
 Elasticsearch中文文档
Elasticsearch中文文档5.2.5. 日期直方图聚合
日期直方图聚合
这种多桶聚合类似于普通的 histogram, 但只能与日期值一起使用。由于日期在Elasticsearch中内部以长值表示,因此在日期中使用普通的 histogram 可能并不准确。 两种API的主要区别在于,可以使用日期/时间表达式指定间隔。基于时间的数据需要特殊的支持,因为基于时间的间隔并不总是固定长度。
日历和固定间隔
当我们配置日期直方图聚合时, 可以通过两种方式指定时间间隔: 日历感知时间间隔和固定时间间隔。
日历感知间隔在夏令时会更改特定日期的时间长度,月份具有不同的天数,并且可以将闰秒附加到特定年份。
相比之下,固定间隔始终是SI单位的倍数,并且不会根据日历环境而变化。
注意
组合interval字段已被弃用
在 [7.2] 中interval字段已被弃用
历史上,日历和固定间隔都是在单个interval字段中配置的, 这导致语义混乱。指定1d将假定为日历感知时间,而2d将其解释为固定时间。 为了获得固定时间的“一天” ,用户需要指定下一个较小的单位 (在这种情况下为,24h).
这种组合行为通常对于用户来说是未知的,即使知道该行为,也很难使用和混淆。
不建议使用此行为,而推荐使用两个新的显式字段:calendar_interval和fixed_interval.
通过在日历和时间间隔之间强制进行选择,时间间隔的语义对用户而言立即清晰可见,并且没有歧义。 旧的interval字段将在以后的版本中删除。
日历间隔
日历感知间隔使用 calendar_interval 参数进行配置。 日历间隔只能以“单数”为单位指定 (1d, 1M, 等等)。 不支持倍数,如 2d, 将引发异常。
日历感知间隔可接受的单位为:
- 分 (
m,1m)
所有分钟数从00秒开始。
一分钟是指定时区中第一分钟的00秒与后一分钟的00秒之间的时间间隔,补偿任何中间的闰秒,因此,每小时的分钟数和秒数在开始和结束时相同。
- 小时 (
h,1h)
所有小时都始于00分00秒。
一小时 (1h) 是在指定时区的第一个小时的00:00分钟与第二个小时的下一个小时00:00分钟之间的时间间隔,可补偿任何中间的润秒。因此,每小时的分钟数和秒数在开始和结束时相同。
- 天 (
d,1d)
所有天都是从最早的时间开始,通常是00:00:00 (凌晨).
一天(1d)是指定时区中一天的开始与第二天的开始之间的间隔,补偿任何中间的时间变化。
- 周 (
w,1w)
一周是从指定的时区以一周的同一天为开始到下一周的时间之间的间隔。
- 月 (
M,1M)
一个月是指在指定时区中,月份的开始日期和时间与月份的同一天和时间之间的间隔,月份中日期和时间在开始和结束时相同。
- 季度 (
q,1q)
一个季度 (1q) 是指月份开始日和当天的时间到三个月后同一天相同时间的时间间隔。
- 年 (
y,1y)
一年 (1y) 是指在指定时区中, 从开始月份的日期和时间与下一年同一天和相同时间之间的间隔, 日期和时间在开始和结束时相同。
日历间隔示例
例如, 下面是一个以月为时间间隔的聚合:
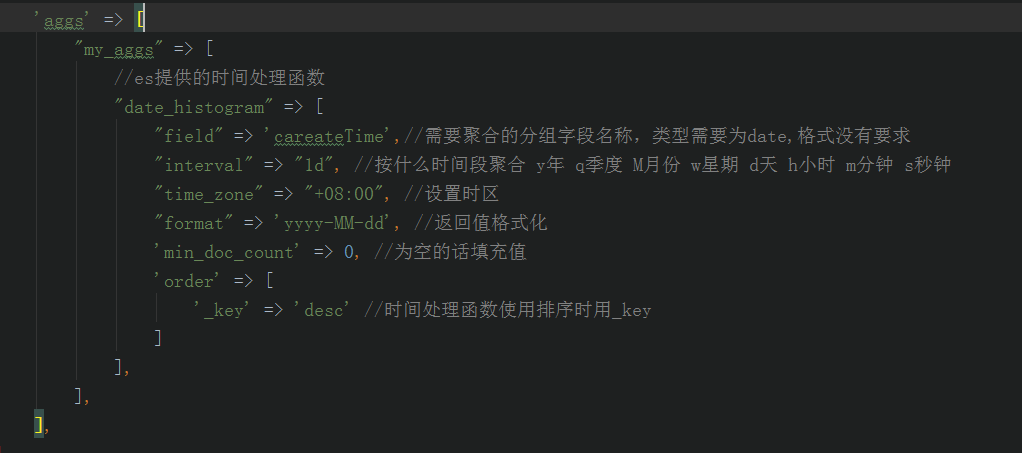
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "month"
}
}
}
}如果尝试使用倍数日历单位,则聚合将失败,因为日历间隔仅支持单个日历单位:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "2d"
}
}
}
}{
"error" : {
"root_cause" : [...],
"type" : "x_content_parse_exception",
"reason" : "[1:82] [date_histogram] failed to parse field [calendar_interval]",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "The supplied interval [2d] could not be parsed as a calendar interval.",
"stack_trace" : "java.lang.IllegalArgumentException: The supplied interval [2d] could not be parsed as a calendar interval."
}
}
}
固定间隔
固定间隔使用 fixed_interval 参数进行配置。
与日历感知间隔相比,固定间隔是固定数量的SI单位,无论它们位于日历上的什么位置,它们都不会偏离。就像一秒始终由1000毫秒组成。这样在任何多个受支持单位上都可以指定固定间隔。
然而,这也意味着固定间隔不能表示像月份这样的单位,因为一个月的时间并不是一个确切的值。尝试指定一个像月份或者季度这样的日历间隔会引发异常。
固定间隔可接受的单位有:
毫秒 (ms)
秒 (s)
- 定义为 1000 毫秒每秒
分钟 (m)
- 每分钟都从 00 秒开始。
定义为 60 秒每分钟 (60,000 毫秒)
- 每分钟都从 00 秒开始。
小时 (h)
- 每小时都从 00 分 00 秒开始。定义为 60 分钟每小时 (3,600,000 毫秒)
天 (d)
- 每天都从最早的 00:00:00 (午夜) 开始。
定义为 24 小时每天 (86,400,000 毫秒)
固定间隔示例
如果我们重新创建之前的 “月份” calendar_interval,我们可以用 30 天估算:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"fixed_interval" : "30d"
}
}
}
}但是如果我们尝试使用一个如星期这样的不支持的日历单位就会引发异常:
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"fixed_interval" : "2w"
}
}
}
}{
"error" : {
"root_cause" : [...],
"type" : "x_content_parse_exception",
"reason" : "[1:82] [date_histogram] failed to parse field [fixed_interval]",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse setting [date_histogram.fixedInterval] with value [2w] as a time value: unit is missing or unrecognized",
"stack_trace" : "java.lang.IllegalArgumentException: failed to parse setting [date_histogram.fixedInterval] with value [2w] as a time value: unit is missing or unrecognized"
}
}
}####
笔记
任何情况下,当指定的结束时间不存在时,实际结束时间是最接近指定结束时间的可用时间。
分布广泛的应用程序还应该考虑多变场景,比如某些国家夏令时间开始/结束于凌晨 12:01 ,因此每年结束都伴随着 59 分钟周六 和 1 分钟周日,再比如一些国家是被国际换日线穿过。上述情况很容易导致不规则时区偏移。
通常,严格的测试能够确保你的时间间隔规范符合你的预期,尤其是关于时间改变事件的测试。
警告:为了避免意外结果,所有建立连接的客户端和服务器,都应该和一个可靠的网络时间服务保持同步。
注意
不支持小数时间,但是你可以通过转换成其它时间单位解决(例如:1.5h可以用90m代替)。
注意
你可以使用 时间单位 支持的缩写来指定时间。
键
在内部,日期被表示为一个从纪元时间(1970.01.01 00:00:00 UTC)开始的64位的毫秒时间戳。时间戳被作为桶的 key 键名返回。 key_as_string 是一个符合 format 参数规范的格式化日期字符串,由同一时间戳转换来。
提示
如果你未指定format,则使用字段映射中指定的第一个日期格式。
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "1M",
"format" : "yyyy-MM-dd"
}
}
}
}1.支持丰富的日期格式
Response:
{
...
"aggregations": {
"sales_over_time": {
"buckets": [
{
"key_as_string": "2015-01-01",
"key": 1420070400000,
"doc_count": 3
},
{
"key_as_string": "2015-02-01",
"key": 1422748800000,
"doc_count": 2
},
{
"key_as_string": "2015-03-01",
"key": 1425168000000,
"doc_count": 2
}
]
}
}
}时区
日期时间在 Elasticsearch 中使用 UTC 存储。默认所有存桶和范围查询也是使用 UTC 完成。如果想要使用 time_zone 参数来区分桶,应该设置一个不同的时区。
你既可以将时区指定为带偏移量的 ISO 8601 UTC(例如 +01:00 或 -08:00),也可以指定为 IANA 时区中的一个时区ID,例如 America/Los_Angeles 。
看一下下面的例子:
PUT my_index/_doc/1?refresh
{
"date": "2015-10-01T00:30:00Z"
}
PUT my_index/_doc/2?refresh
{
"date": "2015-10-01T01:30:00Z"
}
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day"
}
}
}
}如果你未指定时区,则默认使用UTC。
下面命令会将两个文件放到同一天的桶中,这些桶从2015年10月1日午夜开始。
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-10-01T00:00:00.000Z",
"key": 1443657600000,
"doc_count": 2
}
]
}
}
}如果您将 time_zone 指定为 -01:00,则该时区中的午夜比UTC时区的午夜提前 1 小时:
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day",
"time_zone": "-01:00"
}
}
}
}第一个文档存入时间为2015年9月30日的桶,而第二个文档存入时间为2015年10月1日的桶:
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-09-30T00:00:00.000-01:00",
"key": 1443574800000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T00:00:00.000-01:00",
"key": 1443661200000,
"doc_count": 1
}
]
}
}
}key_as_string值表示指定时区中每天午夜时间。
警告
使用会随着 DST (夏令时) 更改的时区时,这些靠近发生变化的时间的桶的存储区大小可能与你使用的时间间隔所期望的略有不同。举例说明,假设一个 DST 在 CET 时区开始:在 2016 年 3 月 27 日凌晨 2 点,时钟被调后 1 小时到当地时间凌晨 3 点。如果你以天为间隔,则当天的桶只有 23 个小时的数据,而不是其它桶存储的 24 个小时的数据。对于较短的时间间隔也是如此,比如 12 小时,在 3 月 27 日凌晨 DST 发生变化时,桶中也只有 11 个小时的数据。
偏移量
offset 参数通过指定正(+)或负(-)偏移持续时间来更改每个桶的起始值,比如 1h 代表 1 小时,1d 代表 1 天,更多可能的持续时间选项,请参见 时间单位。
例如,当使用 天 作为间隔时,每个桶从午夜持续到午夜。将 偏移量 设置为 +6h ,每个桶的运行时间就变为从早上 6 点到第二天 早上 6 点。
PUT my_index/_doc/1?refresh
{
"date": "2015-10-01T05:30:00Z"
}
PUT my_index/_doc/2?refresh
{
"date": "2015-10-01T06:30:00Z"
}
GET my_index/_search?size=0
{
"aggs": {
"by_day": {
"date_histogram": {
"field": "date",
"calendar_interval": "day",
"offset": "+6h"
}
}
}
}上面的请求会将文档分组到开始于上午 6 点的桶,而不是从午夜开始的一个单独的桶。
{
...
"aggregations": {
"by_day": {
"buckets": [
{
"key_as_string": "2015-09-30T06:00:00.000Z",
"key": 1443592800000,
"doc_count": 1
},
{
"key_as_string": "2015-10-01T06:00:00.000Z",
"key": 1443679200000,
"doc_count": 1
}
]
}
}
}注意
每个桶的开始offset是在time_zone调整完之后计算来的。
键响应
将 keyed 设置为 true 会将每个桶和一个唯一的字符串关联起来,并将范围作为散列值而不是数组返回。
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : {
"date_histogram" : {
"field" : "date",
"calendar_interval" : "1M",
"format" : "yyyy-MM-dd",
"keyed": true
}
}
}
}响应结果:
{
...
"aggregations": {
"sales_over_time": {
"buckets": {
"2015-01-01": {
"key_as_string": "2015-01-01",
"key": 1420070400000,
"doc_count": 3
},
"2015-02-01": {
"key_as_string": "2015-02-01",
"key": 1422748800000,
"doc_count": 2
},
"2015-03-01": {
"key_as_string": "2015-03-01",
"key": 1425168000000,
"doc_count": 2
}
}
}
}
}脚本
与正常的 直方图 一样,支持文档级别脚本和值级别脚本。你还可以使用 order 设置来控制返回桶的顺序,并可以通过 min_doc_count 设置对返回的桶进行过滤(默认情况下,与文档匹配的第一个桶和最后一个桶之间的所有桶都会被返回)。该直方图还支持 extended_bounds 设置,这使得直方图的范围扩展到数据本身之外(更多信息,请查看 扩展范围 )。
缺失值
missing 参数对如何处理文档缺失值进行了定义。默认情况下,它们会被忽略,但也可以认为它们有值。
POST /sales/_search?size=0
{
"aggs" : {
"sale_date" : {
"date_histogram" : {
"field" : "date",
"calendar_interval": "year",
"missing": "2000/01/01"
}
}
}- 在
publish_date字段中没有值的文档将与值为2000-01-01的文档落入同一桶中。
排序
默认情况下,返回的桶按照他们的 key 升序排序,但是你可以通过 order 设置控制返回的顺序。该设置支持和 Terms Aggregation 同样的 order 功能。
使用脚本来按照星期几聚合
当你需要按照星期几来聚合时,使用如下脚本来返回结果:
POST /sales/_search?size=0
{
"aggs": {
"dayOfWeek": {
"terms": {
"script": {
"lang": "painless",
"source": "doc['date'].value.dayOfWeekEnum.value"
}
}
}
}
}响应结果:
{
...
"aggregations": {
"dayOfWeek": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "7",
"doc_count": 4
},
{
"key": "4",
"doc_count": 3
}
]
}
}
}响应中包含所有桶,它们使用每星期中的相对日作为键:1 代表星期一,2 代表星期二…… 7 代表星期日。
本译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。
















 关于 LearnKu
关于 LearnKu



