
《Redis 设计与实践》读书笔记系列四:字典
0 / 0 / 创建于 4年前 /
 巴啦啦 的个人博客
巴啦啦 的个人博客
本章节含结构,实现,哈希算法,键冲突内容。对于理解后几篇的内容,该章节较为重要,是基础。
字典简介
字典又称为,符号表(symbol table),关联数组(associative array),映射(map)。是一种保存键值对的抽象数据结构。
字典结构在Redis中应用广泛,Redis中的数据库就是使用字典作为底层实现。对数据库的增删改查操作也是构建在对字典的操作上的。
redis>set k1 v1#在这里k1就是使用了字典的键,v1就成了对应的值。
OKRedis中Hash这种结构底层也用到了字典结构,当Hash中的键值对比较多时,或该Hash中的元素都是较长字符串时,也会使用到字典作为Hash的底层实现。
在使用了字典结构地方和功能中,这些功能都用拥有各自的字典。而不会共用同一个字典结构。
字典实现
字典使用到了哈希表作为底层实现(非Redis中的Hash结构)。接下来由上至下介绍字典的实现。
字典 dict 和 dictType 的实现
typedef struct dict{
//类型特定函数。dictType保存了一簇用于操作特定类型键值对的函数,
//Redis会为用途不同的字典设置不同的类型特定函数。(书中原文解释)
dictType *type;
//私有数据,保存了dictType中函数的可选参数。
void *privdata;
//哈希表,字典中有两张哈希表。
dictht ht[2];
//rehash 索引,当不在rehash动作时,值为-1
int trehashidx;
}dict;
typedef struct dictType{
//计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
//复制键的函数
void *(keyDup)(void *privdata,const void *obj);
//复制值的函数
void *(valDup)(void *privdata,const void *obj);
//对比键的函数
int (*keyCompare)(void *privdata,const void *key1, const void *key2);
//销毁键的函数
void (*keyDestructor)(void *privdata, void *obj);
//销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
}哈希表 dictht 和 dictEntry 的实现
上述dict结构可知,内含两个dictht。而哈希表的主要结构由哈希表节点组成。
哈希表dictht及其哈希表节点dictEntry的结构:
typedef struct dictht{
//装有多个哈希表节点的数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值,始终等于size-1
//该属性和哈希值一起决定了一个键应该被放在table中的哪个索引上面
unsigned long sizemask;
//该哈希表已有值的节点数量
unsigned long used;
}dictht;
typedef struct dictEntry{
//键
void *key;
//值,联合体
union{
void *val;
uint64_t u64;
int64_t s64;
}v;
//指向下个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry;可见。哈希表节点dictEntry结构中保存着真正的键值对。
哈希表和哈希节点关系图
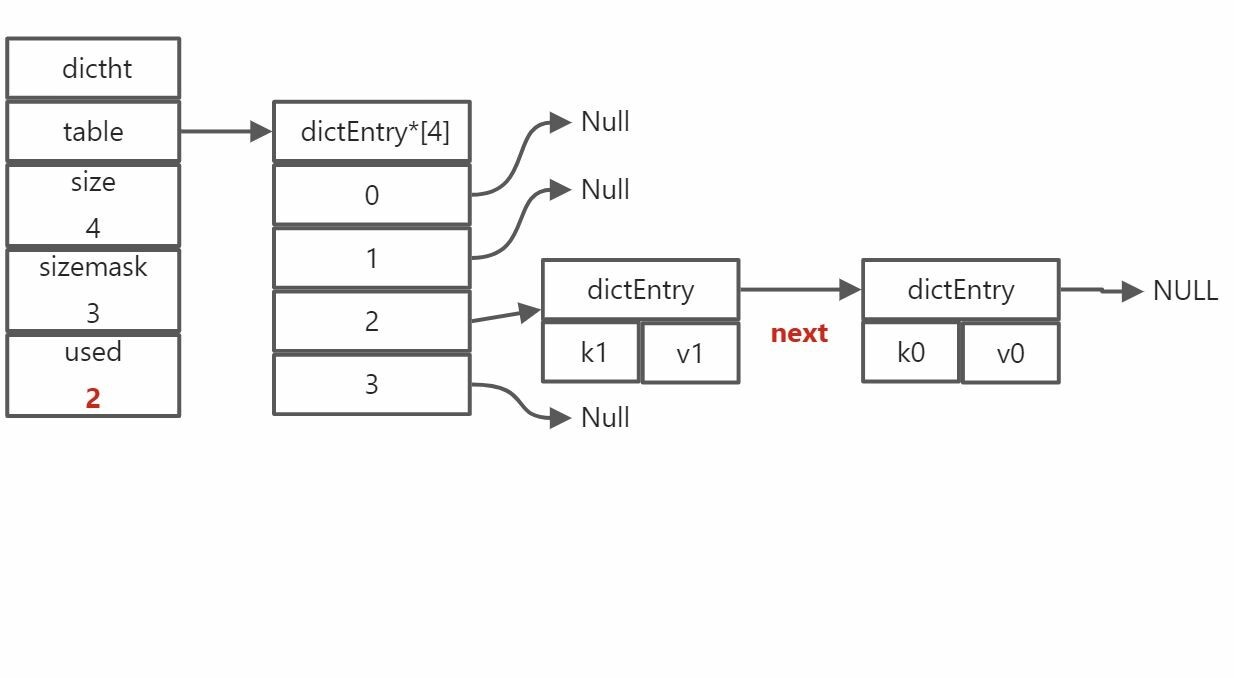
哈希表和哈希节点关系说明
- 这里的 size 等于 4,表明了该哈希表拥有了 4 个哈希节点
- used 表明了 已经有两个
dictEntry有值了。可见这里的used并非指的是table数组中数组元素指向dictEntry的个数。而是指的整个table中含有的dictEntry个数。
因为一个dictEntry,可以通过next属性,指向另一个dictEntry。即一个table元素上,可以挂载多个dictEntry,最终形成了一个链表。
造成这种现象的原因是这些dictEntry的通过哈希算法得到的索引值,均一致,散列发生了冲突。最终形成了一个单向链表。
哈希算法和散列冲突
散列冲突:书中原文为键冲突。我在此称为散列冲突,散列这个动作更加形象,此种现象也被称为哈希碰撞。
哈希算法
当一个新的键值对添加到字典当中时会有三个步骤:
- 将新添加的键算出哈希值
- 用哈希值和dict中的一些属性算出索引值
- 将新添加的键值对做成一个
dictEntry,放到相对应的索引值(即dictht对应的table数组中)上去。
使用字典设置的哈希函数,传入新添加的键值对中的键,计算哈希值
hash = dict->type->hashFunction(key);
使用dictht中的sizemask属性和上一步得到的哈希值,计算索引值
根据情况不同ht[x]可以是 ht[0]或者ht[1]
index = hash & dict->ht[x].sizemask;
散列冲突的处理办法
当新增的键值对,算出来的索引值的位置上已经有一个dictENtry后,怎么处理?在这里使用的是链地址法(separate chaining)。即该索引指向的值将会是一个单向链表,新增的值,放在链头。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: