
golang gin框架集成Prometheus+grafana+alertmanager监控系统
6 / 2 / 创建于 2年前 /
 Patienter 的个人博客
Patienter 的个人博客
1. Prometheus+grafana+alertmanager环境准备
使用docker-compose安装环境
目录文件为:
data
server
----alertmanager
--------templetes
------------wechat.tmpl
--------alertmanager.yml
--------Dockerfile
----grafana
--------Dockerfile
----prometheus
--------Dockerfile
--------group.yml
--------nodes.json
--------prometheus.yml
----.env
----docker-compose.yml详细的文件内容
alertmanager文件下的文件详情
wechat.tmpl
{{ if gt (len .Alerts.Firing) 0 -}} =========================== 监控报警 =========================== 警报触发通知: {{ range .Alerts}} 告警级别: {{ .Labels.severity }} 告警类型: {{ .Labels.alertname }} 异常告警通知 故障主机: {{ .Labels.instance }} 告警主题: {{ .Annotations.summary }} 告警详情: {{ .Annotations.description }} 异常 触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} =========================== = end = =========================== {{- end }} {{- end }} {{ if gt (len .Alerts.Resolved) 0 -}} =========================== 异常恢复 =========================== 警报恢复通知: {{ range .Alerts}} 告警级别: {{ .Labels.severity }} 告警类型: {{ .Labels.alertname }} 异常恢复通知 恢复主机: {{ .Labels.instance }} 恢复主题: {{ .Annotations.summary }} 触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} 恢复时间: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} =========================== = end = =========================== {{- end }} {{- end }} {{- end }}alertmanager.yml
global: resolve_timeout: 1m #当报警被解决时,AlertManager 将等待一段时间以确保问题已经解决。这个配置项用于设置等待的时间限制 smtp_smarthost: 'smtp.qq.com:465' smtp_from: '1015693563@qq.com' smtp_auth_username: '1015693563@qq.com' smtp_auth_password: '邮箱授权码' smtp_hello: '@qq.com' smtp_require_tls: false route: group_by: [alertname] #通过 alertname 的值对告警进行分类,- alert: 物理节点 cpu 使用率 group_wait: 10s #一组告警第一次发送之前等待的延迟时间,即产生告警后延迟 10 秒钟将组内新产生的消息一起合并发送(一般设置为 0 秒 ~ 几分钟)。 group_interval: 2m #一组已发送过初始通知的告警接收到新告警后,下次发送通知前等待的延迟时间(一般设置为 5 分钟或更多)。 repeat_interval: 2m #一条成功发送的告警,在最终发送通知之前等待的时间(通常设置为 3 小时或更长时间)。 #间隔示例: #group_wait: 10s #第一次产生告警,等待 10s,组内有告警就一起发出,没有其它告警就单独发出。 #group_interval: 2m #第二次产生告警,先等待 2 分钟,2 分钟后还没有恢复就进入 repeat_interval。 #repeat_interval: 5m #在最终发送消息前再等待 5 分钟,5 分钟后还没有恢复就发送第二次告警。 receiver: wechat templates: - '/etc/alertmanager/templates/*.tmpl' # Alertmanager微信告警模板 receivers: #定义接收者 - name: 'wechat' #企业微信接受者 wechat_configs: - corp_id: {替换成自己的corp_id} message: '{{ template "wechat.default.message" . }}' # to_user: '@all' #定义发送给公司组织架构下所有人 to_user: '' #定义发送给公司的指定人,多人使用|连接示例:1221|1232121231 # to_party: 2 #定义发送给组织架构下组ID为2的所有用户 agent_id: {微信应用机器人的agent_id} #定义微信应用机器人的agent_id api_secret: {企业微信应用的secret} #定义 send_resolved: true #报警恢复通知 inhibit_rules: #抑制的规则 - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']Dockerfile
FROM prom/alertmanager:latest
grafana的文件详情
- Dockerfile
FROM grafana/grafana
prometheus 文件详情
Dockerfile
FROM bitnami/prometheusgroup.yml
groups: # groups:组告警
- name: general.rules # name:组名。报警规则组名称
rules: # rules:定义角色
- alert: 服务器服务 # alert:告警名称。 任何实例5分钟内无法访问发出告警
expr: up == 0 # expr:表达式。 up = 0 相当于指标挂掉了
for: 10s # for:持续时间。 表示持续一分钟获取不到信息,则触发报警。0表示不使>
labels: # labels:定义当前告警规则级别
severity: error # severity: 指定告警级别。
annotations: # annotations: 注释 告警通知
# 调用标签具体指附加通知信息
summary: "{{ $labels.job }}服务状态" # 告警主题
description: "{{ $labels.job }}" #告警详情- nodes.json
[{
"targets": [
"127.0.0.1"
],
"labels": {
"datacenter": ""
}
}]- prometheus.yml
global:
scrape_interval: 15s # # 默认抓取周期
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration 告警地址
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.21.23:9093']
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/opt/bitnami/prometheus/conf/group.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: '服务' #服务的名称
scrape_interval: 5s
metrics_path: /metrics #获取指标的url
file_sd_configs: #替换static_configs
- files:
- /opt/prometheus/config/nodes/nodes.json #指定文件路径
refresh_interval: 10s #重新加载文件列表目标时间间隔 .env配置示例
# 设置时区
TZ=Asia/Shanghai
# 设置网络模式
NETWORKS_DRIVER=bridge
# PATHS ##########################################
# 宿主机上数据存放的目录路径
DATA_PATH_HOST=../data
# PROMETHEUS #####################################
# Prometheus 服务映射宿主机端口号,可在宿主机127.0.0.1:3000访问
PROMETHEUS_PORT=4000
# alertmanager #####################################
# alertmanager 服务映射宿主机端口号,可在宿主机127.0.0.1:9093访问
ALERTMANAGER_PORT=9093
# GRAFANA ########################################
# Grafana 服务映射宿主机端口号,可在宿主机127.0.0.1:4000访问
GRAFANA_PORT=3000docker-compose.yml
version: '3.5'
# 网络配置
networks:
backend:
driver: ${NETWORKS_DRIVER}
# 服务容器配置
services:
prometheus:
build:
context: ./prometheus
environment:
- TZ=${TZ}
privileged: true
volumes:
- ${DATA_PATH_HOST}/prometheus/prometheus:/etc/prometheus
- ${DATA_PATH_HOST}/prometheus/prometheus_data:/prometheus
- ./prometheus/nodes.json:/opt/prometheus/config/nodes/nodes.json
- ./prometheus/prometheus.yml:/opt/bitnami/prometheus/conf/prometheus.yml # 将 prometheus 配置文件挂载到容器里
- ./prometheus/group.yml:/opt/bitnami/prometheus/conf/group.yml # 将 prometheus 配置文件挂载到容器里
ports:
- "${PROMETHEUS_PORT}:9090" # 设置容器9090端口映射指定宿主机端口,用于宿主机访问可视化web
networks:
- backend
restart: always
# 添加告警模块
alertmanager:
build:
context: ./alertmanager
container_name: alertmanager
ports:
- "${ALERTMANAGER_PORT}:9093"
volumes:
- "./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml"
- ${DATA_PATH_HOST}/prometheus/data/alertmanager:/alertmanager/data
- "./alertmanager/templetes:/etc/alertmanager/templates"
networks:
- backend
restart: always
grafana:
build:
context: ./grafana
environment:
- TZ=${TZ}
volumes:
- ${DATA_PATH_HOST}/grafana/grafana_data:/var/lib/grafana
ports:
- "${GRAFANA_PORT}:3000" # 设置容器3000端口映射指定宿主机端口,用于宿主机访问可视化web
networks:
- backend
restart: always2. gin代码集成
安装prometheus的go的prometheus包
go get github.com/prometheus/client_golang/prometheus/promhttp添加 metrics路由
e.GET("/go/metrics", gin.WrapH(promhttp.Handler()))
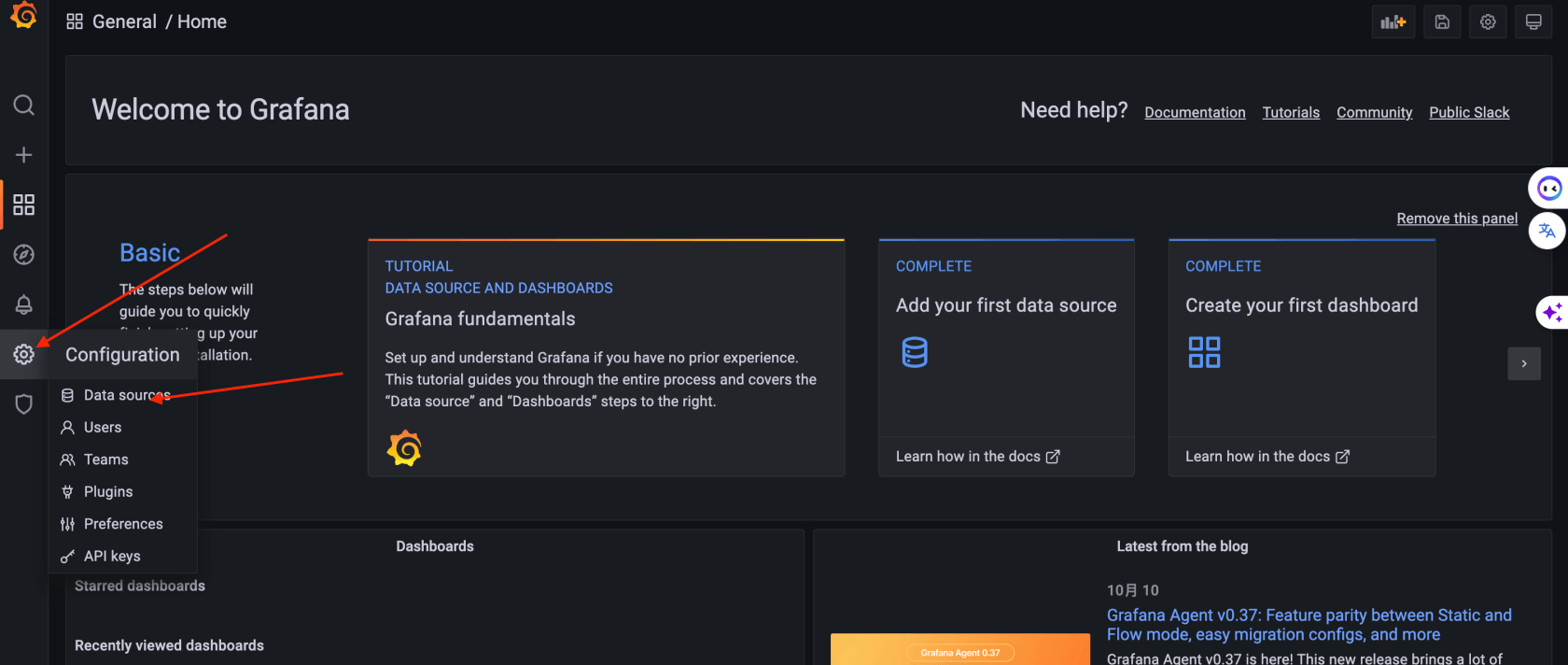
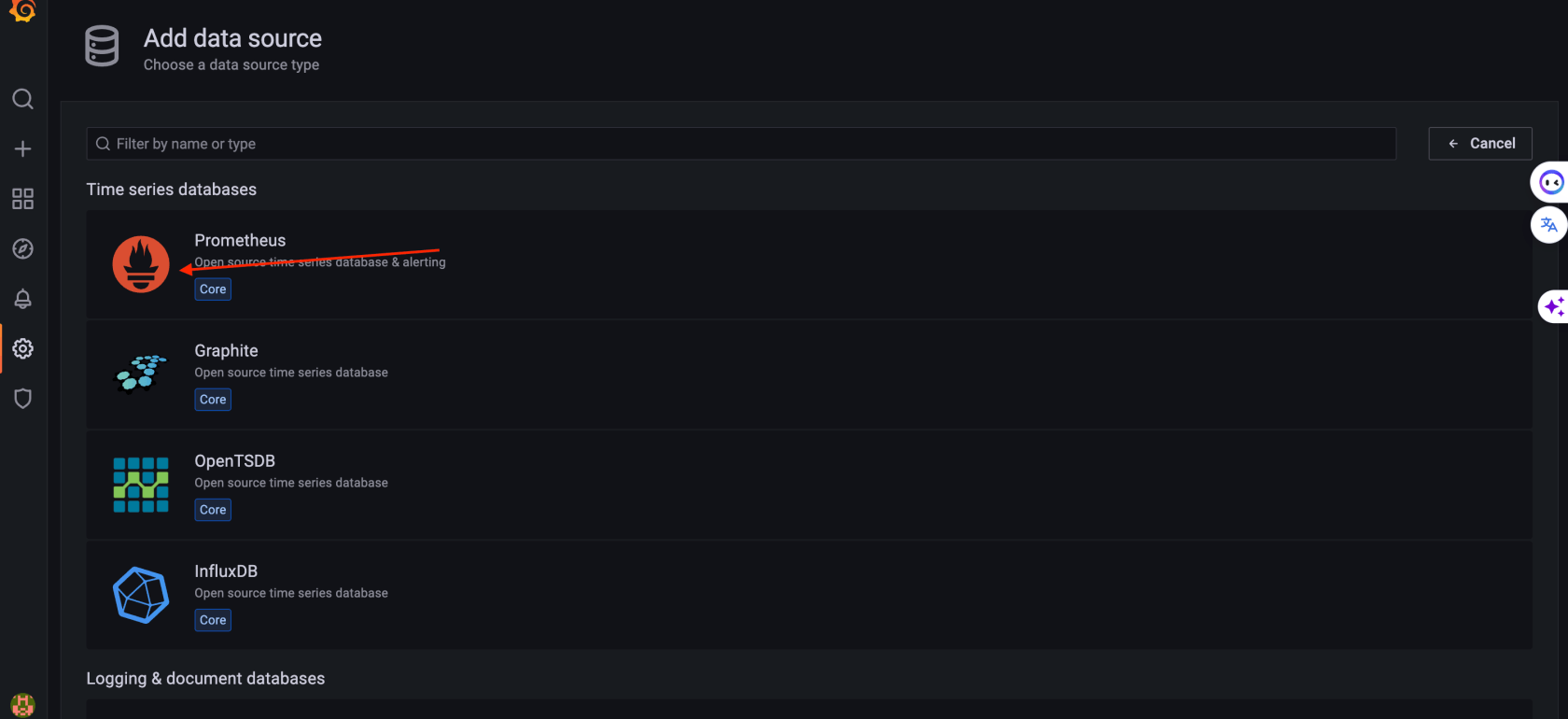
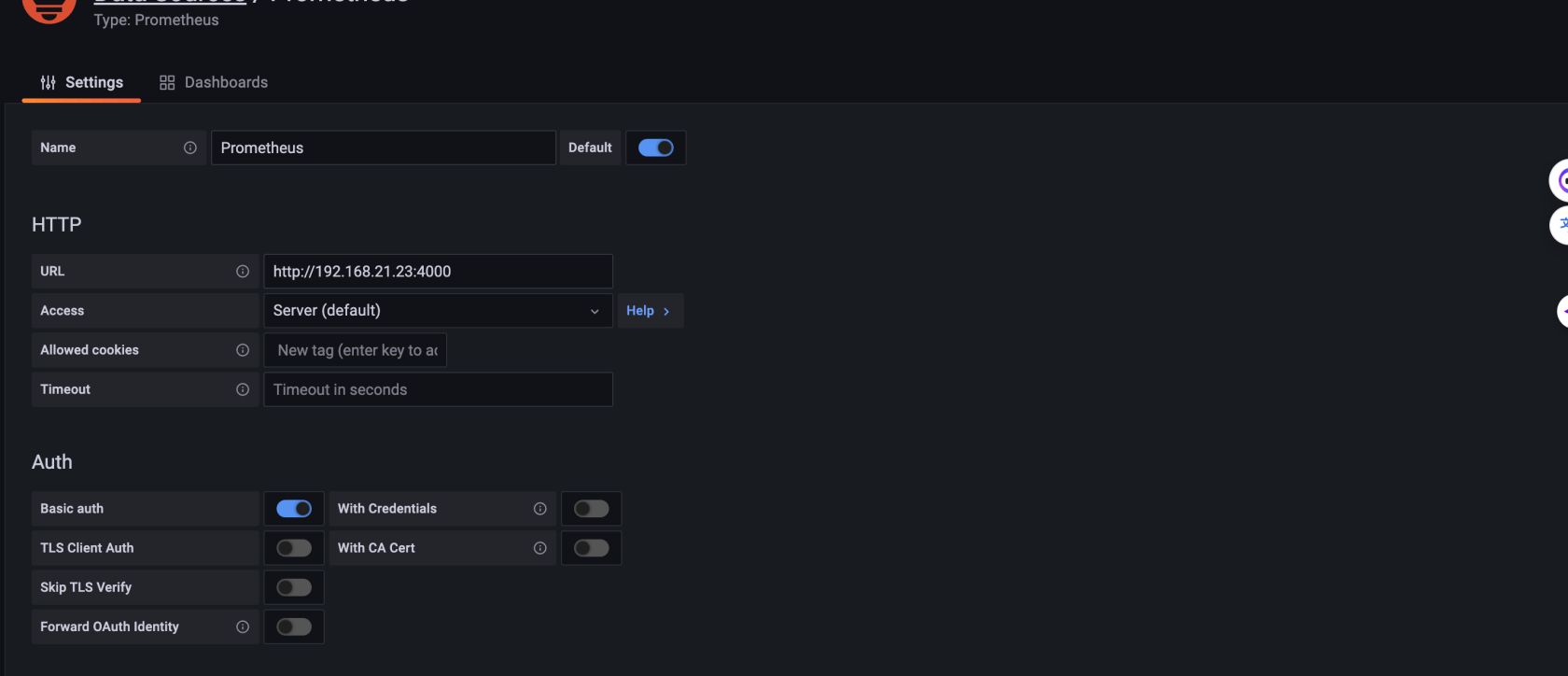
3. 配置grafana面板
配置数据源

添加go指标面板
我是直接在 grafana.com/grafana/dashboards 找的现成的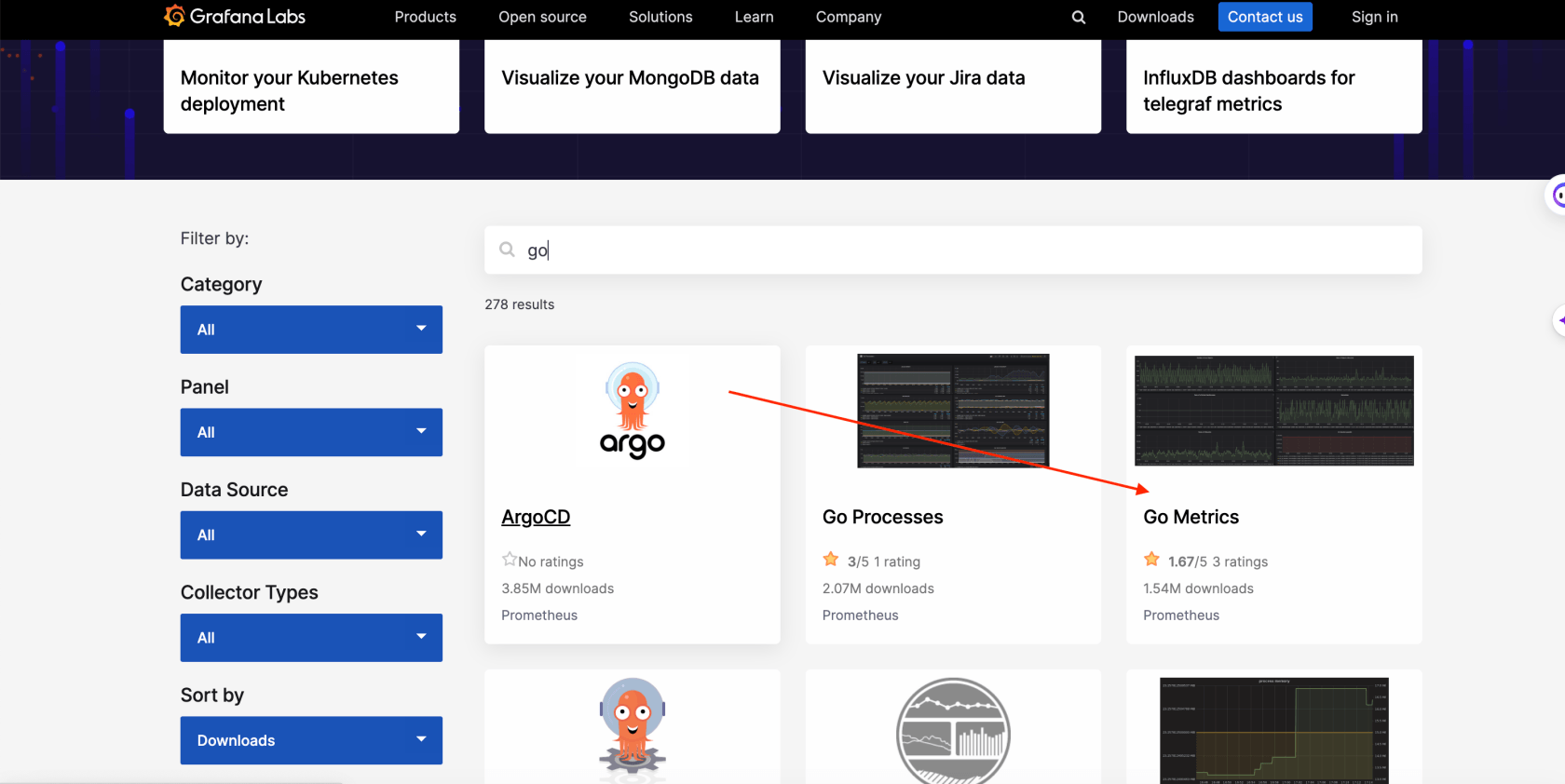
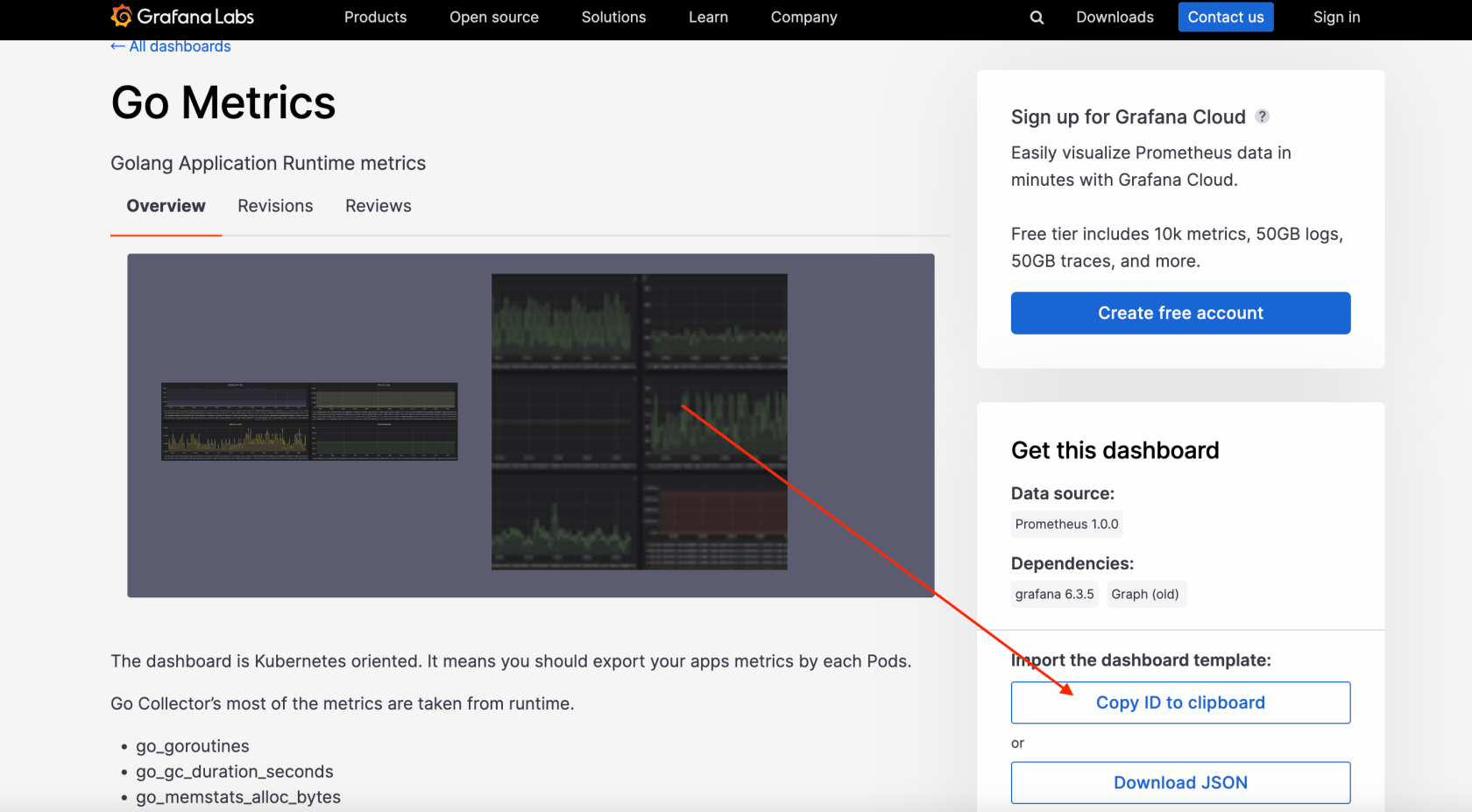
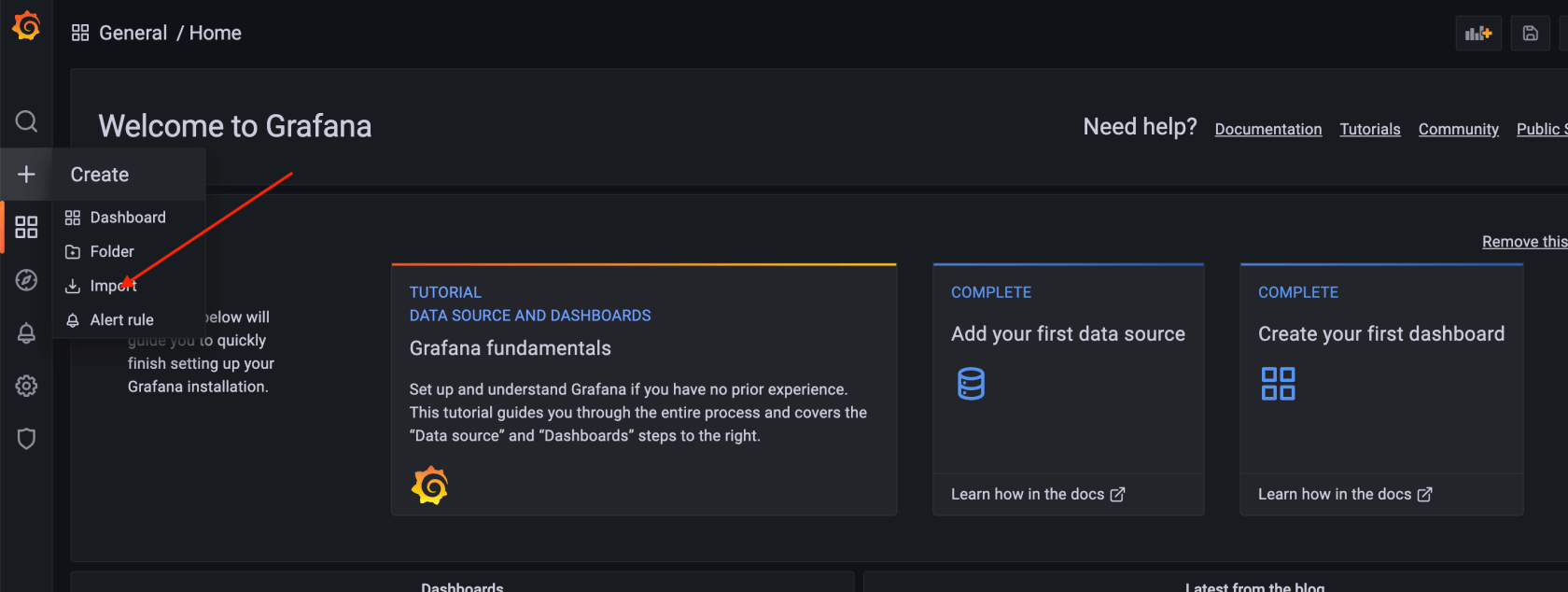
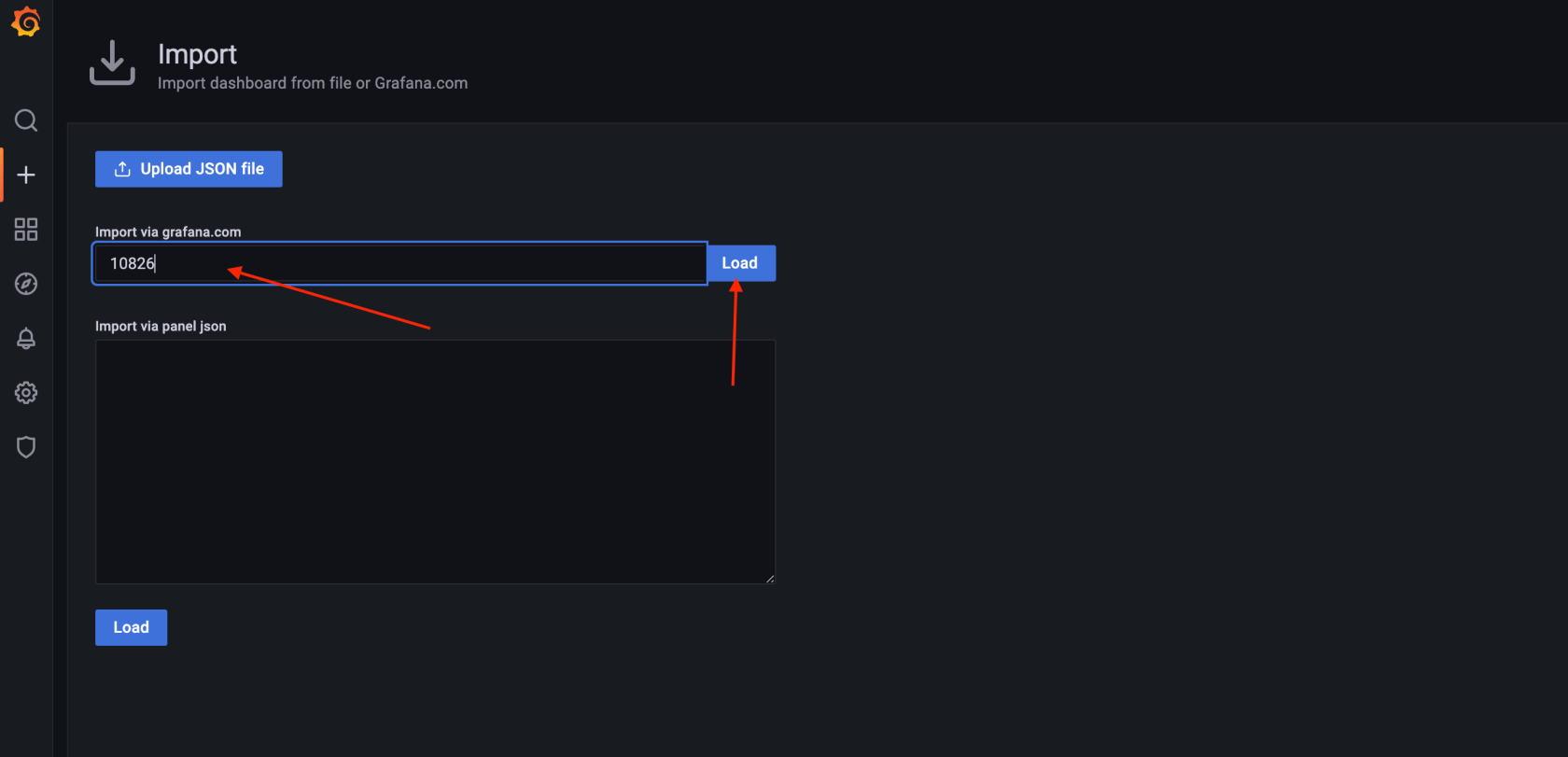



此时面板的的数据还不对,需要我们自己修改

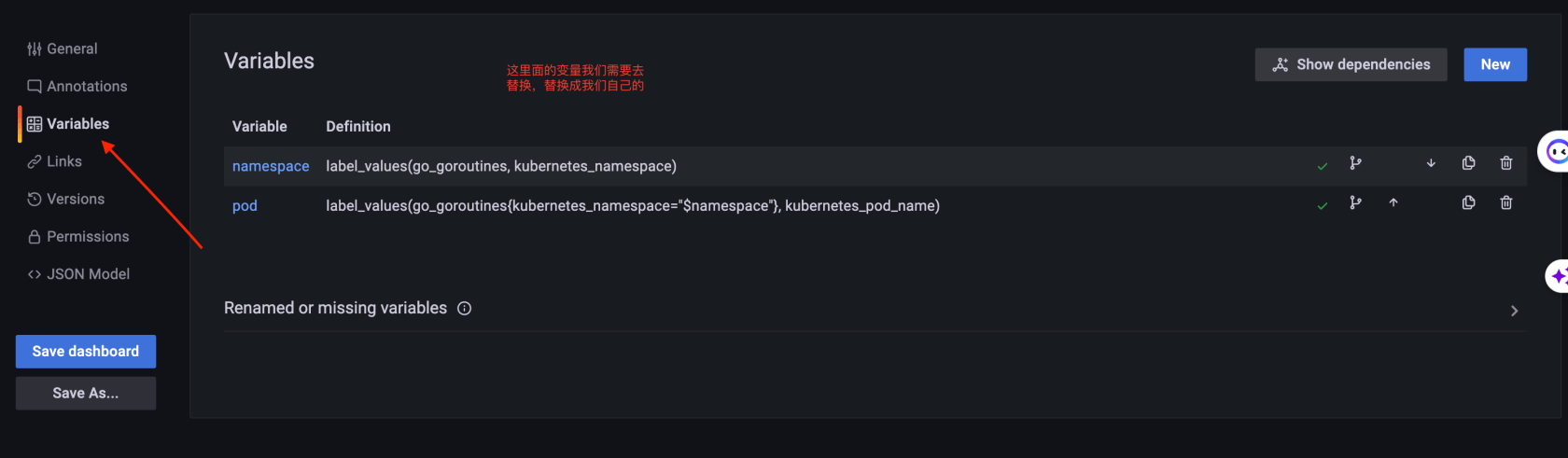
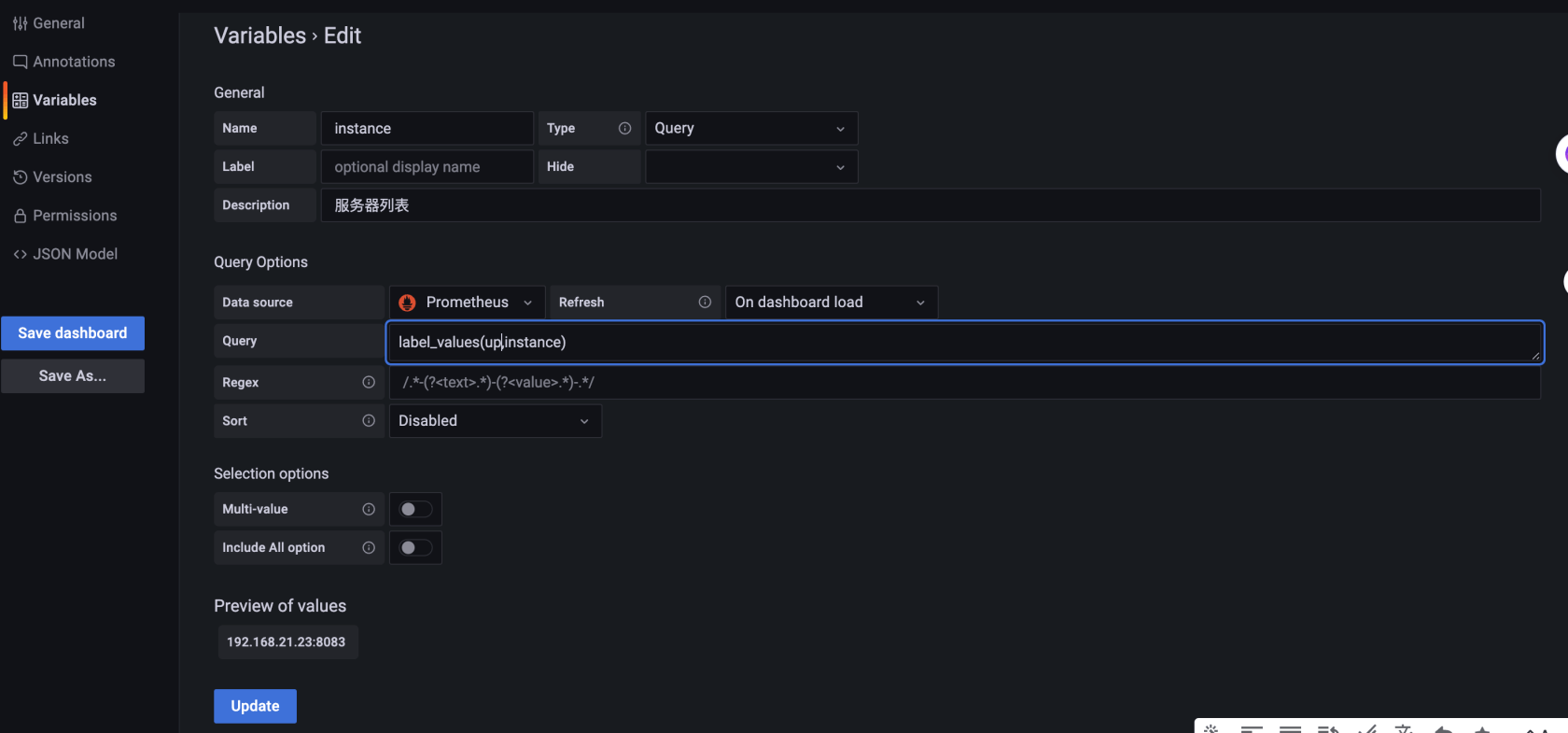
然后编辑我们的所有的面板,把查询{}参数里面的条件换成成如下所示例
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: