
《Redis 设计与实践》读书笔记系列五:字典 rehash
0 / 0 / 创建于 4年前 /
 巴啦啦 的个人博客
巴啦啦 的个人博客
rehash
上一章节有提到,dict的ht是一个数组,仅有两个dictht,内容介绍了dictht的组成和关系。接下来的内容解释了为什么要有两个dictht,原因可以总结为因为rehash。
为什么要有 rehash
随着操作的不断执行,哈希表 ( dictht ) 中保存的键值对会增多或减少,如果过多或过少,负载因子就会超出合理的范围。为了让哈希表的负载因子维持在一个合理的范围,就需要对哈希表进行rehash,达到根据哈希表的大小进行相应的扩展或收缩。
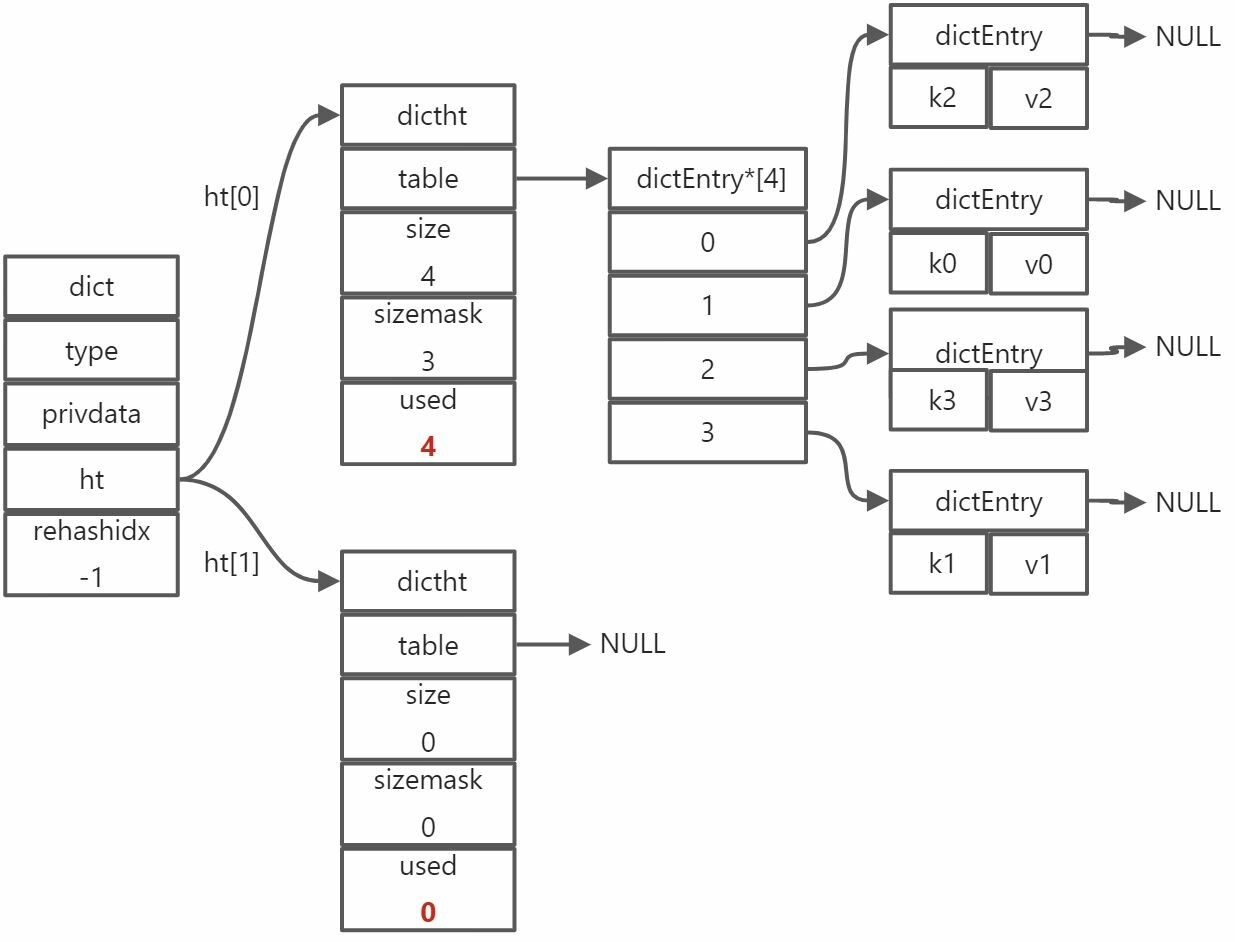
dict字典中有dictht属性,是一个数组,ht[1]则是用于rehash的。
未进行rehash时dict的结构图
rehash扩容的过程简述
- 将
ht[1]的table新建一个dictEntry数组(扩容必然大于ht[0]中table数组的容量)。 - 将
ht[0]中的键值对重新以ht[1]中的属性计算哈希和索引值,映射到ht[1].table.dictEntry中的哈希节点中,并将ht[0]中dictEntry数组索引指向的dictEntry设置为Null。 - 释放
ht[0],并将ht[1]设置为ht[0],然后为ht[1]为配一个空的哈希表(即table指向NULL)。
ht[1]的扩容算法:
x = ht[0].used * 2。n = 2 的多少次方(while2的次方不断累加)。
在n不断的计算过程当中,当n第一次大于等于x时。n即为ht[1]的容量。例:
当ht[0].used等于4时。x = 8。n的幂不断 + 1,导致n不断变大,幂等于2时,n等于4。n未大于等x。幂继续+1,等于3,n这时等于8,大于等于x。这时取8作为ht[1]的size。
ht[1]的收缩算法:
同扩容算法大概一致。不同的地方在于x的计算。收缩算法中ht[0].used=x。即不用乘以2。
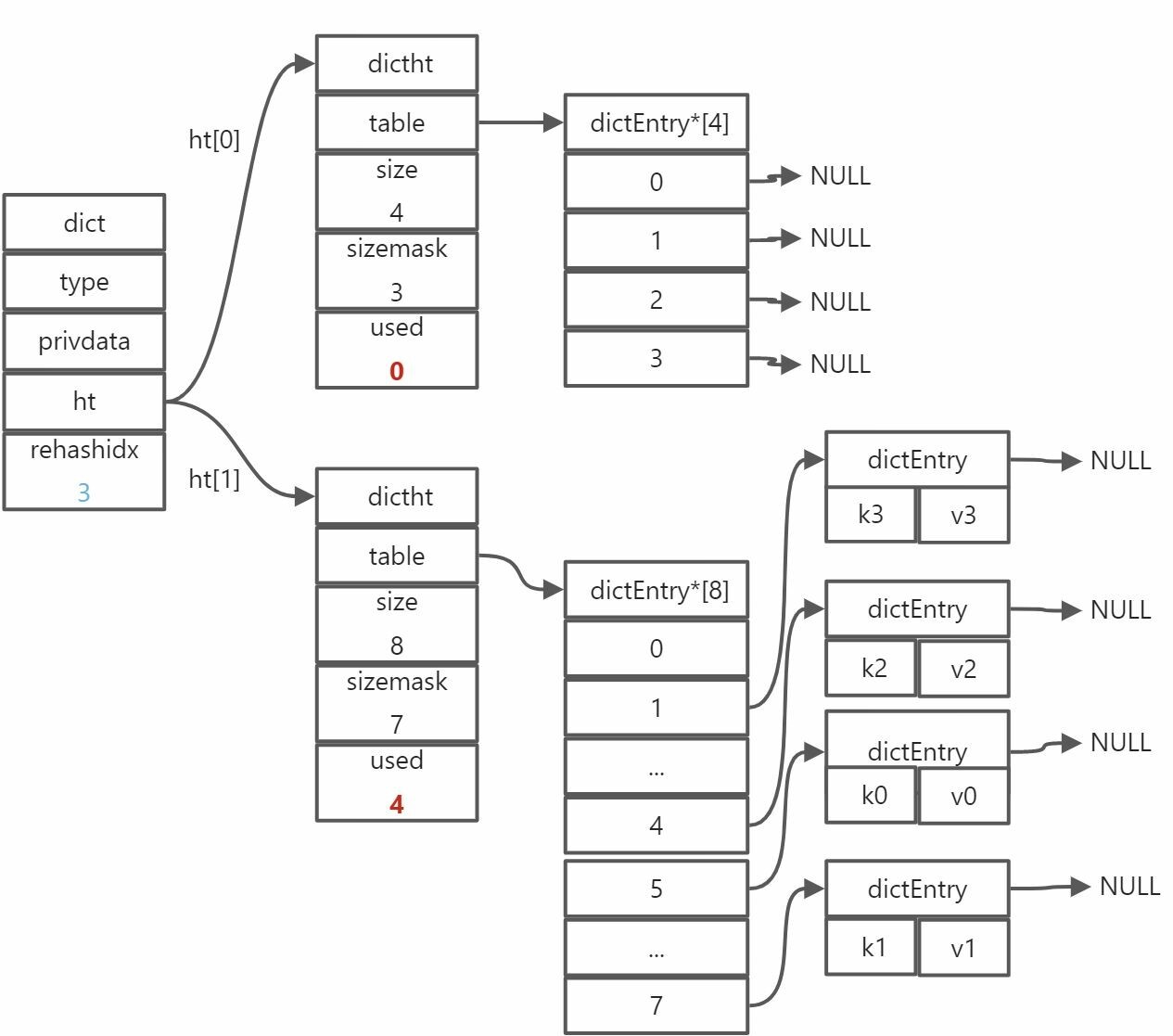
扩容第二步结果图
由上一图作为 rehash 基础作为演示:
rehash触发条件
负载因子计算方式:load_factor = ht[0].used / ht[0].size
收缩触发条件:负载因子小于0.1时。
扩容触发条件:
- 当前没有执行
bgsave或bgrewriteaof命令,且哈希表负载因子>=1。 - 当前正在执行
bgsave或bgrewriteaof命令,且哈希表负载因子>=5。
渐进式的rehash
rehash为什么是渐进式的?
如果哈希表的数据量很大,rehash的占用会很高,涉及到哈希计算和索引计算,数据转移等。所以rehash需要分多次,渐进式的完成。
它是如何进行的?
它将rehash的操作平摊到每一次对该字典的增删改查的操作上,即每次进行增删改查,都会进行一部分的rehash操作,并将rehasidx修改。这就是渐进式,避免了集中式rehash带来的庞大计算量。
上一图可见,rehashidx值为3,表明了正在进行rehash。那为什么是3而不是2,rehashidx还代表着什么?
rehashidx代表ht[0].table这个数组中的索引,意味着当前rehash已经进行到了哪个索引了。3则意为着索引为3的键值对已转移完毕。
当键值对全部转移完毕后。rehashidx会重新归于-1。
当rehashidx不等于-1时,这个时候查询一个键值对,会怎样?
不等于-1,则意味着正在进行rehash,会先在ht[0]中查找,没找到就会在ht[1]中查找。
当进行rehash时,新增一个键值对会怎样?
会直接新增到ht[1]中。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: