
Redis 实用小技巧—— bitmap 应用之「签到统计」
46 / 14 / 创建于 3年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
简介
在上一篇文章《Redis 实用小技巧—— bitmap 应用之「缓存穿透」问题的处理》中,我们了解到了「缓存穿透」的原理以及如何通过「布隆过滤器」来解决这种问题。在接下来的文章中,我们再来讨论一个老生常谈的问题 —— 如何借助 bitmap 解决「签到统计」相关的问题。
话不多说,准备发车~
签到统计
「签到统计」的场景一般如下:
用户在系统中每天都有签到行为,需要统计用户在某一天是否签到,用户在一段时间内的签到天数(比如统计某个自然月的出勤率),某段时间内整体用户签到情况。
以上就是签到统计场景中经常遇到的几种情况。
如果使用 MySQL 存储的话,一方面数据量会比较大,另一方面统计查询的时候,速度会比较慢。
这种场景,我们可以考虑使用 bitmap 实现,毕竟「海量数据」+「存在与否」两大要素都已经满足了。
现在,我们就来看看用 bitmap 如何实现。
实际上,理解了布隆过滤器的原理以后,再来理解签到问题就相对简单的多了(这也是为什么我们把布隆过滤器放到开始讲的原因)。
bitmap 纬度设计
在我看来,「签到统计」的难点在于 bitmap 的设计。这里我们尝试从几个不同的维度来设计 bitmap 。
需要说明的是,我们并没有引导你直接使用哪种「最优」的解决方案,那并不是我们的初衷。我们会在一步步讨论中,「探索」出一种看上去更「合理」的方案。
针对签到这种场景,我们可以从三个维度来设计 bitmap 。
时间纬度
我们可以按照日期来设计 bitmap 的 key ,如:USER_SIGN:20230615,以用户 ID 作为偏移量。如果 ID 为 1000 的用户在 2023年6月15日签到过的话,则会执行以下操作:
> SETBIT USER_SIGN:20230615 1000 1这样设计的话,我们可以很方便地统计用户在某一天是否签到,如下:
> GETBIT USER_SIGN:20230615 1000 或者统计某一天有多少用户签到,如下:
> BITCOUNT USER_SIGN:20230615但是不好的地方是,每一天都需要一张 bitmap 来存储,一年则需要 365 张 bitmap 。一张 bitmap 按 512 MB 算的话(假设最高位不幸被占用),一年的存储需要分配 186880 MB ,即 18 GB 之多。
而且,当我需要统计某个人在某段时间内的签到情况的时候,会变的比较复杂:需要依次获取区间内每一张 bitmap 表的签到情况,然后再通过代码逻辑来处理。
用户纬度
我们还可以按照用户的纬度来设计 bitmap 的 key ,如:USER_SIGN:1000,以签到日期作为偏移量。
这里我们可以设定一个初始日期,然后以统计日期距离初始日期的差值作为偏移量。假设初始统计日期是2023年6月1日,那么 ID 为 1000 的用户在2023年6月14日签到过的话,则会执行以下操作:
> SETBIT USER_SIGN:1000 13 1这样做的好处是,我们可以很方便地统计用户在某一天是否签到,如下(判断 ID 为 1000 在2023年6月14日是否签到):
> GETBIT USER_SIGN:1000 13 以及用户在某段时间内的签到的情况,如下(统计 ID 为 1000 的用户在2023年6月1日到2023年6月14日之间的签到天数):
> BITCOUNT USER_SIGN:1000 0 13但是不好的地方是,每个用户都需要一张 bitmap 来存储,如果有 1000 万用户的话,则需要 1000 万张 bitmap 来存储,而如果一张 bitmap 按 512 MB 算的话(尽管现实中等不到那一天),总共需要分配 200000 * 512 MB 的空间,具体是多少就不计算了,相信那已经超出了 Redis 的承受范围。
而且,当我们需要统计某一天内所有签到的人数时,也是比较麻烦的。需要遍历所有用户在某一天的签到情况,20 万用户遍历一遍,想想就觉得恐怖。
混合纬度
通过「时间维度」和「用户维度」来设计 bitmap ,我们发现各有利弊(尽管我们的担心在实际场景中可能不会遇到),那能不能把两者结合一下,直接用一张 bitmap 表搞定呢?
我们先来看看在内存分配方面能不能满足。一张 bitmap 表能够存储 2^32 - 1位数据,大概 42.9 亿的数据。假设我们有 1000 万用户的话,按用户每天都签到来统计,一年的数据量大概在 36.5 亿的数据,也是基本可以满足的(如果不满足的话,我们可以缩短 bitmap 的统计周期,比如半年存一张 bitmap )。
接下来,我们看看如何「分配空间」的问题 —— 这是一个需要花时间考虑的问题。
我们先来个简单暴力点的设计。
假设我们按照 1000 万用户的上限来设计,我们将 0 ~ 1000万 - 1 的位置记录全部用户在初始化日期(以2023年6月1日为例)的签到,1000万 ~ 2000万 - 1 的位置用来记录全部用户 2023年6月2日的的签到。以此类推,按照我们的预算,在一张 bitmap 上分配一年的空间也是足够的。如下图所示:
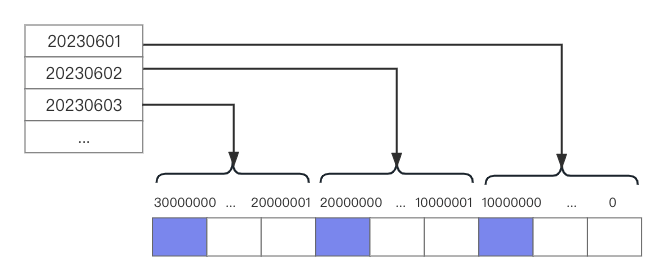
接下来我们要做的就是存储了。
当 ID 为 1000 的用户在2023年6月15日进行签到时,我们需要做四件事:
- 确定日期所在区间的起始偏移量位置。签到日期是2023年6月15日,则该日期所在的区间相对于起始日期(2023年6月1日)的偏移量为 14。
- 确定用户 ID 在日期所在区间内的偏移量。假设用户的 ID 为 1000,则用户在日期所在区间内的偏移量为 1000。
- 确定用户 ID 在整体区间的偏移量。计算公式为:日期区间偏移量 * 日期区间大小 + 用户在日期区间内的偏移量。这里计算结果为:14 * 1000万 + 1000 = 140001000 。
- 设置 bitmap 值:
SETBIT USER_SIGN 140001000 1
存储完数据以后,接下来就开始考虑如何实现我们的统计需求了。这里我们看看前两个维度中遇到的统计需求,能不能一一解决。
首先判断用户在某一天是否签到。这里我们根据统计日期的偏移量和用户的 ID 计算出用户在这一天签到对应的偏移量(存储步骤中已经介绍),然后通过 GITBIT 就可以判断了。如下:
> GETBIT USER_SIGN 140001000然后是某一天有多少用户签到的场景。我们根据统计日期计算出该日期对应的偏移量的起始和截止位置,然后通过 BITCOUNT 命令即可得到结果:
> BITCOUNT key [统计日期起始偏移量] [统计日期截止偏移量]接下来,让我们统计用户在一段时间内的签到情况。这种情况稍微有点复杂了,不过还算 OK 。
首先我们需要计算出用户在这段时间内所有的偏移量情况。这里我们通过公式,很容易就可以求出来(如果数据量多的话,就多求一会)。
接下来,我们需要查询出这些偏移量位置上 bit 位的设置情况。
你可以使用 GETBIT 的方式分多次查询。当然,如果数据量如果在可控范围内的话(不超过 Redis 单次请求的载荷),建议你使用 PIPELINE 的方式进行查询,如下(以 laravel 实现为例):
/**
* 混合维度统计签到
*
* @param array $offsets 偏移量列表
* @return mixed
*/
public function signCountByMix(array $offsets)
{
return $this->client->pipeline(function ($redis) use ($offsets) {
foreach ($offsets as $offset) {
$redis->getbit($this->bucket, $offset);
}
});
}这样,我们就能够拿到我们想要的结果了。
这种方案看似已经解决了「时间维度」和「用户维度」不易解决的问题,但是并不算理想。因为这种按假定上限「平均分配」的方法很容易受到上限的限制:比如我们的用户量突然突破了 1000 万该怎么办?这样原有的已经定好的规则就被打破了。这显然不是一个「合理」的方案。
其实,只要我们把日期这个区间做成「动态浮动」的空间,这个问题就迎刃而解了。那该怎么「浮动」呢?
我们可以在每次初始化日期区间的时候,顺便记录下当前日期的最大的偏移量位置。当用户签到时,我们会拿用户 ID 计算出用户在当前日期区间内的偏移量位置,然后和记录的截止偏移量位置进行比较,如果超出了记录的值,则进行替换。这样,在次日进行统计时,会以上一次记录的截止偏移量位置作为次日的起始偏移量的位置,重复之前的过程。如下图所示:
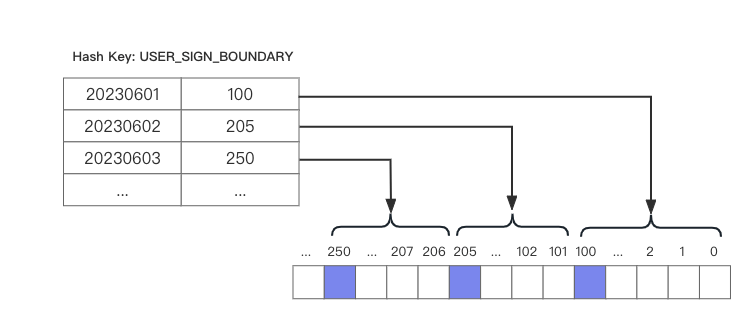
这样做,我们的日期区间分布就成了「动态浮动」的了,而且比起之前的方案来,不仅灵活,能表示的范围也更大了。
不过,因为现在日期区间的边界是保存在记录中的了,所以在计算具体的偏移量时,我们需要先从记录中把所有日期的偏移量位置查出来,然后进行计算。我们用 Hash 来存储这些信息,用日期来作 Field ,每天保存当天最大的偏移量(即最大的用户),这样每次统计的时候,直接 HMGET 获取到所有日期的偏移量信息,也不会有什么压力。
这样设计,看似存储上「更为合理」了,但是实现逻辑上却变的复杂了。
比如,我们要判断用户在某一天是否签到:我们需要先计算出用户在这一天的偏移量,计算思路与优化前的思路一样。不同的是,这里我们取日期的偏移量的时候,需要从 Hash 中进行获取。
计算用户在某段时间内的签到情况的时候,也需要先通过程序计算出用户在这段时间内具体的偏移量,然后再进行批量获取。
如果需要统计某一天内所有的签到用户数,我们只需要拿到这一天的起始(上一条记录的截止偏移量)和截止偏移量,然后进行 BITCOUNT 运算即可。
到这里,看似所有的问题都得到了完美的解决。难道这就是「最合理」的方案了么?
其实不然。
在日常开发中,还有一种常见的统计场景:统计在某段时间内连续签到的用户。特别是对于经常玩游戏的小伙伴肯定不陌生 ——「连续签到七天,大奖等你来拿」,是不是很熟悉?
对于这种场景,我们这种方案貌似就不那么「灵通」了 —— 因为我们在一张 bitmap 上通过偏移量即表达了时间,又表达了用户。我们在解决统计的问题时,是借助了命令和程序来处理的。这对于可控的区间统计是可以接受的,但是这里我们需要遍历每一个 bit 位来获取用户的签到信息,然后通过运算得到最终的结果。这笔开销无疑还是很大的。
额。。。难道忙活了半天,白忙活了么?
返璞归真
其实,我们在一步步升级我们方案的过程中,都是以理论作为升级的「标尺」。但是理想的风花雪月,总要回归现实的锅碗瓢盆。
过日子,讲究的是「实际」。
现在,我们回头来看「时间维度」这个设计。
在这个维度的讨论中,我们列举了两条限制因素:存储空间和时间区间内用户签到的统计。
我们当时是按照 bitmap 最大的内存开销来假设的,即 512 MB 。这个空间能存储大约 42.9 亿的数据量,假设我们的用户量有1亿的话,实际分配的空间只有 12 MB 左右,一年占用的空间大概 4.3 GB 左右。虽然也很大,但是这种签到数据,我们可能不需要保存这么久,所以实际占用的空间可能会更小。
针对另一个限制条件,如果我们要统计某段时间内,用户的签到情况,通过 pipeline 批量处理的话,开销也不是很大。
关键点来了:现在如果需要统计某段时间内连续签到的用户,在这种方案下就变的简单多了。我们只需要通过 BITOP 进行 AND 的位运算操作就可以了,如下:
> BITOP AND USER_CONTINUAL_SIGN USER_SIGN:20230601 USER_SIGN:20230602 [USER_SIGN:20230603 ...]然后我们可以通过 BITCOUNT 统计连续签到的用户数,或者通过程序结合 pipeline 依次获取连续签到的用户信息。
看到没有,兜兜转转,我们又回到了起点 —— 「不忘初心,方得始终」。
当然,如果你的用户存储使用了分表逻辑的话,无法通过一个主键 ID 来代表唯一用户的话,可以考虑通过一个映射算法或者通过 Redis 「自增发号器」来给每个用户分配一个唯一的 ID 。这里不推荐使用之前「布隆过滤器」的映射算法,一是存在冲突的可能性,二是太分散对于存储空间不够友好。
好了,到这里,关于「签到统计」就要告一段落了。
总结
在这篇文章中,我们讨论了针对「签到统计」的一些设计方案。
我们从「时间维度」、「用户维度」和「混合维度」三种不同的维度来分析了实现的一些细节。这里的处理思路与之前文章中讨论的「布隆过滤器」有所不同。
首先,「布隆过滤器」主要是为了解决「存在与否」的问题,而「签到统计」除了解决「存在与否」的问题,可能还会牵扯到「位运算」(比如「时间维度」中,我们需要统计某段时间内连续签到的用户),这种情况下「布隆过滤器」的解决思路就不合适了。
其次,「签到统计」是面向多个维度的。在本文中,我们就讨论了「时间维度」和「用户维度」两个具体的维度。这也是「布隆过滤器」的场景中不需要重点关心的。
用一句话总结「签到统计」的处理思路就是:
通过合理地规划 bitmap 的布局,在满足存储空间的前提下,借助 Redis 命令和程序,更加高效合理地处理各种常见的签到场景。
在下一篇文章 《Redis 实用小技巧—— bitmap 应用之「位排序」》中,我们将以「位排序」这个小场景作为我们系列文章的收篇之作。
感谢各位的持续关注~
本作品采用《CC 协议》,转载必须注明作者和本文链接





























 关于 LearnKu
关于 LearnKu




推荐文章: