
 architect director
architect directorKafka特性
框架:概念,消费者,生产者,配置,监控,特性,集群,调优
概念
消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
生产者:Producer。向主题发布新消息的应用程序。
消费者:Consumer。从主题订阅新消息的应用程序。
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
生产者和消费者
生产者生产消息
一个生产者如果只对应一个消费者,可以这样设计: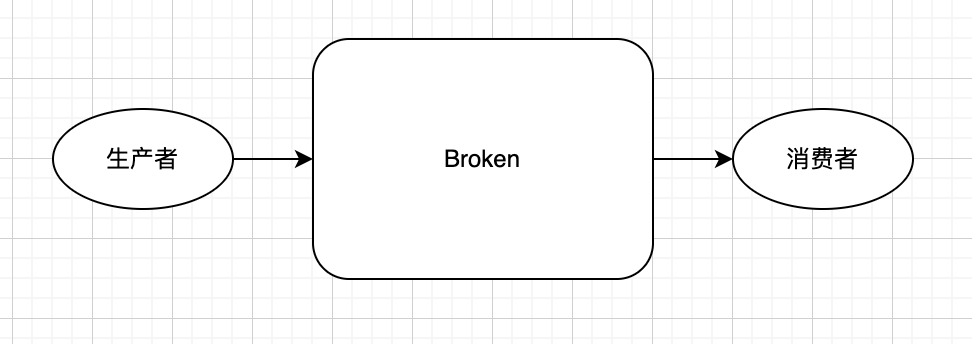
在kafka中:
客户端:生产者,消费者
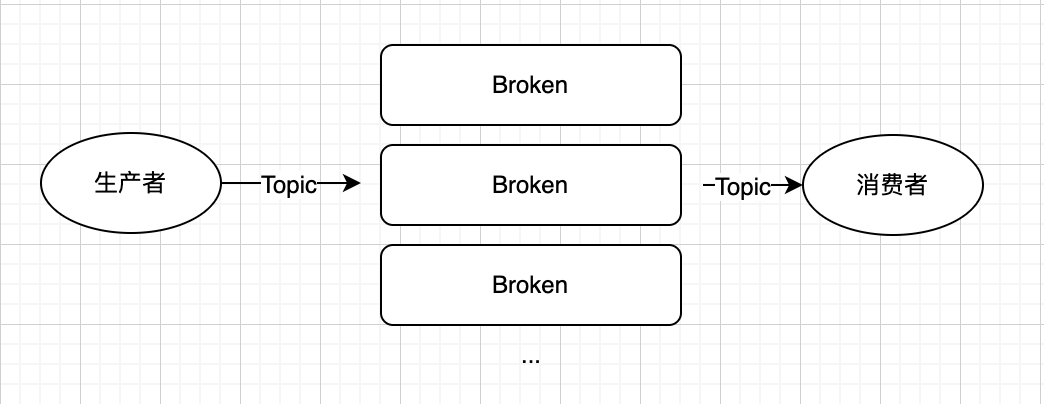
服务端:Broken
生产者可以通过Topic发布消息到多个分区,消费者可以从不同的Broken订阅Topic,从而达到负载均衡。
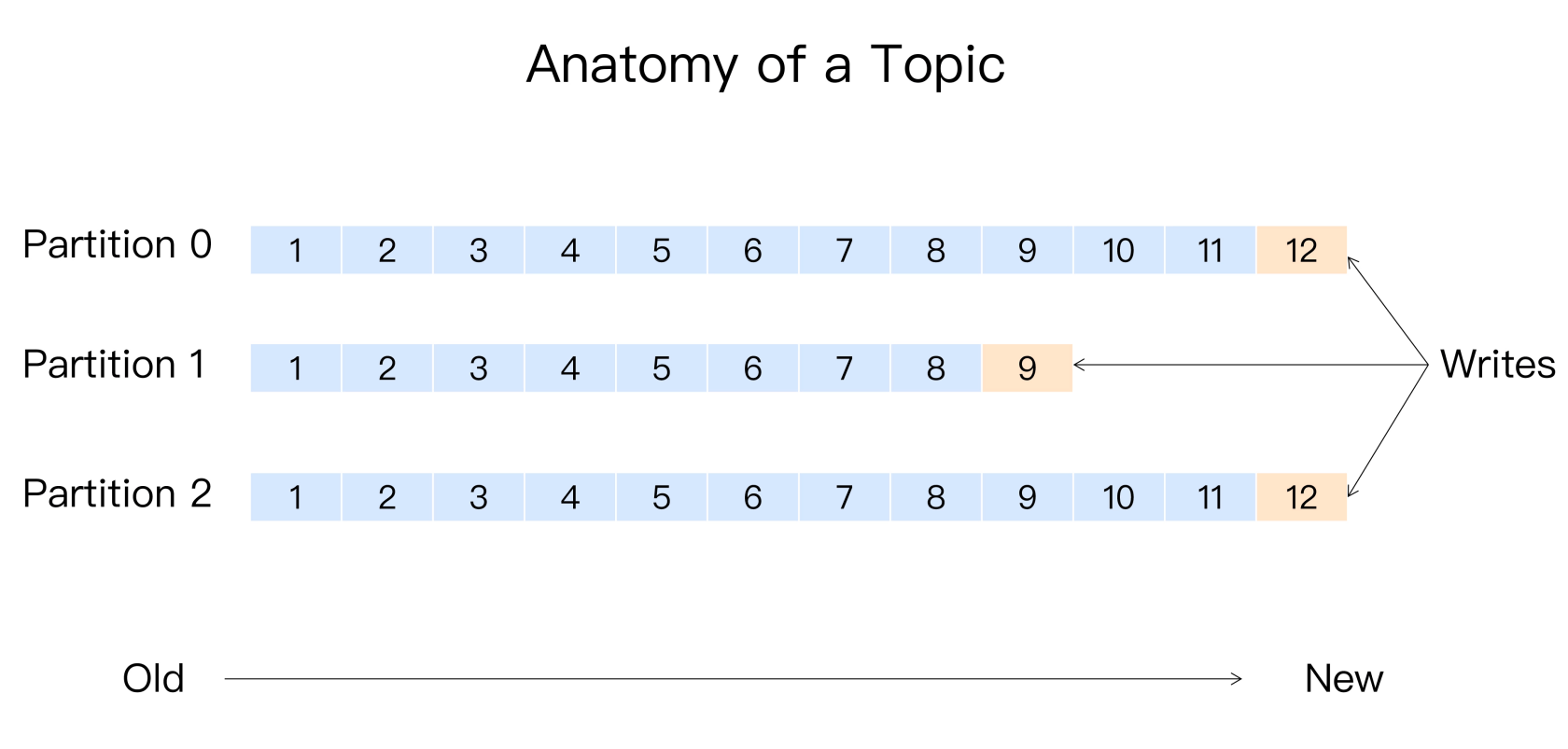
在分区中,每个消息实体都是唯一标识的。通过消息位移的方式消费分区中的消息实体。
分区策略:轮训策略/随机策略/按消息键保序策略/基于地理位置的分区策略/
轮询策略: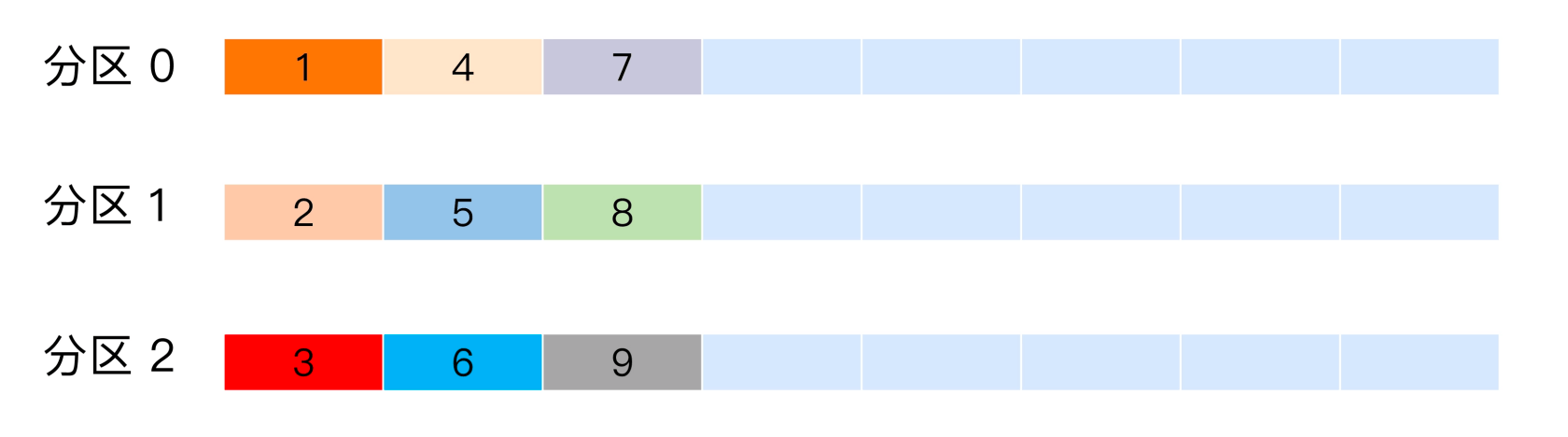
随机策略:
按消息键保序策略: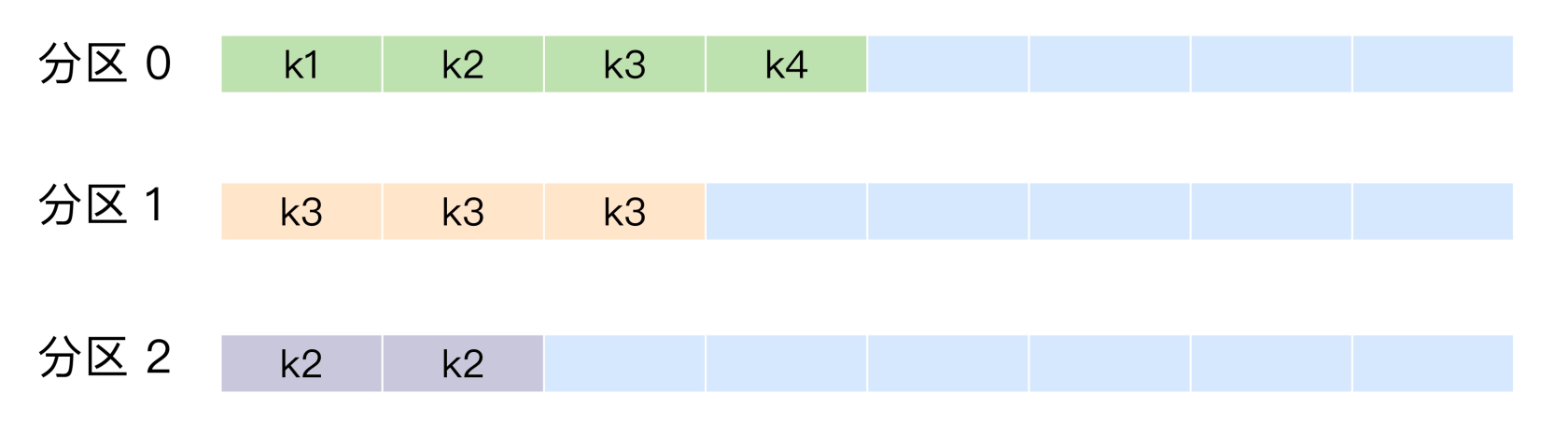
消费者组
消费引擎模型:点对点模型(消息队列),发布/订阅模型。消息队列特性—消息队列模型多个消费者争抢一个消息实例,消息被消费后则从队列中删除。这不是缺陷,只是特性。发布/订阅模型特性—一个消息允许被多个消费者消费,不足之处是消费者需要订阅所有的分区。
伸缩性很差。差在哪里呢?(RabbitMQ的消费者我记得就是消息队列模型)。作者的意思是:Kafka消息组同时实现了消息引擎两个模型的特点—一个分区只有一个组的消费者实例,则认为是消息队列模型。一个分区有多个组的消费者实例,则认为是发布/订阅模型。
而且消费组不需要订阅所有的分区。
一个主题分区需要几个消费者呢?Kafka建议的是一个。如果分区数多于消费者数一个消费者可能对应多个分区,如果分区数小于消费者数,则有消费者会空闲。
这个不是应该还要考虑消费者的消费速度吗?如果消费速度快,一对一已经满足那么这个方案是适合的。如果一对一消费者消费速度慢,导致消息可能积压。这种情况应该是多个消费者更好。在RabbitMQ中可以估算一个消息的消费速度决定要多少个消费者。
Kafka副本机制
副本机制的好处:
- 提供数据冗余(备机)
- 提供多读,提升读效率
- 改善局部访问速度(跨城机房)
Kafka只提供了第一种:数据冗余
Kafka:Broker -> 主题 -> 分区 -> 副本
RabbitMQ:
副本数据一致性如何保障?
(1)从众多副本中推举出leader副本,其余的自然是follower。
(2)leader副本负责数据的读写,follower不提供读写。只同步leader数据。
(3)leader所在broker挂了之后,会重新推举新的leader。旧leader重新接入成为follower。
这么设计的好处?
(1)读写设计简单,主从同步简单。
(2)读一致性(ISR - In Sync Replication):不会出现多次读现象
ISR:落后于leader replica.lag.time.max.ms 之内的follower则放入ISR,否则放入非ISR。ISR这个集合是动态变化的过程。
(3)重新选举:如果leader的副本ISR是空的,那么可以通过参数unclean.leader.election.enable配置是否从非ISR中重新选举leader。CAP理论中是选择C OR A,由这个配置来决定。如果配置true,则数据会丢失,但是保证了高可用性。如果配置false,则弃用高可用性,保证了数据的一致性。
思考题
为什么使用分区的概念而不是直接使用多个主题呢?
Kafka 消息交付可靠性保障以及精确处理一次语义的实现。
所谓的可靠性交付,是Kafka对生产者和消费者的承诺:
- 最多一次:消息可能会丢失,但是绝对不会重复消费。
》只需要禁止Productor重发即可,这样消息要么发送成功,要么发送失败。 - 最少一次:消息可能会重复消费,但是绝对不会丢失。(默认)
》Productor接收到Broken的ack才认为消息发送成功,倘若网络抖动导致Productor没有接收到,则Productor会重发。 - 精确一次:消息不会重复消费,也不会丢失。
》通过两种机制:幂等性和事务。
- 最多一次:消息可能会丢失,但是绝对不会重复消费。
那Kafka是如何实现的呢?已经可以保证精确一次了,为什么还要其他的承诺呢?
个人猜测先:不同的实现性能消耗不一样。如最多一次速度更优,无需接收Broken的ACK。最少一次需要接收Broken的ACK并且可能重发。而精确一次则需要保证幂等性和事务,性能消耗和速度会更差。
不同的承诺对应的业务场景不同:最多一次—如日志采集,丢失一些数据是可以接受的,保证速度优先。最少一次—某些业务会自己保证幂等性,但是不允许数据的丢失。如钱包业务。精确一次—通过Kafka保证了幂等性,在业务侧则无需保证幂等性。
个人认为第二种更好点:一般业务都会自己处理幂等性,不会把所有的期望都寄托于Kafka的实现。
- 聊聊Kafka的幂等性和事务
幂等性:
Kafka为了实现幂等性,它在底层设计架构中引入了ProducerID和SequenceNumber。
ProducerID:在每个新的Producer初始化时,会被分配一个唯一的ProducerID,这个ProducerID对客户端使用者是不可见的。
SequenceNumber:对于每个ProducerID,Producer发送数据的每个Topic和Partition都对应一个从0开始单调递增的SequenceNumber值。
》Kafka通过空间换时间的方式,对每个消息都做了标志。如果消息重复发送,Kafka会自动识别并丢弃。
》但是这个幂等性只能作用于单个分区和单次会话,如果Topic分布在多个分区,或者是不同的会话在发布消息Kafka是无法保证幂等性的。
为了解决幂等性的不足,事务型Productor就出现了!那么他又是怎么实现的呢?
事务:开启幂等性和事务,并设置隔离级别为read_committed。
》如MySQL的事务ACID。C是隔离级别,不同的数据库实现对应的隔离级别定义不同,如不可提交读,提交读,可重复读,串行读写。Kafka的事务隔离级别是提交读。
- read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。
- read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
- 现在,请你尝试用 3 个副本来说明一下副本同步全流程,以及分区高水位被更新的过程。
Kafka如何处理请求
一个一个的处理请求,伪代码如:
while (true) { Request request = accept(connection); handle(request); }缺点:吞吐量太低
来一个请求处理一个,完全异步,伪代码如:
while (true) { Request = request = accept(connection); Thread thread = new Thread(() -> { handle(request);}); thread.start(); }缺点:请求量太大可能会压垮服务器。
Reactor
类似epoll的做法。

Kafka请求处理模式: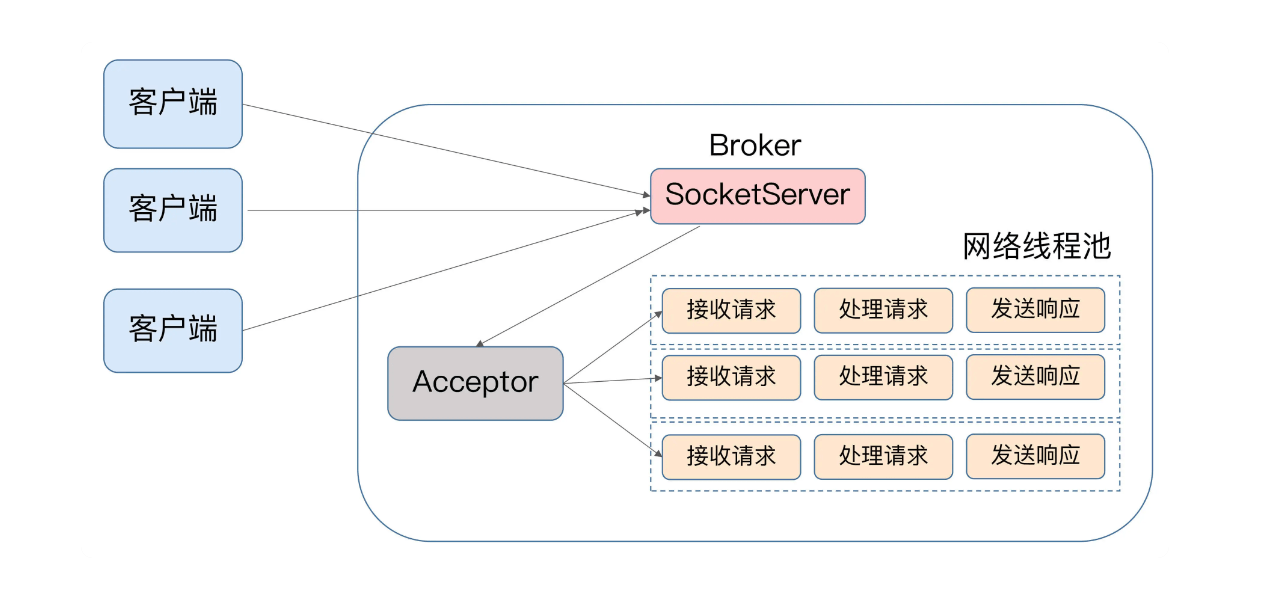
Kafka处理请求的过程:
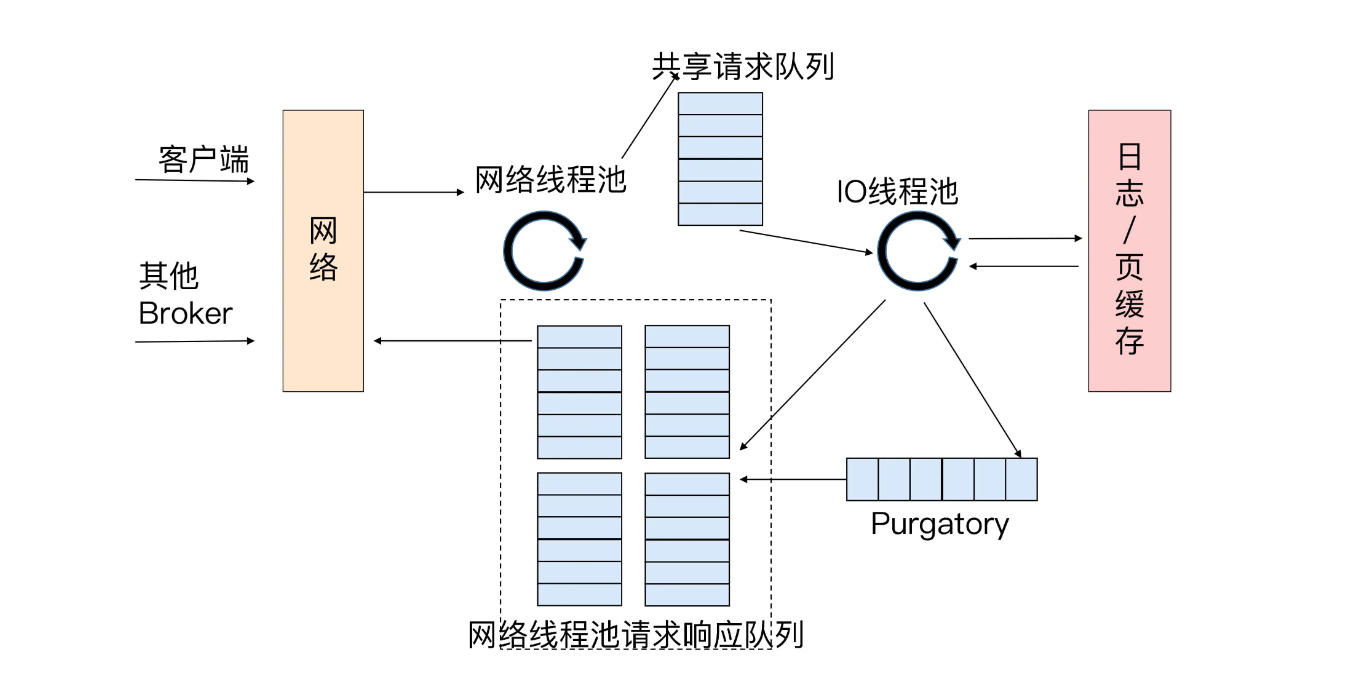
(1)客户端请求,通过网络线程池(就是默认的3个socket)将请求放入共享请求队列。
(2)如果是写请求,做写入日志/缓存
(3)如果是读请求,则通过各socket response。
(4)Purgatory处理无法立即response的请求,如配置了ack=all则必须等待所有副本都同步成功才会respnose。
客户端的请求分为两类:数据类请求和控制类请求
数据类请求:PRODUCE 和 FETCH (写消息/读消息)
控制类请求:如删除副本,变更leader副本等命令消息
Kafka通过两套处理请求的过程,分别处理数据类请求和控制类请求。从而使控制类请求有更高的优先级被执行,减少一些无效操作。






 关于 LearnKu
关于 LearnKu



