
 architect director
architect director 本书未发布
Go - 记录一次性能分析的全过程
前因
刚到这个公司,因为有很多热点账户之间的转账,所以需要处理这个问题。
基本解决思路:DB的批量处理,减少锁的等待时长。
方案
第一个方案
将reqs分配到不同的group,group的reqs满了之后传给executor的worker,worker批量处理这些请求。示意图如下:
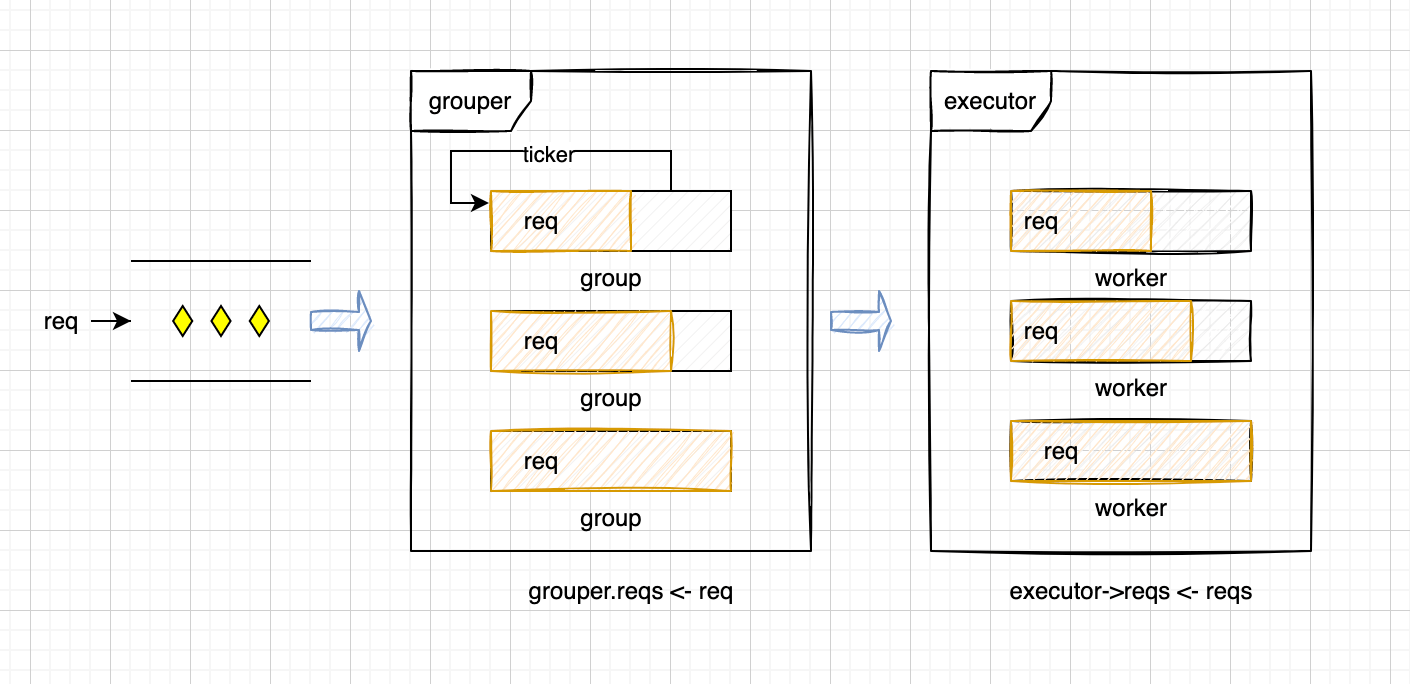
因为是用的Golang写的,所以这里都是异步处理的req。
- 用户的请求会经过grouper分发给group,group之间如果有重复的id会merge到一个group。减少锁冲突。
- group的reqs会传给executor
- executor的reqs会传给worker
- worker通过事务批量处理reqs
第二步group触发的时机有两个:
- reqs的长度达到阈值
- ticker的时间已经到了
事务处理部分:
func (w *worker) do(reqs []Request) {
var err error
response := func(req Request,ret Response, ch RespCh) {
if err != nil {
DB操作
ch <- ret
} else {
DB操作
ch <- errorResp(...)
}
}
Transaction(func(tx *gorm.DB) error) {
for k,v := range reqs {
1. Select .. Where account_id = ? For Update
2. DB 操作
3. defer response(...)
}
}
}缺点:
- Ticker不受控制,group的reqs在不满的请求下也会发送给executor处理。
- reqs的长度过长锁时长难以避免
- 参数调优
- ticker时长影响response
第二个方案
改变触发时机:如果grouper.reqs为空,则触发其他group的reqs提交给executor。这样就可以省去ticker了。
伪代码:
var isEmpty = true
for {
if len(grouper.reqs) == 0 || isEmpty {
req <- grouper.reqs
isEmpty = false
execGroup,poped := handleReq(req)
if poped {
executor.reqs <- execGroup.reqs
execGroup.Reset()
// 为了防止有些group饿死,增加补偿机制
// 找到reqs最少的group,给他的len+1
}
}
for _,v := range grouper.Group {
if len(v.reqs) > 0 {
executor.reqs <- v.reqs
v.Reset()
}
}
isEmpty = true
}优势:
- 避免了ticker不受控制的因素
- group的reqs空间充分利用
- 单条请求响应更快
- 调优参数减少了
缺点:
- reqs的长度过长锁时长难以避免
性能测试
性能测试包括两部分:
- 模拟100个用户随机转账
- 点对点的密集转账
测试过程中,出现过几个现象:
- 优化后的响应时间改善,但是QPS没有显著提升
- 事务锁出现死锁(select .. where id in(?) for update),虽然id已经正序,但是in条件不保证顺序。(第一个失误)改成for循环一个个的加锁。
QPS没有显示提升:
- 事务内的DB操作批量处理,10个请求,每个请求都要insert 2个bill记录,那么就要处理20次。每个SQL处理大约在1.5-2ms,最大也就节省大概40ms-6ms=34ms。第二个失误
- defer response内的DB操作,同样10个请求,处理10次insert,大概需要1.5+ms。每个
respCh <- response也会多等15ms。最大也能节省大概15-3+ms=12ms。第三个失误
改完这3个失误之后,从原来的QPS=80,飙到了QPS=240~300,提升了大概3+倍。奇怪的还有:没处理第二个失误之前,QPS并没有变化,锁等待时间也没变化。但是处理完第二个失误之后,锁等待时间从原来的120ms减到了40ms。提升了3倍。
分析原因
原来的锁等待时长120+ms的原因(10个req):
- 10 * 2(bill) * 2 = 40ms
- 10 * 1.2 = 12ms
优化后:
- insert 大bill SQL:8ms
- insert 大txInfo SQL:2ms
思考:
- 是因为减少了response的响应时间吗?
- IO密集型优化优先考虑减少IO处理时长,如MySQL的处理时长。
- 忽略了大SQL处理带来的性能优化
- 加锁时不能用 in 条件。



 关于 LearnKu
关于 LearnKu



