
《Redis 设计与实践》读书笔记系列二:简单动态字符串
0 / 1 / 创建于 4年前 /
 巴啦啦 的个人博客
巴啦啦 的个人博客
简介
简单动态字符串的英文全称为 Simple Dynamic String,简称为SDS。可以简单地理解为Redis中存储字符串的一种结构体,针对这个结构体,还有对应的很多相关函数。
127.0.0.1:6379> set k1 Redis
ok在上述示例中,k1 为键名,k1 的底层存储结构就使用了SDS。在Redis中string类型的值,底层结构之一就是使用SDS的结构来存储。
我们知道Redis是由C 语言写的。那么简单的字符串存储为什么不直接使用C 语言的字符串来存储,而要建立一个结构体来存储呢?(在Redis中,C 字符串只会作为字面量,用在不能或不需要修改的字符串值中,如日志打印,如上述控制台中,输出的ok)。
首先先介绍一下SDS结构究竟长什么样。对于该结构的定义,在sds.h的文件中:
struct sdshdr{
int len;//buf中实际存储的字符串长度
int free;//未使用的剩余长度
char buf[];//字节char类型数组,实际字符串保存地
}对于上述示例中,设置的k1的值Redis,所对应的SDS结构,应该如下:

问题
这里有以下疑问:
为什么明明存的是
Redis,而实际buf中Redis后面加了一个\0。为什么
buf中的char类型数组有6个,而len是5。free有什么用。为什么要用
SDS而不是 C 的字符串来进行存储。
回答以上疑问:
1.\0 在C语言中是转义字符。\0 表示空字符NULL,对应的ASCII码为0,通常用来表示字符串的结束标志。这样做的好处是,SDS可以直接使用C语言的字符串函数处理buf内的数据。例如:printf("%s",s->buf);
2.len代表的是实际使用字节数量,\0并不会计算到len里面去,即实际buf开辟空间为6,实际使用长度为5,len为5。
3.这涉及到空间分配的效率上。之后的内容会详细的说到free和空间分配效率的关系。
重点,为什么不用 C 字符串而用SDS
可以推导出来,C 的字符串必然满足不了Redis的需求,才会产生SDS这么一种存储方式。那么是哪些满足不了呢?
总结起来可以从三个方面来说,效率,安全,功能。这三个方面包含了以下五种为什么选择 SDS的原因。
1. 字符串的长度计算复杂度
C语言每次计算长度,会从头遍历整个字符串,复杂度为O(N),当发现空字符\0时,停止计数。而SDS,本身有len来记录字符串长度。复杂度为O(1)。
2. 缓冲区溢出
C语言是先分配内存,再在内存中写入数据的,如果不做好判断就会造成缓冲区溢出。例子:
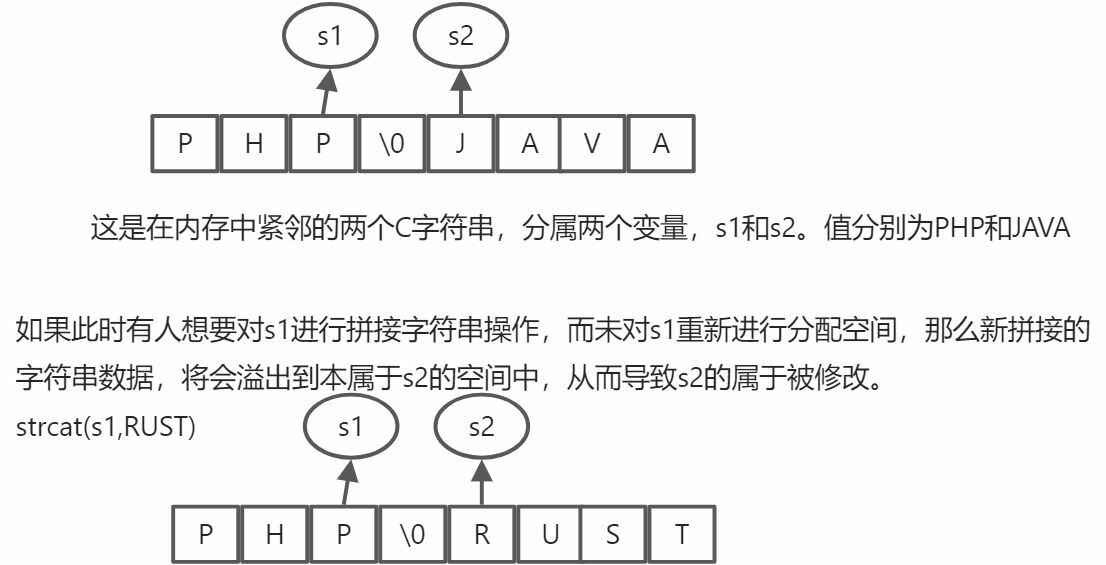
这就是缓冲区溢出的现象,对于C而言,这种情况是有可能发生的。
而对于SDS而言,其结构绑定的方法,会自动处理这些情况,即当发生字符串修改时,会去根据修改的内容判断该SDS的空间够不够用,不够用就会对空间进行扩容后,再进行处理。即避免了缓冲区溢出的情况。
3. 内存重新分配
上述第二点已经说明,若 C 字符串需要进行修改,将涉及到重新分配内存空间,否则可能会发生缓冲区溢出,或内存泄漏,而分配内存空间是一个比较耗时的操作。
Redis作为数据库,经常被用于速度要求严苛,数据被频繁修改的场合,如若使用C字符串,必然会影响其效率。SDS拥有len和free两个字段,结合起来使用,优化了C字符串修改所引起的内存分配策略。即空间预分配和惰性空间释放。
3.1 空间预分配策略说明
该策略主要针对字符串增长时的操作:当SDS的API对一个SDS进行修改,而原有空间不够需要重新进行扩容时,该策略扩容不仅会满足字符实际存储长度,而且会为SDS分配额外的未使用的空间,即free字段。
可以推导得知,一个新生的SDS的free必然是0,只有当其进行修改过,free才会进行变化。
简而言之,该策略的作用,相对C的字符串操作而言减少扩容操作次数,也就减少了耗时。属于通过空间换取时间。
该策略的free数值的确定公式和SDS的扩容策略说明:
设修改后的值长度为 x ,当 x > (SDS.len+SDS.free+1) 时,进行扩容操作。x小于1M时,SDS.len和SDS.free均等于x,如x=13,那么该SDS.len和SDS.free均为13。而SDS.buf,则会开辟出13+13+1个的字节空间。最后这个1是空字符。
当x大于1M时,SDS.free始终保持为1M,而SDS.len等于x。如x=13M,SDS.len=13M,SDS.len=1M,而SDS.buf,则会开辟出13M+1M+1个的字节空间。
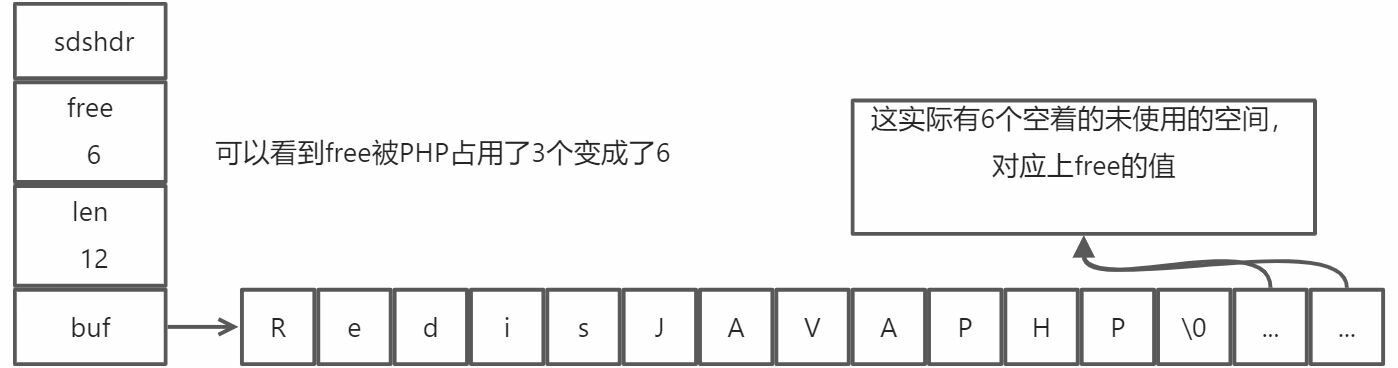
那么该策略是如何减少扩容操作次数的呢?看示例:现有一新的SDS,结构数据如下
对该SDS,进行拼接一个JAVA字符串的操作(该操作SDS自有API操作,我们只需要调用append操作即可),那么该SDS将会变成如下数据结构:

接下来,再对该SDS拼接上一个PHP,PHP要占3个字节,SDS的API首先会先看free数值是否大于3,目前大于说明装得下它,本次拼接,则不需要扩容,直接未使用空间。即两次修改,只扩容了一次。该预分配策略保证了扩容次数从必定N次,变成了最多N次。
修改拼接完后,该SDS的数据结构如下:
3.2 惰性空间释放策略说明
该策略是用来应对字符串缩短的所造成的内存分配操作。比如trim操作。
当缩短实际存储的字符串后,SDS不会立即进行内存回收,而是会将移除的字符串长度加到free字段中,即buf空间还是不变。这样即可以避免缩短带来的内存重新再分配,也相当于优化了该SDS下次可能面对的字符串增长带来的扩容问题。
SDS也提供了相应的API,可以再有需要的时候释放掉free,避免内存浪费。
本小节内容,回答了第三个问题,free到底有什么用。
4. 二进制安全
保存的是二进制数据,也能保证数据的完整性,可以简单的理解为这就是二进制安全。即输入存进去是什么样,它被读取时就会是什么样。这种特性让他可以不仅仅可以存字符串,还能存储多媒体格式,如图片。即可以放空格,空字符。也不会被当作C中的字符串截断。SDS使用len来判断值是否结束,而不是C中的使用空字符判断是否结束。
5. 兼容部分C字符串函数
因为SDS的在buf数组后也会添加上一个空字符串,目的就是为了可以方便使其可以使用部分C字符串函数,而不用再去自己实现对应的方法。例如:
strcat(c_string,sds->buf);//对c字符串的追加操作
strcasecmp(sds->buf,"Redis");//对比两个字符串可以看到到处都需要用到len来进行各种操作和运算,若没有记录长度,那就只能去遍历了。
总结
| C 字符串 | SDS | |
|---|---|---|
| 获取字符串长度复杂度 | O(N) | O(1) |
| 缓冲区溢出 | 没操作好的情况下有可能溢出 | 不会溢出 |
| 内存分配次数 | N次修改N次分配 | N次修改<=N次分配 |
| 保存内容 | 仅字符串 | 二进制安全 |
| 使用C的字符串函数 | 全部 | 部分 |
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: