
 Elasticsearch中文文档
Elasticsearch中文文档5.1.3. 基数聚合
基数聚合
单指标聚合,可以计算不同值的近似计数,值可以从文档中的特定字段提取,也可以由脚本生成。
假设您正在为商店的销售建立索引,并希望计算与查询匹配的已售产品唯一数量:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}响应:
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}精准控制
该聚合还支持 precision_threshold 选项:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type",
"precision_threshold": 100
}
}
}
}precision_threshold选项允许以内存交换精度,并定义了一个唯一的计数,低于该值时,期望计数将接近于准确。高于该值时,计数可能会变得模糊(误差变大)。最大计数是40000,高于这个阈值跟40000效果一样,默认值是30000。
计数是近似值
计算精确计数需要将值加载到哈希集中并返回其大小。当处理高基数集较大的值时,这不会自动扩容,所以所需的内存使用情况以及在节点之间传递每个分片集的需求会占用过多的群集资源。
cardinality 聚合是基于 HyperLogLog++ 算法,基于具有一些有趣属性的值的哈希进行计数
- 可配置的精度,该精度决定了如何以内存换取精度
- 在低基数集上具有出色的准确性
- 固定的内存使用量:无论是否有成百上千的唯一值,内存使用量仅取决于配置的精度。
对于c的精度阈值,我们正在使用的实现大约需要c * 8个字节。
下表显示了阈值前后误差如何变化:
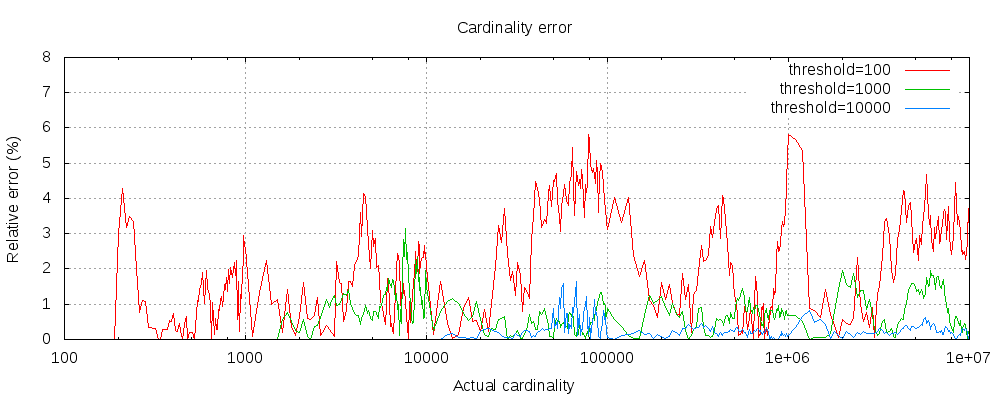
对于所有3个阈值,计数已精确到配置的阈值。虽然不能保证,但很可能是这样。实际的准确性取决于所讨论的数据集。一般来说,大多数数据集都显示出一贯良好的准确性。还要注意,即使阈值低至100,在计算数百万个项目时,错误仍然非常低(如上图所示为1-6%)。
HyperLogLog++算法依赖于散列值的前导零,数据集中散列的精确分布会影响基数的准确性。
请注意,即使阈值低至100,错误仍然很低,即使在计算数百万项时也是如此。
预计算哈希
在具有高基数的字符串字段上,将字段值的哈希存储在索引中然后在此字段上运行基数聚合可能会更快。这可以通过从客户端提供哈希值来完成,也可以让 Elasticsearch 通过使用mapper-murmur3 插件完成。
注意:预计算哈希通常仅在非常大或高基数的字段上有用,因为它可以节省CPU和内存。但是,在数字字段上哈希运算非常快,存储原始值所需的内存与存储哈希值所需的内存相同或更少。对于低基数的字符串字段也是如此,特别是考虑到这些字段已进行了优化,以确保每个段的每个唯一值最多计算一次哈希。
脚本
cardinality 指标支持脚本编写,但是由于需要实时计算哈希值,因此性能受到了明显的影响:
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script": {
"lang": "painless",
"source": "doc['type'].value + ' ' + doc['promoted'].value"
}
}
}
}
}这会将scrpit参数解释为具有painless脚本语言且没有脚本参数的inline脚本。要使用存储的脚本,请使用以下语法:
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script" : {
"id": "my_script",
"params": {
"type_field": "type",
"promoted_field": "promoted"
}
}
}
}
}
}缺失值
missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为有默认值。
POST /sales/_search?size=0
{
"aggs" : {
"tag_cardinality" : {
"cardinality" : {
"field" : "tag",
"missing": "N/A"
}
}
}
}- 标签字段中没有值的文档将与值是 N / A的文档归入同一存储桶
本译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。




 关于 LearnKu
关于 LearnKu



