
别让这样的定时任务拖垮你的网站
71 / 30 / 创建于 3年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
背景介绍
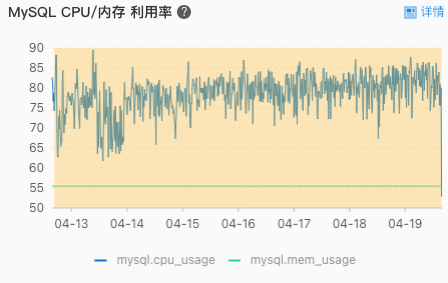
最近有同事反馈线上的 MySQL 查询速度非常慢,我打开阿里云的控制台看了看,一看吓了一跳,线上的 MySQL CPU 使用率居高不下,平均值都在80%以上,而且已经持续了有一段时间了。80%!!!这还了得,势必要排查下到底是什么原因导致 CPU 飙的这么高。
分析定位
根据以往经验,导致 MySQL CPU 过高的罪魁祸首一般是慢查询,于是先去收集了一波慢查询的 SQL。当我把能优化的慢查询优化完一遍以后,信心满满地回到了控制台,刷新页面,等待奇迹的发生时,结果却被打脸了—— CPU 并没有明显的变化。
难道问题不是出在慢查询上?
我又把焦点停在了 MySQL 的监控指标面板上:
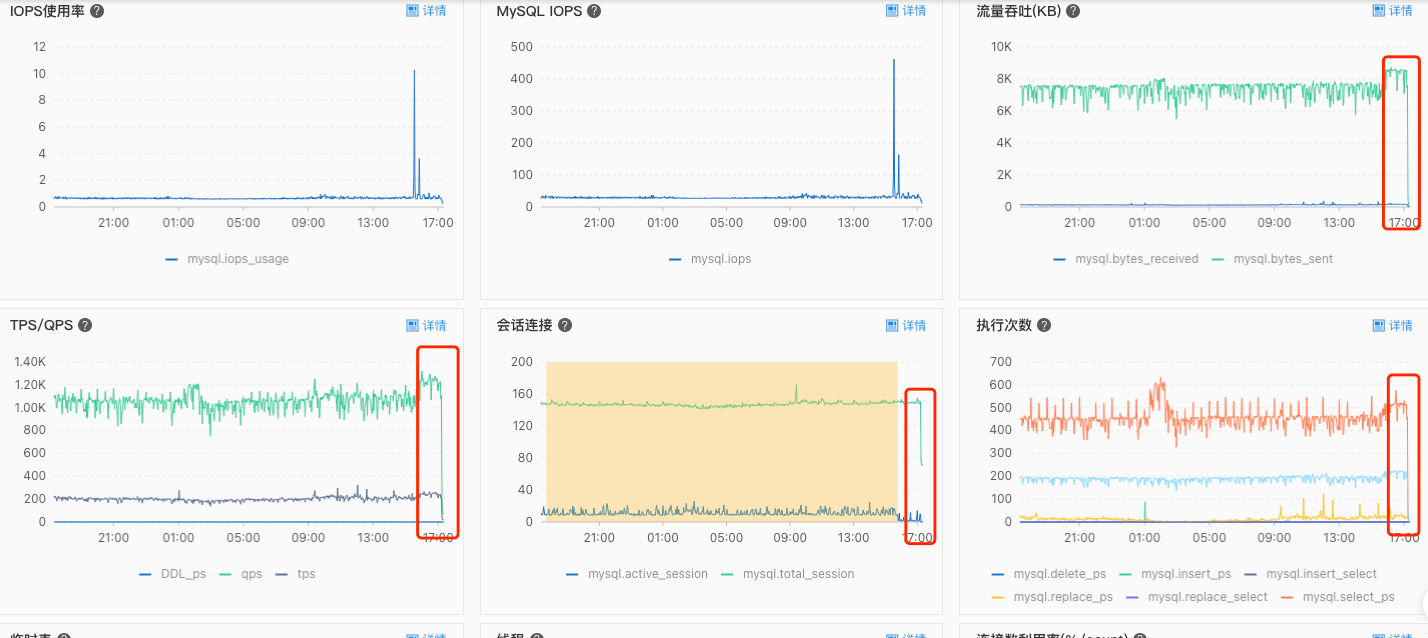
除了 CPU 异常之外,图中有几个异常的指标引起了我的注意:
- 流量吞吐 - mysql.bytes_sent:
8000 KB - QPS:
1200 次/秒 - 会话连接 - mysql.total_session:
150 - 执行次数 - mysql.select_ps:
500 次/秒
名词解释:
mysql.bytes_sent:服务端平均每秒发送给客户端的字节数
QPS:每秒执行的查询数
mysql.total_session:当前全部会话
mysql.selec_ps:平均每秒select语句执行次数这些指标几乎与 CPU 的变化趋势保持一致,说明有可能直接或者间接导致了 CPU 的负荷过高。
根据主观推断,流量吞吐异常可能是因为单次查询数据返回量过大,QPS 和每秒执行的 select 查询次数异常可能是查询的频次过高,会话连接数异常可能存在未正常释放的连接。什么业务场景可能会同时触发这几个条件呢?
就在我不知所措的时候,我在控制台 CPU 异常时间点的快照中发现了需要优化的查询一栏,在第一条 SQL 后面的优化建议中写着 限流 二字,限流???为什么提示我限流呢?我毫不犹豫地点开详情:
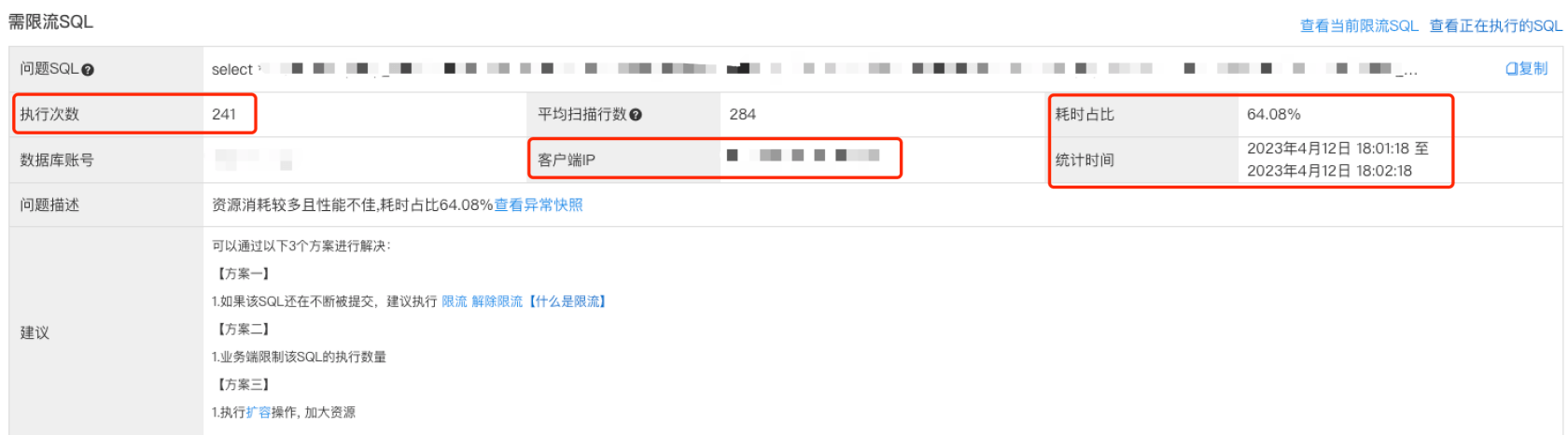
根据耗时占比达到 64.08% 不难看出这条查询嫌疑重大,再根据统计时间和执行次数分析:一分钟时间内执行了 241 次!!!平均每秒就要执行 4 次,什么查询需要每秒钟执行 4 次呢?
还好快照中保存了我们溯源的关键信息:根据客户端 IP 和端口号,我们可以定位到「案发第一现场」,再根据 SQL 里的关键字信息,我们不难定位到具体的代码位置,接下来就该揭开「作案人」的神秘面纱了!
为了方便分析,我们这里截取部分主要的代码片段进行分析:
/**
* 自动确认收货
* PS: 定时任务,每五分钟执行一次
*/
public function autoConfirmReceipt ()
{
// 查询条件:订单状态为已发货,发货时间超过15天且不存在售后
$condition = [
'order_status' => 2, // 订单状态:已发货
'refund_status' => 0, // 售后状态:无售后
'delivered_at' => ['<', time() - 15 * 86400] // 发货时间:超过15天
];
while (1) {
// 查询多条记录,参数依次为:查询条件,返回字段,返回条数
$list = $this->orderModel->getMore($condition, ['*'], 100);
if (!$list) {
break;
}
foreach ($list as $item) {
try {
// 开启事务
DB::beginTransaction();
$orderId = $item['id'] ?? ''; // 订单ID
$shareUid = $item['share_uid'] ?? ''; // 分享人ID
// 逻辑一:根据主键更新记录
$ret = $this->orderModel->updateByKey($orderId, [
'order_status' => 3, // 订单状态:已收货
'confirmed_at' => time() // 确认收货时间
]);
if (!$ret) {
throw new Exception('自动确认收货更新订单信息失败。');
}
// 逻辑二:根据订单更新分享人佣金信息
$ret = $this->commissionModel->updateByCondition(
[
'order_id' => $orderId, // 订单ID
'share_uid' => $shareUid, // 分享人ID
],
[
'status' => 2, // 已到账
'arrived_at' => time(), // 到账时间
]
);
if (!$ret) {
throw new Exception('自动确认收货更新佣金信息失败。');
}
// 提交事务
DB::commit();
} catch (Exception $e) {
Log::error('自动确认收货失败。', [
'line' => $e->getLine(),
'message' => $e->getMessage(),
'item' => $item,
]);
// 回滚事务
DB::rollback();
continue;
}
}
// 贴心的沉睡
sleep(5);
}
}看完上述代码,感觉有何不妥?
从逻辑上看,每次从表中筛选符合条件的数据,然后进行更新,更新完以后再执行一段相关的业务逻辑,感觉也没什么不妥之处啊?理论上讲,如果表中仅有少量需要处理的数据,一次查询即可处理完毕,下一次循环查询的时候返回空直接就退出了,也不会有什么压力啊,即使需要执行多次查询,还有个贴心的 sleep 沉睡,理论上也不会有太大压力,为何成了「作案凶手」呢?
让我们把焦点再回到提示限流的 SQL 详情里,有个线索需要引起我们的重点关注:该条 SQL 在一分钟的时间里执行了 241 次,什么概念?平均每秒就要执行4次。
可问题是我们程序中还有个贴心的沉睡 sleep ,就算查询时间、更新时间都忽略,一分钟也就最多执行 12 次啊,怎么能达到 241 次呢?(实测执行一次批量查询的 SQL 大概需要 5s 左右,这就更解释不通了)
难不成这段代码还能自动变身?
既然正常逻辑解释不通,那就不妨先跟踪下进程看看是否存在异常。正常来讲的话,程序会在每五分钟时被调用,如果查询不为空的话进程至少会持续 5s 以上(5s 沉睡),所以我们尽量卡在分钟数是 5 的倍数的时间点查看进程状态(如:12:00,12:05等)。OK,分析完,我们选个吉利的时间点直接使用 ps aux | grep '{keyword}' 进行分析,结果令我大跌眼镜:
居然同时有 100 多个进程在运行!!!WTF???
冷静片刻,我大概已经想到是什么原因了。不急揭晓答案,让我们稍微换个纬度,通过时序图来大致分析一下:
正常情况下我们的程序调用应该是长下面这个样子的:
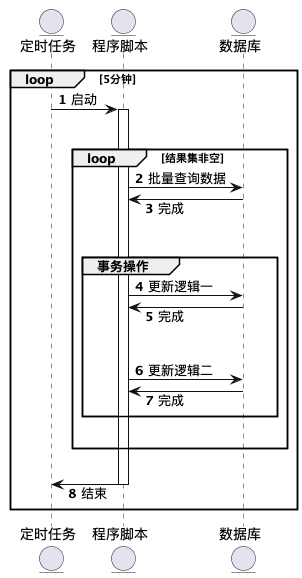
这里有个依赖关系,定时任务调用脚本启动进程以后,程序的退出依赖于批量查询的结果是否为空,如果结果集一直不为空的话,那么进程将一直无法退出,而这并不会影响下一次定时任务的正常执行,其结果就是每一次通过定时任务启动的进程都变成了无法退出的 守护进程,要想退出除非奇迹出现 —— 查询结果集为空主动退出或者 try 外层抛出异常导致程序退出。
是什么原因会导致查询结果集一直不为空呢?try catch + 事务。
仔细看一眼代码逻辑不难发现,代码的异常处理逻辑放在了批量查询的内层,当内层的更新逻辑报错时,事务回滚,这就导致批量查询的数据无法正常更新,但是并不会影响到下一次批量查询的执行。因此也就形成了 批量查询 -> 事务启动 -> 程序异常,事务回滚 -> 下一次批量查询 的恶性循环。
真相是不是真的像我们所说的一样呢?所幸程序中在内层抛异常的位置都有打印日志,根据关键字去搜索日志,果真和我们预测的一样 —— 在更新用户佣金的位置,因为找不到对应数据,导致更新失败(可能是异常数据被特殊处理了)。同时我们还意外地发现,每天记录的日志文件大小达到了 3 个G左右,每天报错记录的行数更是达到了 500 万行之多,不可思议!!!
明确了问题所在,接下来就是考虑如何进行优化了。
其实优化思路并不难,只要将这种 循环批量获取 的方式改为 循环分页获取 就可以了,示例如下:
...
$page = 1;
$pageSize = 50;
while (1) {
// 分页查询多条记录,参数依次为:查询条件,返回字段,分页,分页大小
$list = $this->orderModel->getMoreWithPage($condition, ['*'], $page, $pageSize);
if (!$list) {
break;
}
$page++;
...
}说明:这里还有其他优化的细节,因为不是这里讨论的重点,所以不再展开优化。
或许看到这里,你还会有些许疑问:虽然改成分页查询,但是因为更新逻辑存在问题,每一次定时任务不还是会执行重复的查询吗?没错,但是这样优化完以后,我们的定时任务现在可以在执行完每次的查询后主动结束进程,从而避免了上百个进程同时调用 MySQL 查询的 堵车情况 ,MySQL 的负荷自然也不会高的离谱。
优化完代码以后,我们又清理掉多余的进程,然后迫不及待地刷新着 MySQL 监控页面,等待奇迹发生!结果和预期一致:
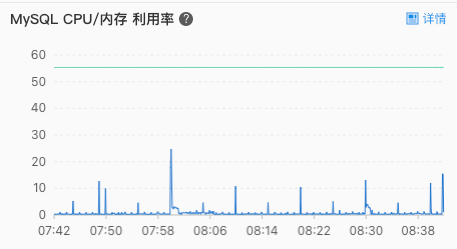
看着降下来的曲线,这感觉,一个字:爽!
总结
通过处理这个问题,我们可以总结到以下经验:
- 使用定时任务执行批量查询时,一定要考虑程序是否会主动退出。如果程序存在无法主动退出的可能,带来的后果将是不可估量的。
- 纵观全局,出现这种问题的主要原因是在编码的时候缺乏程序扩展性的考虑,特别是在团队协作开发的时候。站在历史发展的角度思考,一开始编码人员可能考虑到只有一个更新订单表的操作,出现
可查询不可更新事件的概率性极低,所以才选择了这种简单的批量处理方案,而且上线初期确实也没有出现异常问题。但是某一天另一个开发人员需要在自动确认收货的逻辑里追加一些佣金处理逻辑,发现有现成可用的脚本,于是稍加调整,改成了上面代码的样子。自此,潘多拉魔盒已经悄然准备就绪,只等一个被打开的机会。 - 代码的作者在编写上述逻辑时,可能受到
队列处理思路的影响,脑海中首先想到的就是push and pop操作,再换成从 MySQL 中获取数据,结合定时任务的处理逻辑不就 OK 了么。这是我推测的结果,如果被我不幸说中的话,那我想给作者温馨提示一下,在队列的处理逻辑里,进程是以守护进程的形式存在的,定时任务或者手动启动只是作为队列的启动或者重启方式。在不考虑多进程的情况下,在处理逻辑中必须有进程状态的判断逻辑,这样做的目的就是为了避免无限开启进程。如果考虑通过多进程增加处理效率的话,redis 队列本身因为具有原子性的特性,多开进程尚无大碍。而 MySQL 则一般需要通过特殊的逻辑处理(比如通过进程编号对数据取模处理)来保证操作的原子性。 - 优秀的代码是需要充分考虑
扩展性的,扩展性越强,其维护成本越低。反之,随着时间的推移和系统复杂性的增加,带来的后果可能是灾难性的。
本作品采用《CC 协议》,转载必须注明作者和本文链接













































 关于 LearnKu
关于 LearnKu




推荐文章: