
理解线程同步
0 / 0 / 创建于 4年前 /
 oliver-l 的个人博客
oliver-l 的个人博客
前言
我们经常会谈到并发和并行这两个词,对于操作系统而言,并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
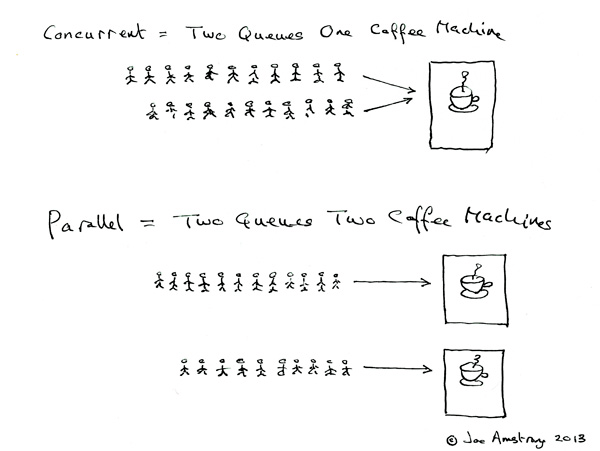
以下这张图可以比较形象的讲解并发和并行,并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机,这里的队列可以代表执行的程序。
正文
这里聚焦在并发处理上,对于不同的程序,我们知道是在处理器上交替执行的,这里就存在临界资源的竞争问题。这里的临界资源可以指代机器某个存储器存储的值。
来看看下面这个例子
package main
import (
"fmt"
"sync"
)
//临界资源
var a int = 0
var loop int = 10000000
var wg sync.WaitGroup
func main(){
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Printf("a = %d",a)
}
func add(){
for i := 0 ;i < loop;i++ {
a++
}
wg.Done()
}
func sub(){
for j := 0 ;j < loop;j++ {
a--
}
wg.Done()
}
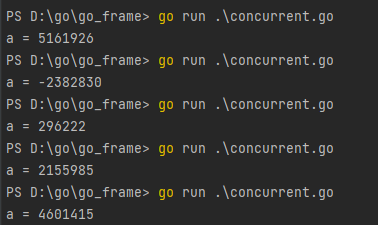
这里用变量a代表操作系统中的临界资源,go协程表示操作系统运行的程序,程序是并发执行的,由于程序之间没有同步的机制,所以每次输出的结果都不为0
所以在操作系统执行过程中,需要引入同步的机制,去实现对临界资源的控制,下面就来讲讲线程同步的几种机制
互斥量
特点:
- 互斥量是最简单的线程同步方法
- 互斥量(互斥锁),处于两态之一的变量:解锁和加锁
- 两个状态可以保证资源访问的串行
go为我们提供了原生的互斥量
package main
import (
"fmt"
"sync"
)
//临界资源
var a int = 0
var loop int = 10000000
var wg sync.WaitGroup
var lock sync.Mutex
func main(){
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Printf("a = %d",a)
}
func add(){
for i := 0 ;i < loop;i++ {
lock.Lock()
a++
lock.Unlock()
}
wg.Done()
}
func sub(){
for j := 0 ;j < loop;j++ {
lock.Lock()
a--
lock.Unlock()
}
wg.Done()
}
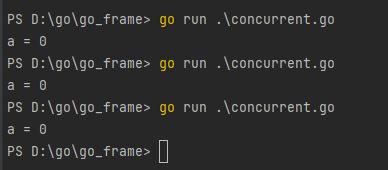
以上例子中,对临界资源的操作,我们需要先获取锁,才能对临界资源进行操作,这样就保证了访问的串行化。以下是运行的结果
自旋锁
自旋锁是指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断地判断是否能够被成功获取,直到获取到锁才会退出循环。
特点:
- 自旋锁也是一种多线程同步的变量
- 使用自旋锁的线程会反复检查锁变量是否可用
- 自旋锁不会让出CPU,是一种忙等待状态
这里用go实现自旋锁
package main
import (
"fmt"
"sync"
"sync/atomic"
)
//临界资源
var a int = 0
var loop int = 10000000
var wg sync.WaitGroup
// Spin是一个锁变量,实现了Lock和Unlock方法
type Spin int32
func (l *Spin) Lock() {
// 原子交换,0换成1
for !atomic.CompareAndSwapInt32((*int32)(l), 0, 1) {}
}
func (l *Spin) Unlock() {
// 原子置零
atomic.StoreInt32((*int32)(l), 0)
}
type Locker interface {
Lock()
Unlock()
}
func main(){
wg.Add(2)
l := new(Spin)
go add(l)
go sub(l)
wg.Wait()
fmt.Printf("a = %d",a)
}
func add(l Locker){
for i := 0 ;i < loop;i++ {
l.Lock()
a++
l.Unlock()
}
wg.Done()
}
func sub(l Locker){
for j := 0 ;j < loop;j++ {
l.Lock()
a--
l.Unlock()
}
wg.Done()
}
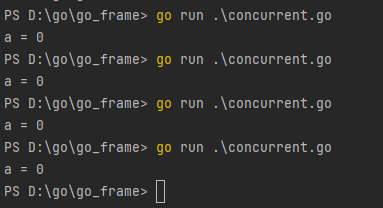
在代码实现上,获取临界资源时,执行Lock()方法会循环等待,直到获取,自旋锁的设计避免了进程或线程上下文切换的开销,但是缺点也很明显,线程处于忙等待的状态,若某个线程持有锁的时间过长,其他等待锁的线程会循环等待,消耗CPU的性能
读写锁
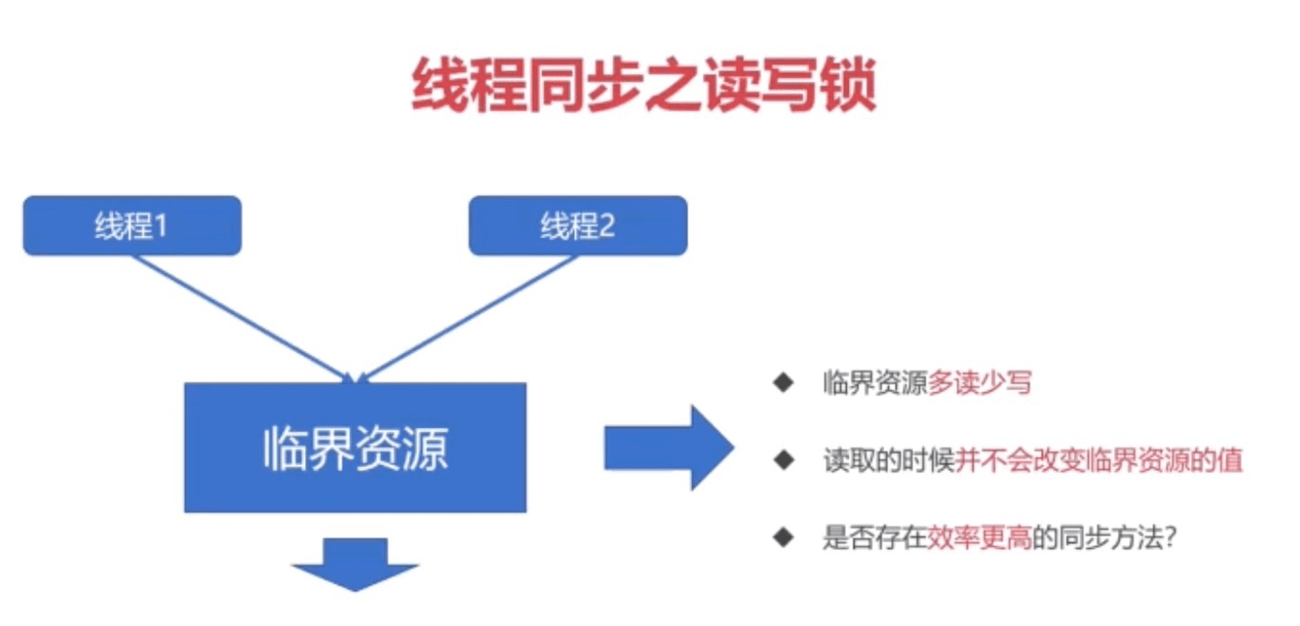
特点:
- 读写锁是一种特殊的自旋锁
- 允许多个读者同时访问资源以提高读性能
- 对于写操作则是互斥的
go语言为我们提供了原生的读写锁
package main
import (
"fmt"
"sync"
"time"
)
//临界资源
var a int = 0
var loop int = 10
var wg sync.WaitGroup
var rw sync.RWMutex
func main(){
wg.Add(4)
go writer()
go reader("小明")
go reader("小红")
go reader("小兰")
wg.Wait()
fmt.Printf("a = %d\n",a)
}
func reader(name string){
for i := 0 ;i < loop;i++ {
fmt.Printf("我是%s,我准备读了\n",name)
rw.RLock()
fmt.Printf("我是%s,a = %d\n",name,a)
time.Sleep(time.Second * 3)
rw.RUnlock()
}
wg.Done()
}
func writer(){
for i := 0 ;i < loop;i++ {
fmt.Printf("我准备写入了,当前a = %d\n",a)
rw.Lock()
a++
fmt.Printf("我写完了,当前a = %d,先歇一歇\n",a)
time.Sleep(time.Second)
rw.Unlock()
}
wg.Done()
}
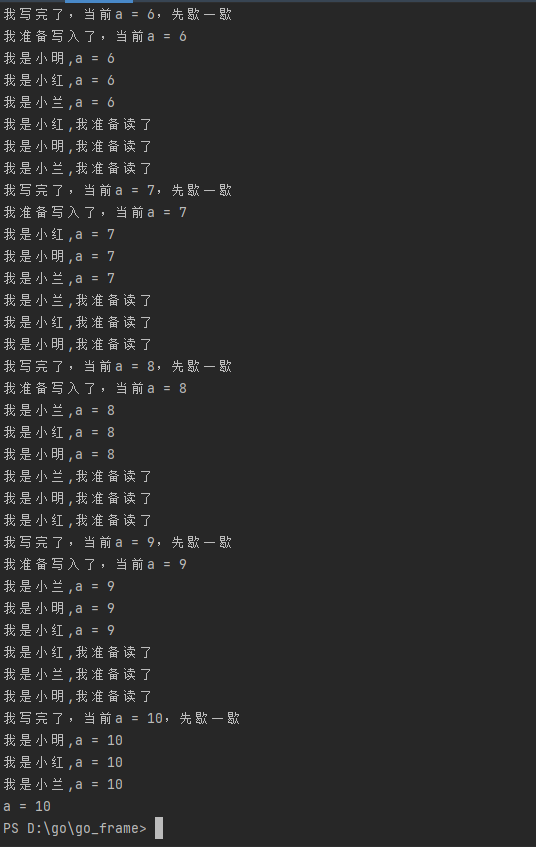
运行结果如下所示,可以看到,在执行的过程中,当读者和写者持有锁的操作时互斥的,而读者和读者持有锁是可以同步的
条件变量
特点:
- 条件变量时一种相对复杂的线程同步方法
- 条件变量允许线程睡眠,直到满足某种条件
- 当满足条件时,可以向该线程发送信号,通知唤醒
go语言为我们提供了原生的条件变量
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cond sync.Cond
//产品区
var products []int
//生产者
func produce(nu int) {
for {
cond.L.Lock()
//产品区满 等待消费者消费
for len(products) == 3 {
fmt.Printf("我是生产者%d号,产品区满了,我只能等了\n", nu)
cond.Wait()
}
num := rand.Intn(1000)
products = append(products,num)
fmt.Printf("我是生产者%d号,当前生产了%d,产品区长度为%d\n", nu, num, len(products))
cond.L.Unlock()
//生产了产品唤醒 消费者线程
cond.Signal()
//生产完了歇一会,给其他协程机会
time.Sleep(time.Second * 5)
}
}
//消费者
func consume(nu int) {
for {
cond.L.Lock()
//产品区空 等待生产者生产
for len(products) == 0 {
fmt.Printf("我是消费者%d号,产品区空了,我只能等了\n", nu)
cond.Wait()
}
num := products[0]
products = products[1:]
fmt.Printf("我是消费者%d号,当前消费了%d,产品区长度为%d\n", nu, num, len(products))
cond.L.Unlock()
cond.Signal()
//消费完了歇一会,给其他协程机会
time.Sleep(time.Second * 2)
}
}
func main() {
quit := make(chan bool)
//创建互斥锁和条件变量
cond.L = new(sync.Mutex)
//5个消费者
for i := 0; i < 5; i++ {
go produce(i)
}
//3个生产者
for i := 0; i < 3; i++ {
go consume(i)
}
//主协程阻塞 不结束
<-quit
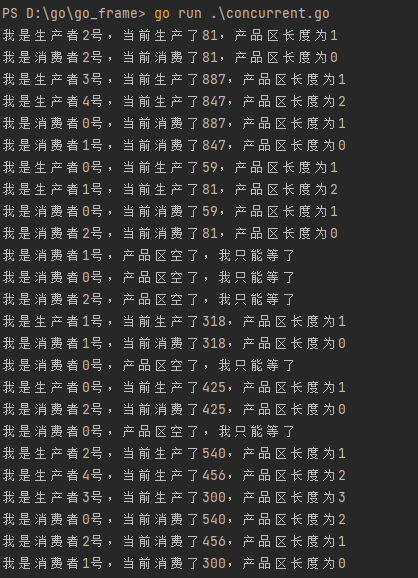
}运行结果如下所示,当生产者生产完毕后,会通知消费者进行消费,当消费者消费完毕后,会通知生产者进行生产,当产品区等于0时,不允许消费者消费,消费者必须等待。当产品区满时,不允许生产者继续生产,生产者必须等待,这一过程都是通过条件变量去实现的
实际应用
mysql读写锁
对于临界资源的概念,我们在实际开发过程中都会有所接触。如mysql的读写锁
在处理并发读或写时,可以通过实现一个由两种类型组成的锁系统来解决问题。这两种锁通常被称为共享锁和排他锁,也叫读锁和写锁。
- 读锁是共享的,相互不阻塞,多个用户同一时刻可以读取同一个资源而不相互干扰。
- 写锁是排他的,一个写锁会阻塞其他的写锁和读锁,确保在给定时间内只有1个用户能执行写入并防止其他用户读取正在写入的同一资源。
可以针对单表的读写锁
表独占写锁(lock table A write)
- 获得表A的WRITE锁定
- 当前session对锁定表的查询、更新、插入操作都可以执行,其他session对锁定表的查询被阻塞,需要等待锁被释放,陷入等待状态
- 释放锁后,其他session获得锁,查询结果返回
表共享读锁(lock table A read)
- 获得表A的READ锁定
- 当前session可以查询该表记录,其他session也可以查询该表的记录
- 当前session不能查询没有锁定的表,其他session可以查询或者更新未锁定的表
- 当前session插入或者更新锁定的表都会提示错误,其他session更新锁定表会等待获得锁,陷入等待状态
- 释放锁后,其他session获得锁,更新操作完成
针对整张表的读写锁对于已正常上线的系统来说,性能非常低效,Innodb存储引擎提供了行级锁
共享锁(S):SELECT * FROM table_name WHERE …LOCK IN SHARE
允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A。其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。
这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
- set autocommit = 0(通过以上设置autocommit=0,则用户将一直处于某个事务中,直到执行一条commit提交或rollback语句才会结束当前事务重新开始一个新的事务。)
- 当前session对id = 10的记录加share mode的共享锁;其他session仍然可以查询记录,并也可以对该记录加share mode的共享锁
- 当前session对锁定的记录进行更新操作,等待锁;其他session也对该记录进行更新操作,则会导致死锁退出
- 当前session获得锁后,可以成功更新
排他锁(X):SELECT * FROM table_name WHERE …FOR UPDATE
允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A。其他事务不能再对A加任何锁,直到T释放A上的锁。
这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
- set autocommit = 0
- 当前session对id = 10的记录加for update的排他锁;其他session可以查询该记录,但是不能对该记录加排他锁,会等待获得锁
- 当前session可以对锁定的记录进行更新操作,更新后释放锁
- 其他session获得锁,得到其他session提交的记录
秒杀库存
对于一个秒杀系统来说,秒杀库存也是一个临界资源,在秒杀过程中,如果出现超卖的现象,可能会导致公司在秒杀活动中的严重亏本。
在高并发下,为了确保数据的一致性,通常采用事务来操作数据。但是,直接使用事务会影响系统的并发性能。为此,我们通常会通过队列采用异步的方式将请求排队和串行化,这样可以大大降低事务的并发操作,提升系统性能。
内存队列主要用于接收请求后,在服务内部进行初步排队。具体来说,在队列的生产端,通过扣减内存库存的方式对请求进行初步过滤,然后推送到队列中;在消费端,以固定速度消费队列中的请求,并过滤掉超时的请求,再扣减 Redis 库存。
总结
| 同步方法 | 描述 |
|---|---|
| 互斥锁 | 最简单的一种线程同步方法,会阻塞线程 |
| 自旋锁 | 避免切换的一种线程同步方法,属于“忙等待” |
| 读写锁 | 为“读多写少”的资源设计的线程同步方法,可以显著提高性能 |
| 条件变量 | 相对复杂的一种线程同步方法,有更灵活的使用场景 |
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: