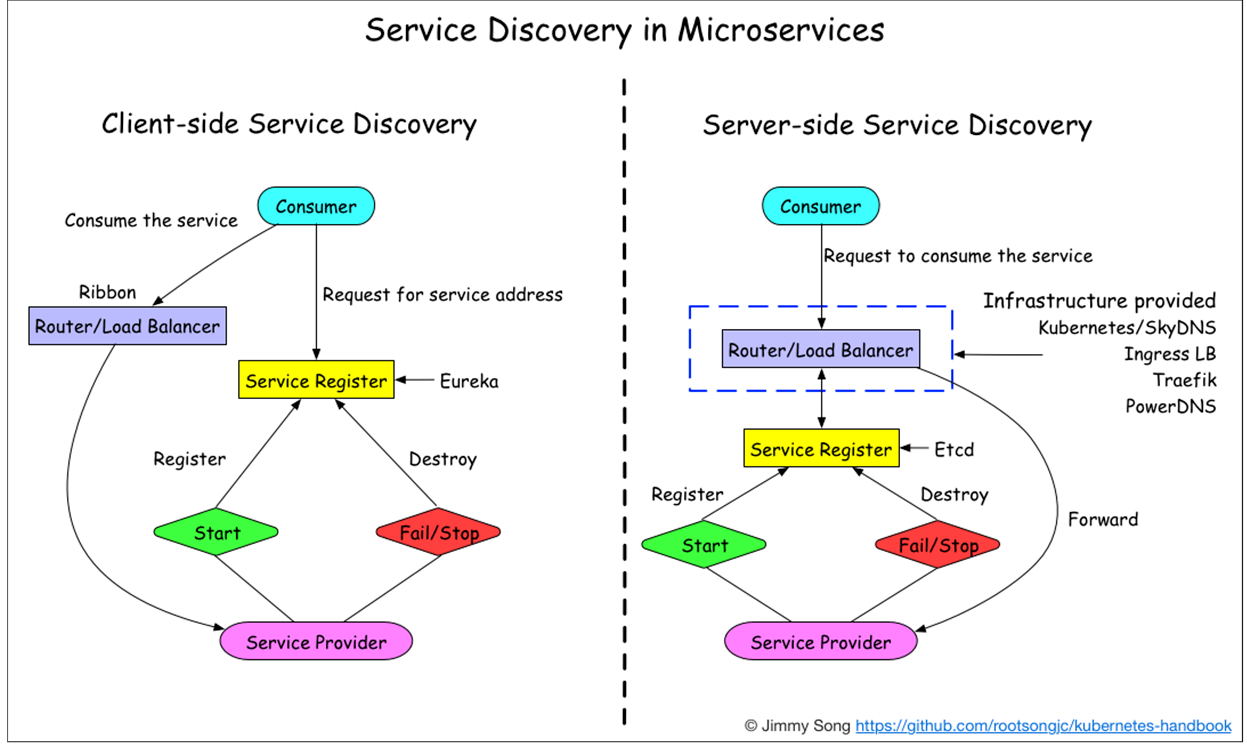
服务发现
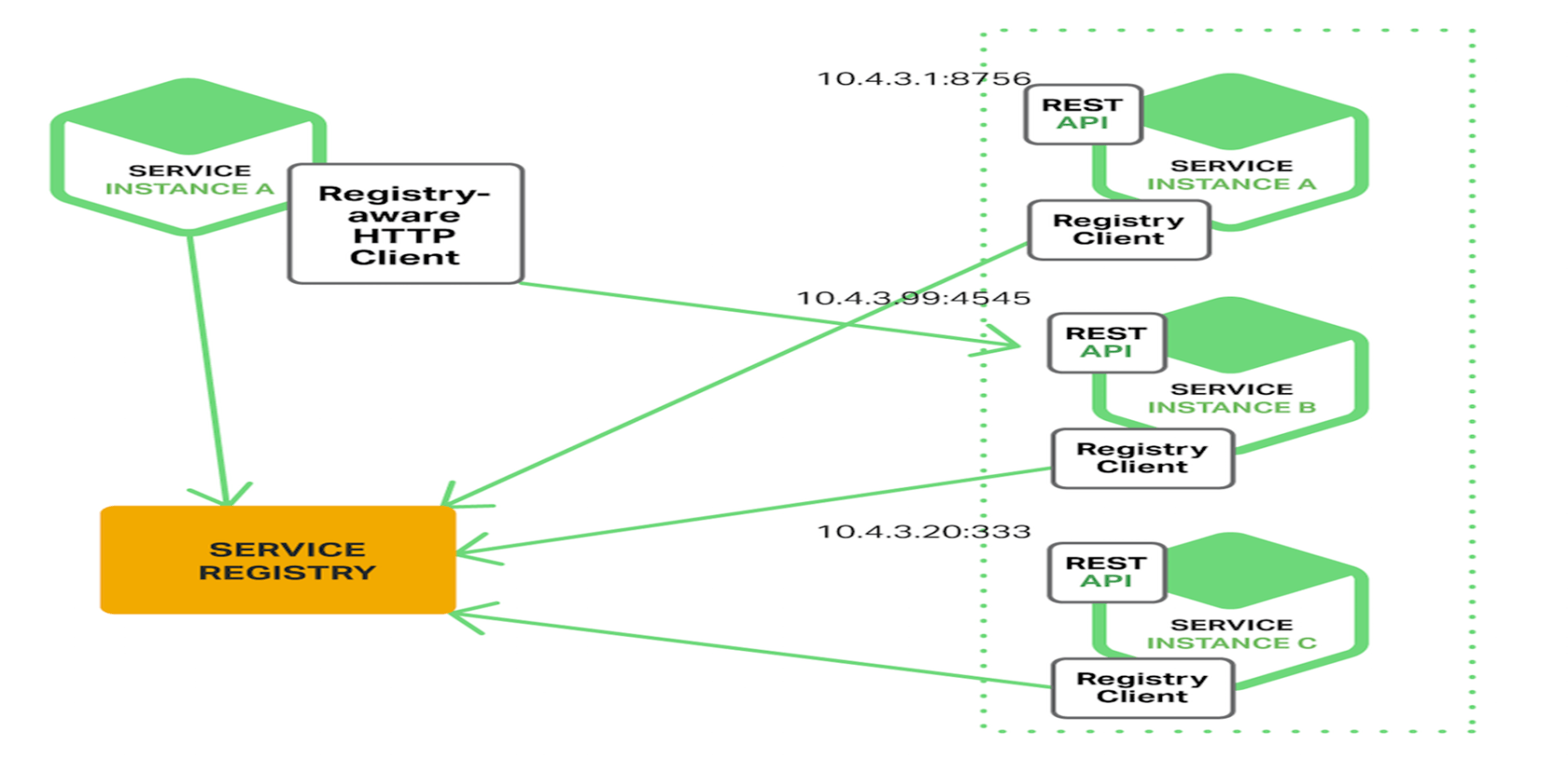
客户端发现
一个服务实例被启动时,它的网络地址会被写到注册表上;当服务实例终止时,再从注册表中删除;这个服务实例的注册表通过心跳机制动态刷新;客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求
直连,比服务端服务发现少一次网络跳转,Consumer 需要内置特定的服务发现客户端和发现逻辑。
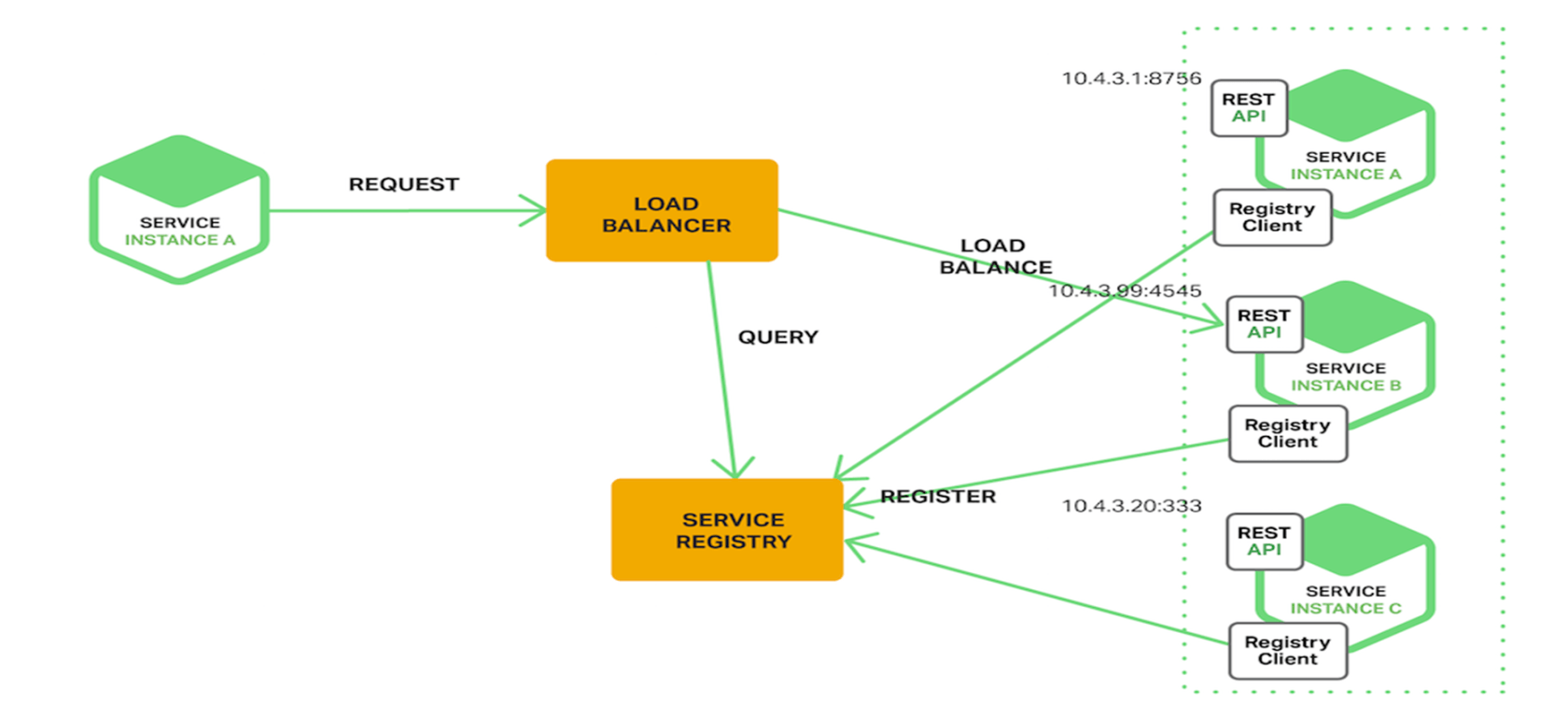
服务端发现
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。服务实例在服务注册表上被注册和注销(Consul Template+Nginx,kubernetes+etcd)。
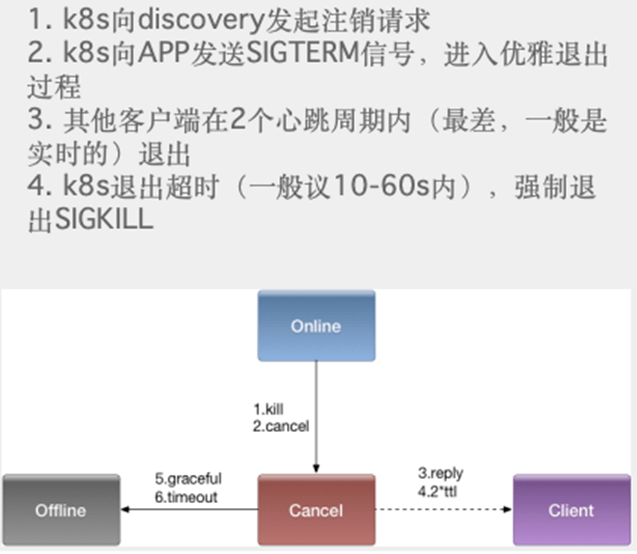
总结
微服务的核心是去中心化,我们使用客户端发现模式。
Eureka
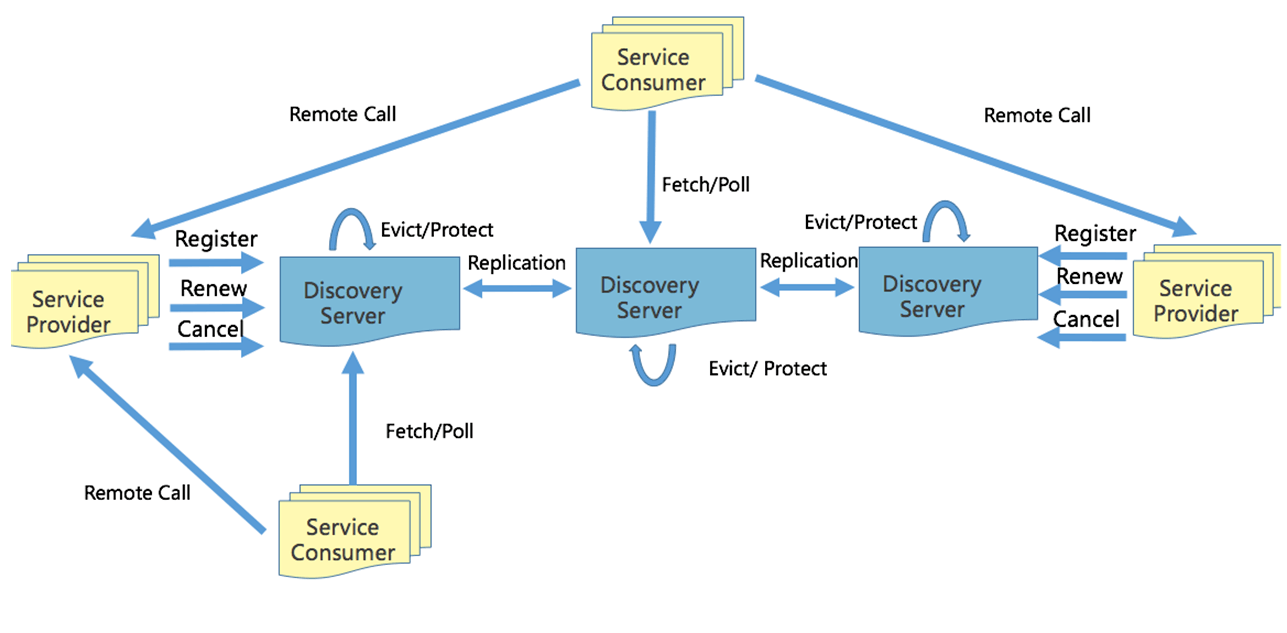
通过 Family(appid)和Addr(IP:Port) 定位实例,除此之外还可以附加更多的元数据:权重、染色标签、集群等。
appid: 使用三段式命名 :business.service.xxx
Provider 注册后定期(30s)心跳一次,注册, 心跳,下线都需要进行同步,注册和下线需要进行长轮询推送。
新启动节点,需要 load cache,JVM 预热。
故障时,Provider 不建议重启和发布。
Consumer启动时拉取实例,发起30s长轮询。
故障时,需要 client侧 cache 节点信息。
Server定期(60s) 检测失效(90s)的实例,失效则剔除。短时间里丢失了大量的心跳连接(15分钟内心跳低于期望值*85%),开启自我保护,保留过期服务不删除。
多集群
- 从单一集群考虑,多个节点保证可用性,我们通常使用 N+2 的方式来冗余节点
- 从单一集群故障带来的影响面角度考虑冗余多套集群
- 多套冗余的集群对应多套独占的缓存,带来更好的性能和冗余能力。
- 尽量避免业务隔离使用或者 sharding 带来的 cache hit 影响(按照业务划分集群资源)。
业务隔离集群带来的问题是cache hit ratio 下降,不同业务形态数据正交,我们推而求其次整个集群全部连接。
缺点
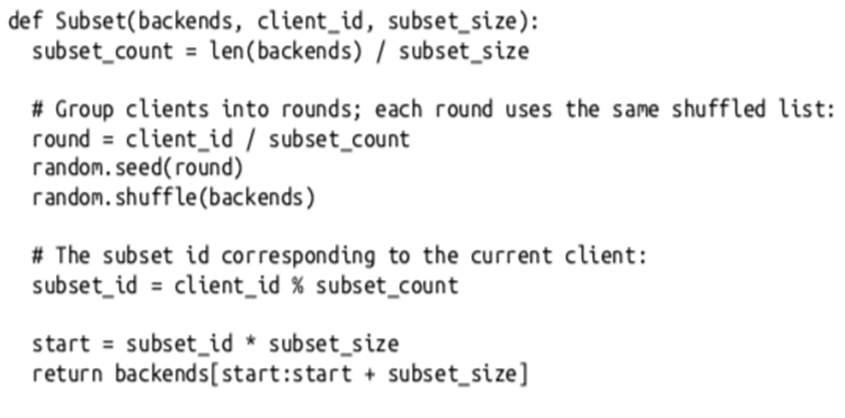
统一为一套逻辑集群(物理上多套资源池),即gRPC 客户端默认忽略服务发现中的cluster信息,按照全部节点,全部连接。能不能找到一种算法从全集群中选取一批节点(子集),利用划分子集限制连接池大小。
- 长连接导致的内存和 CPU 开销,HealthCheck 可以高达30%。
- 短连接极大的资源成本和延迟。
解决方案
合适的子集大小和选择算法
通常20-100个后端,部分场景需要大子集,比如大批量读写操作。
后端平均分给客户端。
客户端重启,保持重新均衡,同时对后端重启保持透明,同时连接的变动最小。
多租户
本质是 流量染色
给入站请求绑定上下文(如: http header),in-process使用context传递,跨服务使用metadata传递(如: opentracing baggage item),在这个架构中每一个基础组件都能够理解租户信息,并且能够基于租户路由隔离流量,同时在我们的平台中允许对运行不同的微服务有更多的控制,比如指标和日志。在微服务架构中典型的基础组件是日志,指标,存储,消息队列,缓存以及配置。基于租户信息隔离数据需要分别处理基础组件。
多租户架构本质上描述为:
跨服务传递请求携带上下文(context),数据隔离的流量路由方案。
利用服务发现注册租户信息,注册成特定的租户。
本作品采用《CC 协议》,转载必须注明作者和本文链接

















 关于 LearnKu
关于 LearnKu




推荐文章: