
MySQL索引失效的底层原理
0 / 1 / 创建于 3年前 /
 my38778570 的个人博客
my38778570 的个人博客
cs.usfca.edu/~galles/visualization/...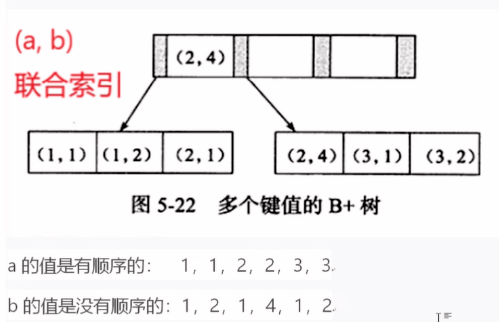
建立联合索引a,b,可以看到a的值是有序的,b是无序
由于a的值是有序的,可以能通过二分查找去查询数据
#用到索引
EXPLAIN SELECT * where a=1 and b=1 from test由于b的值是无序的,可以不能通过二分查找去查询数据
#用不到索引
EXPLAIN SELECT * where b=1 from test所以为什么要遵循最前缀法则了
#and b =1用不到索引
EXPLAIN SELECT * where a>1 and b =1#用到索引
EXPLAIN SELECT * where a=1 and b =1#用到索引
EXPLAIN SELECT * where a like "1%"#用不到索引
EXPLAIN SELECT * where a like "%1%"b-tree
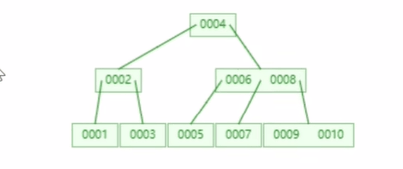
b-tree存在回旋查找的问题,比如查找大于5的数,我先定位到这个5,定位到这个5之后我再回头去查找6,然后再查找7,然后再查找8然后再查找9,最后查找10
b+tree
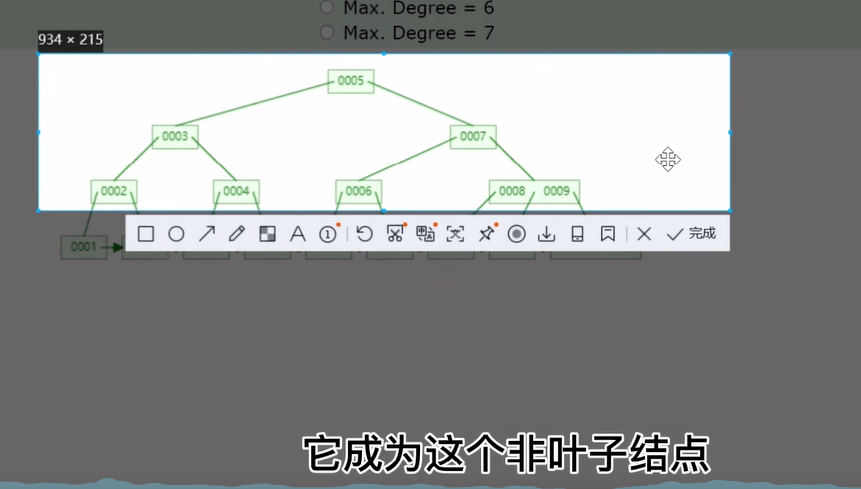
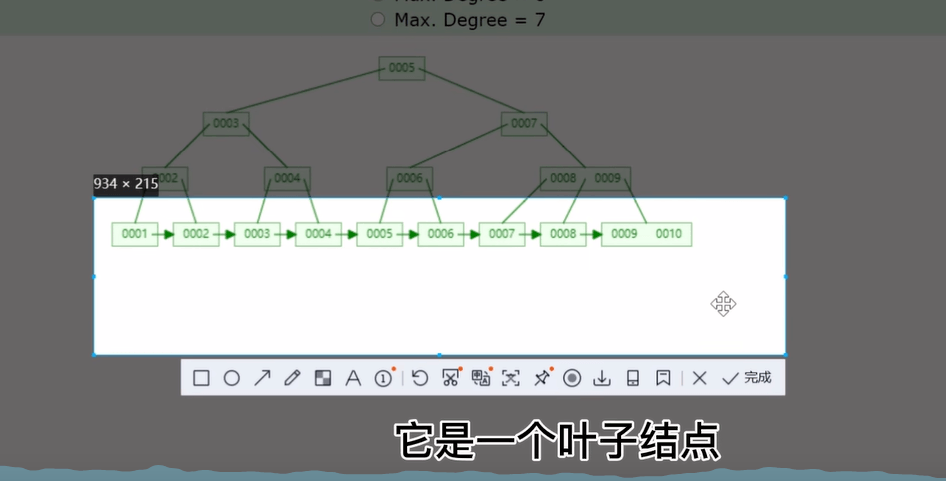
非叶子结点他们只存储这个 key,他们不存储这个 value叶子结点即存key又存这个value
b+tree和B树有明显的区别
b+tree 彻底解决回旋查找的问题,这里是一个叶子节点,其实他这里是一个链表,他把你所有的数进行了链表的排序,从小到大的排序,他通过单向链表解决回旋查找的问题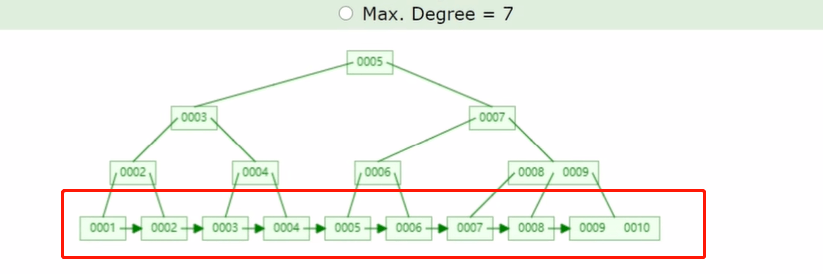
本作品采用《CC 协议》,转载必须注明作者和本文链接











 关于 LearnKu
关于 LearnKu




推荐文章: