
 Go面试系列
Go面试系列11. 计时器
11.1 Timer 底层数据结构为什么用四叉堆而非二叉堆
相信大家都很熟悉堆排序,是一种利用堆数据结构设计的排序算法。堆是一个近似完全二叉树的结构,并同时满足堆的性质:
每个节点的值都大于或等于其左右孩子结点的值,称为大顶堆; 每个节点的值都小于或等于其左右孩子节点的值,称为小顶堆。
需要注意的是,“堆”结构只规定了父子节点之间的大小关系,对于兄弟节点的大小关系并没有要求。
因为 Timer 都存在一个“到期时间”,为了判断当前时刻有哪些 Timer 到期,Go 语言中采用了“四叉堆”的排序结构。和上面说的普通的堆排序类似,不同点在于: 孩子节点的个数变成了 4 个,树的高度变低了。
例如有这样一个四叉堆,如图所示。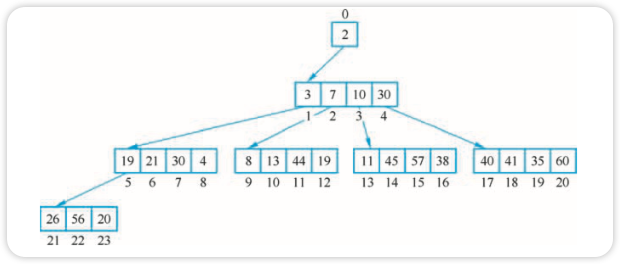
节点的值为定时器到期时间。
为什么要使用堆这种结构?因为 Timer 都存在一个“到期时间”,为了判断当前时刻有哪些 Timer 到期,runtime 中采用了“四叉堆”的排序结构。这里,显然是要采用小顶堆,即堆顶元素最小。如果堆顶元素没到期的话,显然,它的所有子节点都不可能到期。
四叉堆和二叉堆本质上没有区别,它会使得整体上层数更低,且时间复杂度从 O(log2N)降到 O(log4N)。
11.2 Timer 曾做过哪些重大的改进
早在 Go 1.10 以前,所有的 Timer 均在一个全局的四叉小顶堆中进行维护,显然并发性能是不够的,随后到了 Go 1.10 时,将堆的数量扩充到了 64 个,但仍然需要在唤醒 Timer 时,频繁地将 M(指调度器中的工作线程) 和 P(指调度器中的逻辑处理器) 进行解绑(Timerproc 在堆上没有 Timer ready的时候,进行休眠,导致 M 和 P 进行解绑)。当下一个定时事件到来时,又会尝试进行 GPM(G 指调度器中的 goroutine) 绑定,性能依然不够出众。而且 Timerproc 本身就是协程,也需要 runtime 的调度。
到了 Go 1.14 时,取消了 timerproc 协程,把检查到期定时任务的工作交给了 runtime.schedule,不需要额外的调度,在每次的调度循环中,执行 runtime.schedule 以及 findrunable 时直接检查并运行到期的定时任务。Go 运行时中的 Timer 使用 netpoll 进行驱动,每个 Timer 堆均附着在 P 上,形成一个局部的 Timer 堆,消除了唤醒一个 Timer 时进行 M/P 切换的开销,大幅削减了锁的竞争,与 nginx 中 Timer 的实现方式非常相似。
11.3 定时器的使用场景有哪些
一般而言,定时器的触发形式为:
- 经过固定时间间隔后触发;
- 按照固定时间间隔重复触发;
- 在某个具体时刻触发。
一些典型的使用场景:
- 获取某个下游数据,超时时间为 100ms,设置定时器 100ms(固定时间间隔);
- 每天早上 10 点定时统计系统的接口访问量,并群发邮件组(固定时间间隔重复);
- 电商平台“双十一”零点商品下单接口开通访问权限(具体时刻);
- 后台每隔 5s 更新缓存数据(固定时间间隔重复);
- TCP 长连接,客户端需要定时向服务端发送系统请求(固定时间间隔重复);
- TCP 网络协议栈代码需要大量 Timer(固定时间间隔)。
11.4 Timer/Ticker 的及时功能有多准确
对于时间敏感的场景而言,人们自然会问 Timer/Ticker 能够多大程度保证时间的准确性? 为了回答这个问题,必须了解清楚影响时间准确性的多种因素:
- 对系统时间的依赖程度: 对系统时间产生依赖意味着触发时间基于人类社会的公历记法, 即绝对时间,或者说挂钟时间(
wall time)。例如当设定某个任务在GMT+8时区 2020 年 12 月 31 日 23:59:00 触发。这个时间的准确性只能依靠操作系统或者时间提供方(国际标准组织时间服 务器提供的时间)。 - 对运行时的依赖程度: 如果某个任务是基于相对时间触发的,例如某个新设立的、希望在几个小时之后触发一次的任务,是一个相对时间概念,或者说单调时间(
Monotonic clock)。这个时间的准确性则依靠运行时对这个相对时间进行管理的准确性,由于运行时组件的存在,这个时间管理的准确性也将或多或少受到一定程度的影响,例如调度器的调度延迟、垃圾回收器的干扰、操作系统对应用程序进行中断产生的延迟等。
对于这个问题的答案,必须明确任务的具体场景、任务的执行环境状态等。为此,本节通过几个具体的影响因素来举一反三。
1. 获取系统时间的准确性
无论是运行时自身获取挂钟时间、还是用户态代码通过 time.Now 获取时间,最终都会转化为运行时的 runtime 中对 walltime 和 nanotime 的调用:
// src/time/time.go
func Now() Time {
sec, nsec, mono := now()
...
}
func now() (sec int64, nsec int32, mono int64)
// src/runtime/timestub.go
//go:linkname time_now time.now
func time_now() (sec int64, nsec int32, mono int64) {
sec, nsec = walltime()
return sec, nsec, nanotime()
}无论是 walltime 还是 nanotime,都是通过 vdso 来完成的:
// src/runtime/sys_linux_amd64.s
TEXT runtime·walltime(SB),NOSPLIT,$8-12
...
MOVQ runtime·vdsoClockgettimeSym(SB), AX
CMPQ AX, $0
...
MOVL $0, DI // CLOCK_REALTIME
...
TEXT runtime·nanotime1(SB),NOSPLIT,$8-8
...
MOVQ runtime·vdsoClockgettimeSym(SB), AX
CMPQ AX, $0
...
MOVL $1, DI // CLOCK_MONOTONIC
...这个 vdsoClockgettimeSym 的值在运行时启动时向系统内核进行注册 vdsoSymbolKeys 变量:
// src/runtime/vdso_linux_amd64.go
var vdsoSymbolKeys = []vdsoSymbolKey{
{"__vdso_gettimeofday", 0x315ca59, 0xb01bca00, &vdsoGettimeofdaySym},
{"__vdso_clock_gettime", 0xd35ec75, 0x6e43a318, &vdsoClockgettimeSym},
}读者可以根据这个调用关系进行查询: rt0_go->args->sysauxv->vdsoauxv->vdsoParseSymbols。 值得解释的是,这里的 VDSO 指的是虚拟动态共享对象(Virtual Dynamic Shared Object),这个函数符号是一种加速系统调用的机制,对于像获取时间如此频繁的操作,如果将其视为普通系统调用则会出现相当过分的延迟。为此,VDSO 的机制可以理解为直接将系统内核中维护的时间信息从内核空间映射到用户空间,进而加速时间获取的速度。根据注册的符号可知参与的系统调用为 clock_gettime。根据软硬件环境的不同,通常可以认为获取时间的精度在毫秒级。
2. 运行时调度的准确性
前面也提到过,Go 的 Timer 经历了多次优化。但无论是早些时候的 timerproc 实现、还是现在的调度循环及 netpoll 辅助的实现,最终都依赖运行时调度器对该任务的执行。换句话说,无论一个任务唤醒得有多么及时,如果调度器没有及时地去执行该任务,也无济于事。
如果一个超时的 Timer 在调度循环的上下文切换中被发现后,便会在毫秒级内进入执行阶段。这在调度循环的代码中是能够体现的:
// src/runtime/proc.go
func schedule() {
_g_ := getg()
...
pp := _g_.m.p.ptr()
pp.preempt = false
...
checkTimers(pp, 0)
...
}
func checkTimers(pp *p, now int64) (rnow, pollUntil int64, ran bool) {
...
for len(pp.timers) > 0 {
if tw := runtimer(pp, rnow); tw != 0 {
...
}
...
}
...
}
func runtimer(pp *p, now int64) int64 {
for {
t := pp.timers[0]
...
switch s := atomic.Load(&t.status); s {
case timerWaiting:
...
runOneTimer(pp, t, now)
...
}
}
func runOneTimer(pp *p, t *timer, now int64) {
...
f := t.f
arg := t.arg
seq := t.seq
...
unlock(&pp.timersLock)
f(arg, seq)
lock(&pp.timersLock)
...
}可以看到,checkTimers 这个过程其实是在调度循环检查到有需要执行的 timer 时,会立刻去执行触发任务。但是要意识到,这个函数 f 只是 Timer/Ticker 的 channel 通知,任务到何时才能被唤醒,依然是取决于调度器什么时候能够正常调度到该任务。那么这个过程中会发生什么呢? 这个过程有多大程度的延迟呢?
仍然是调度循环的代码,可以看到任务调度的过程其实是优先考虑 GC Worker。在长时间没有检查全局队列时会优先考虑全局队列,大部分情况下,会直接去执行本地队列中的任务:
// src/runtime/proc.go
func schedule() {
...
checkTimers(pp, 0)
var gp *g
...
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
tryWakeP = tryWakeP || gp != nil
}
if gp == nil {
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
gp, inheritTime = findrunnable()
// 阻塞直到任务有效
}
...
execute(gp, inheritTime)
}换句话说,如果运行时“不幸”选中了垃圾回收的 Worker 或者选择了全局队列中的任务,则会出现一定程度上的延迟。除此之外,还应该能够考虑到如果调度器正在执行某个 goroutine 而无法来到 checkTimers,虽然从 Go 1.14 之后,调度器拥有对任务的抢占能力,但抢占的过程不可避免地存在上下文切换的延迟。
总而言之,在对待 Timer/Ticker 的准确性上时,尽管在很大程度上能够相信 Go 的内部运行时实现的高效性,但总是需要保持怀疑的态度,当系统出现可感知的延迟时,可以着重调试运行时本身对延迟的影响,这包括当前调度器调度任务的数量、Timer/Ticker 的密度和垃圾回收器的压力等。
11.5 定时器的视线还有其他哪些方式
定时器可以使用链表、堆、红黑树等数据结构,也可以使用时间轮实现。流行的高效定时器有三种: Go 使用的堆结构、nginx 使用的红黑树、linux kernel 使用的时间轮。
Go 语言内置的 Timer 是采用最小堆来实现的,创建和删除的时间复杂度都为 O(log4N)。Go 在 1.10 前使用的是一个全局的四叉小顶堆结构,当有大量定时器时,会有大量的锁冲突,定时器性能非常差。Go 1.10 引入了 runtime 层的 64 个定时器,也就是 64 个四叉小顶堆定时器,性能提升不少。Go 1.14 则更进一步地为每个 P 分配一个时间堆,每当进入调度循环时,都会对 Timer 进行检查,从而快速的启动那些对时间敏感的 goroutine,这一思路也同样得益于 netpoller,通过系统事件来唤醒那些对时效性极度敏感的任务。
Nginx 使用的红黑树和四叉堆相差不大,唯一的不同是红黑树是二叉树,父节点的孩子节点最多只有 2 个。
而 Linux 内核通过一种被称为时间轮的算法来保证 add_timer()、del_timer() 以及 expire 操作的时间复杂度都为O(1)。时间轮一般有简单时间轮和层级时间轮两种实现方式。
时间轮的实现如图所示。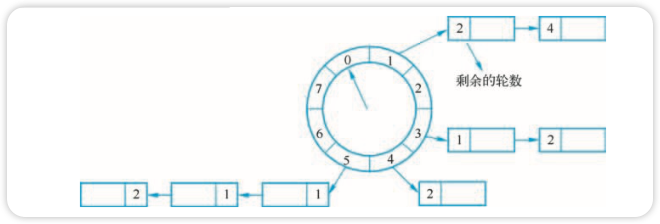
假设每个刻度是 1s,则整个时间轮能表示的时间段为 8s,如果当前指针指向 0,此时需要调度一个 3s 后执行的任务,需要放到第 3 个格子(0+3)中,指针再转 3 次就可以执行了。然而,格子的数量有限,所能代表的时间有限,如果要存放一个 10s 后到期的任务就引起时间轮的溢出。
解决办法是把轮次信息也保存到时间格链表的任务上。检查过期任务时应当只执行 round 为 0 的任务,链表中其他任务的 round 执行减 1 操作。
带轮次的单层时间轮存在的问题是: 如果任务的时间跨度很大、数量很大,单层时间轮会造成任务的 round 很大,单个格子的链表很长,每次检查的量很大,会做很多无效的检查。
解决办法就是使用多层时间轮,实现如图所示。
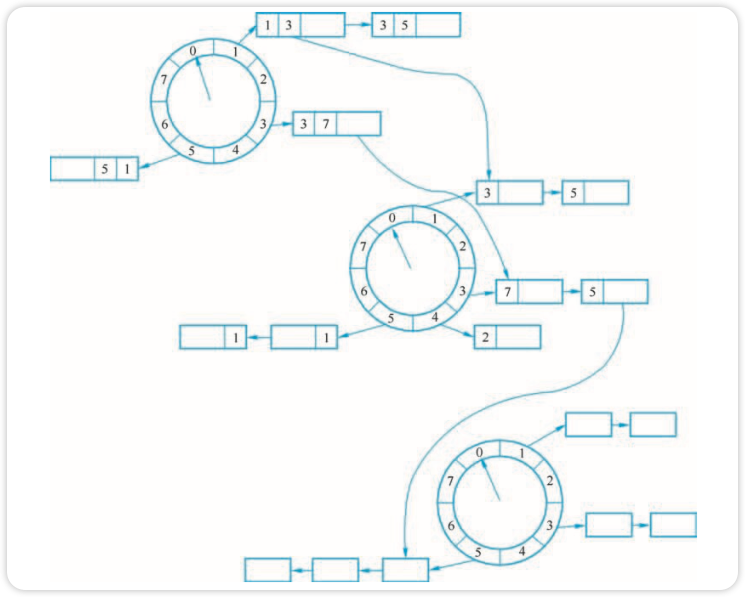
过期任务一定是在底层轮中被执行,其他时间轮中的任务在接近过期时会不断地降级进入低一层的时间轮中。分层时间轮中每个轮都有自己的格数和间隔设置,当最底层的时间轮转一圈时,高一层的时间轮就转一个格子。分层时间轮大大增加了可表示的时间范围,同时减少了空间占用。
例如我们可以构建一个能够精确到秒,最长定时时间为一天的三层时间轮,三层分别为:时、 分、秒,如图所示。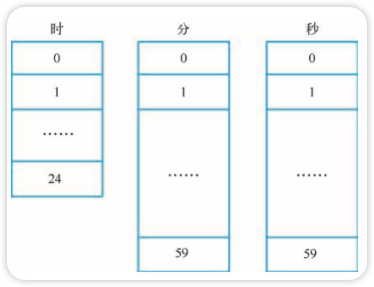
具体实现上可以使用三个循环数组。假设当前时间为 11 时 20 分 32 秒,即时、分、秒三层的 指针分别指向 11、20、32,现在创建一个 2 小时 45 分 36 秒的定时任务,计算出到期时间为 14 时 6 分 8 秒,如图所示。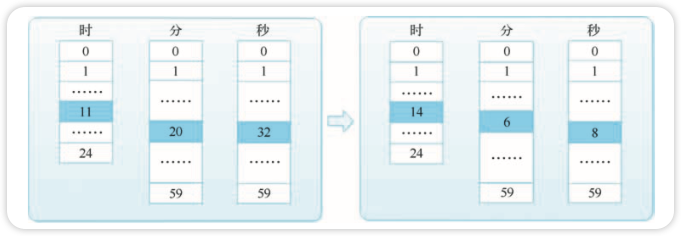
我们实际上模拟了时钟的运行规律,首先把定时任务“挂”到 14 时上; 当时钟转到 14 时, 将任务降一级到 6 分上; 当分钟转到 6 时,将任务降一级到 8 秒上;等最后秒钟转到 8 时,任务到期,如图所示。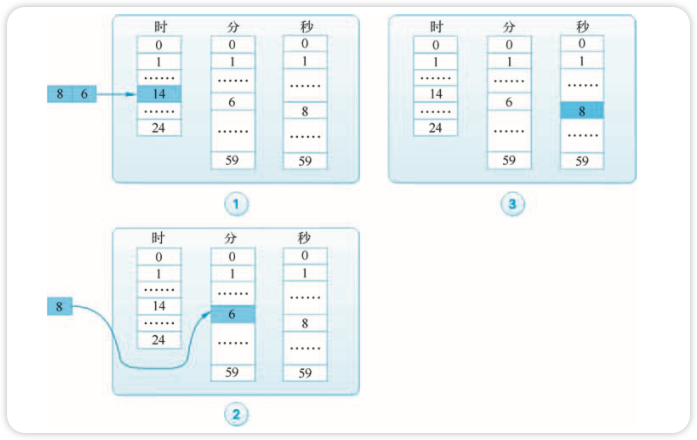
分层的意义在于提高精度和多任务负载均衡。当时间跨度很大时,提升单层时间轮的 tickDuration 可以减少空转次数,但会导致时间精度变低; 多层时间轮既可以避免精度降低,又避免了指针空转的次数。如果有长时间跨度的定时任务,则可以交给多层时间轮去调度。






 关于 LearnKu
关于 LearnKu



