
 Go面试系列
Go面试系列8. 调度器
8.1 goroutine 和线程的区别
谈到 goroutine,绕不开的一个话题是:它和 thread 有什么区别?
参考资料How Goroutines Work告诉我们可以从三个角度区别:内存消耗、创建与销毀、切换。
- 内存占用
创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。
对于一个用 Go 构建的 HTTP Server 而言,对到来的每个请求,创建一个 goroutine 用来处理是非常轻松的一件事。而如果用一个使用线程作为并发原语的语言构建的服务,例如 Java 来说,每个请求对应一个线程则太浪费资源了,很快就会出 OOM 错误(OutOfMemoryError)。
- 创建和销毀
Thread 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池。而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。
- 切换
当 threads 切换时,需要保存各种寄存器,以便将来恢复:
16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc.
而 goroutines 切换只需保存三个寄存器:Program Counter, Stack Pointer and BP。
一般而言,线程切换会消耗 1000-1500 纳秒,一个纳秒平均可以执行 12-18 条指令。所以由于线程切换,执行指令的条数会减少 12000-18000。
Goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。
因此,goroutines 切换成本比 threads 要小得多。
8.2 什么是 scheduler
什么是 scheduler
Go 程序的执行由两层组成:Go Program,Runtime,即用户程序和运行时。它们之间通过函数调用来实现内存管理、channel 通信、goroutines 创建等功能。用户程序进行的系统调用都会被 Runtime 拦截,以此来帮助它进行调度以及垃圾回收相关的工作。
一个展现了全景式的关系如下图:
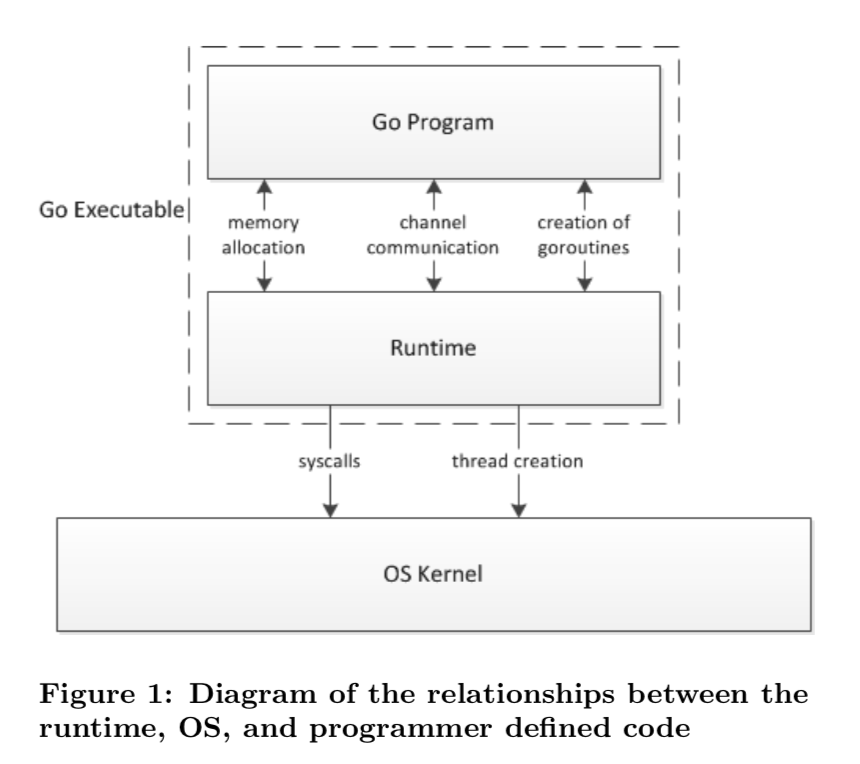
为什么要 scheduler
Go scheduler 可以说是 Go 运行时的一个最重要的部分了。Runtime 维护所有的 goroutines,并通过 scheduler 来进行调度。Goroutines 和 threads 是独立的,但是 goroutines 要依赖 threads 才能执行。
Go 程序执行的高效和 scheduler 的调度是分不开的。
scheduler 底层原理
实际上在操作系统看来,所有的程序都是在执行多线程。将 goroutines 调度到线程上执行,仅仅是 runtime 层面的一个概念,在操作系统之上的层面。
有三个基础的结构体来实现 goroutines 的调度。g,m,p。
g 代表一个 goroutine,它包含:表示 goroutine 栈的一些字段,指示当前 goroutine 的状态,指示当前运行到的指令地址,也就是 PC 值。
m 表示内核线程,包含正在运行的 goroutine 等字段。
p 代表一个虚拟的 Processor,它维护一个处于 Runnable 状态的 g 队列,m 需要获得 p 才能运行 g。
当然还有一个核心的结构体:sched,它总览全局。
Runtime 起始时会启动一些 G:垃圾回收的 G,执行调度的 G,运行用户代码的 G;并且会创建一个 M 用来开始 G 的运行。随着时间的推移,更多的 G 会被创建出来,更多的 M 也会被创建出来。
当然,在 Go 的早期版本,并没有 p 这个结构体,m 必须从一个全局的队列里获取要运行的 g,因此需要获取一个全局的锁,当并发量大的时候,锁就成了瓶颈。后来在大神 Dmitry Vyokov 的实现里,加上了 p 结构体。每个 p 自己维护一个处于 Runnable 状态的 g 的队列,解决了原来的全局锁问题。
Go scheduler 的目标:
For scheduling goroutines onto kernel threads.

Go scheduler 的核心思想是:
- reuse threads;
- 限制同时运行(不包含阻塞)的线程数为
N,N等于CPU的核心数目; - 线程私有的
runqueues,并且可以从其他线程stealing goroutine来运行,线程阻塞后,可以将runqueues传递给其他线程。
为什么需要 P 这个组件,直接把 runqueues 放到 M 不行吗?
You might wonder now, why have contexts at all? Can’t we just put the runqueues on the threads and get rid of contexts? Not really. The reason we have contexts is so that we can hand them off to other threads if the running thread needs to block for some reason.
An example of when we need to block, is when we call into a syscall. Since a thread cannot both be executing code and be blocked on a syscall, we need to hand off the context so it can keep scheduling.
翻译一下,当一个线程阻塞的时候,将和它绑定的 P 上的 goroutines 转移到其他线程。
Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 global runqueues。这是一个全局的 runqueue,优先级比较低,以示惩罚。

总览
通常讲到 Go scheduler都会提到 GPM 模型,我们来一个个地看。
下图是我使用的 mac 的硬件信息,只有 2 个核。
但是配上 CPU 的超线程,1 个核可以变成 2 个,所以当我在 mac 上运行下面的程序时,会打印出 4。
func main() {
// NumCPU 返回当前进程可以用到的逻辑核心数
fmt.Println(runtime.NumCPU())
}因为 NumCPU 返回的是逻辑核心数,而非物理核心数,所以最终结果是 4。
Go 程序启动后,会给每个逻辑核心分配一个 P(Logical Processor);同时,会给每个 P 分配一个 M(Machine,表示内核线程),这些内核线程仍然由 OS scheduler 来调度。
总结一下,当我在本地启动一个 Go 程序时,会得到 4 个系统线程去执行任务,每个线程会搭配一个 P。
在初始化时,Go 程序会有一个 G(initial Goroutine),执行指令的单位。G 会在 M 上得到执行,内核线程是在 CPU 核心上调度,而 G 则是在 M 上进行调度。
G、P、M 都说完了,还有两个比较重要的组件没有提到: 全局可运行队列(GRQ)和本地可运行队列(LRQ)。 LRQ 存储本地(也就是具体的 P)的可运行 goroutine,GRQ 存储全局的可运行 goroutine,这些 goroutine 还没有分配到具体的 P。
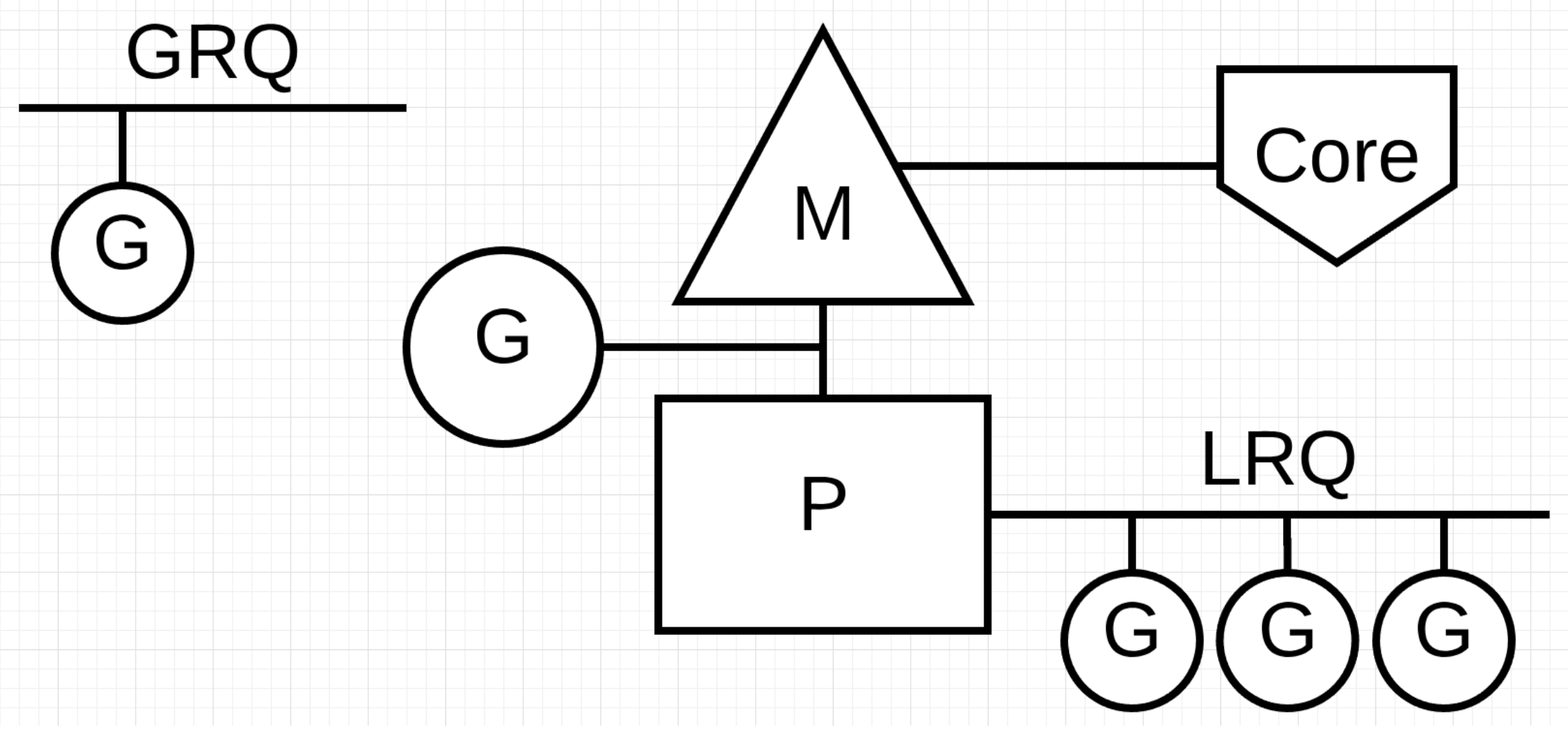
Go scheduler 是 Go runtime 的一部分,它内嵌在 Go 程序里,和 Go 程序一起运行。因此它运行在用户空间,在 kernel 的上一层。和 Os scheduler 抢占式调度(preemptive)不一样,Go scheduler 采用协作式调度(cooperating)。
Being a cooperating scheduler means the scheduler needs well-defined user space events that happen at safe points in the code to make scheduling decisions.
协作式调度一般会由用户设置调度点,例如 python 中的 yield 会告诉 Os scheduler 可以将我调度出去了。
但是由于在 Go 语言里,goroutine 调度的事情是由 Go runtime 来做,并非由用户控制,所以我们依然可以将 Go scheduler 看成是抢占式调度,因为用户无法预测调度器下一步的动作是什么。
和线程类似,goroutine 的状态也是三种(简化版的):
| 状态 | 解释 |
|---|---|
| Waiting | 等待状态,goroutine 在等待某件事的发生。例如等待网络数据、硬盘;调用操作系统 API;等待内存同步访问条件 ready,如 atomic, mutexes |
| Runnable | 就绪状态,只要给 M 我就可以运行 |
| Executing | 运行状态。goroutine 在 M 上执行指令,这是我们想要的 |
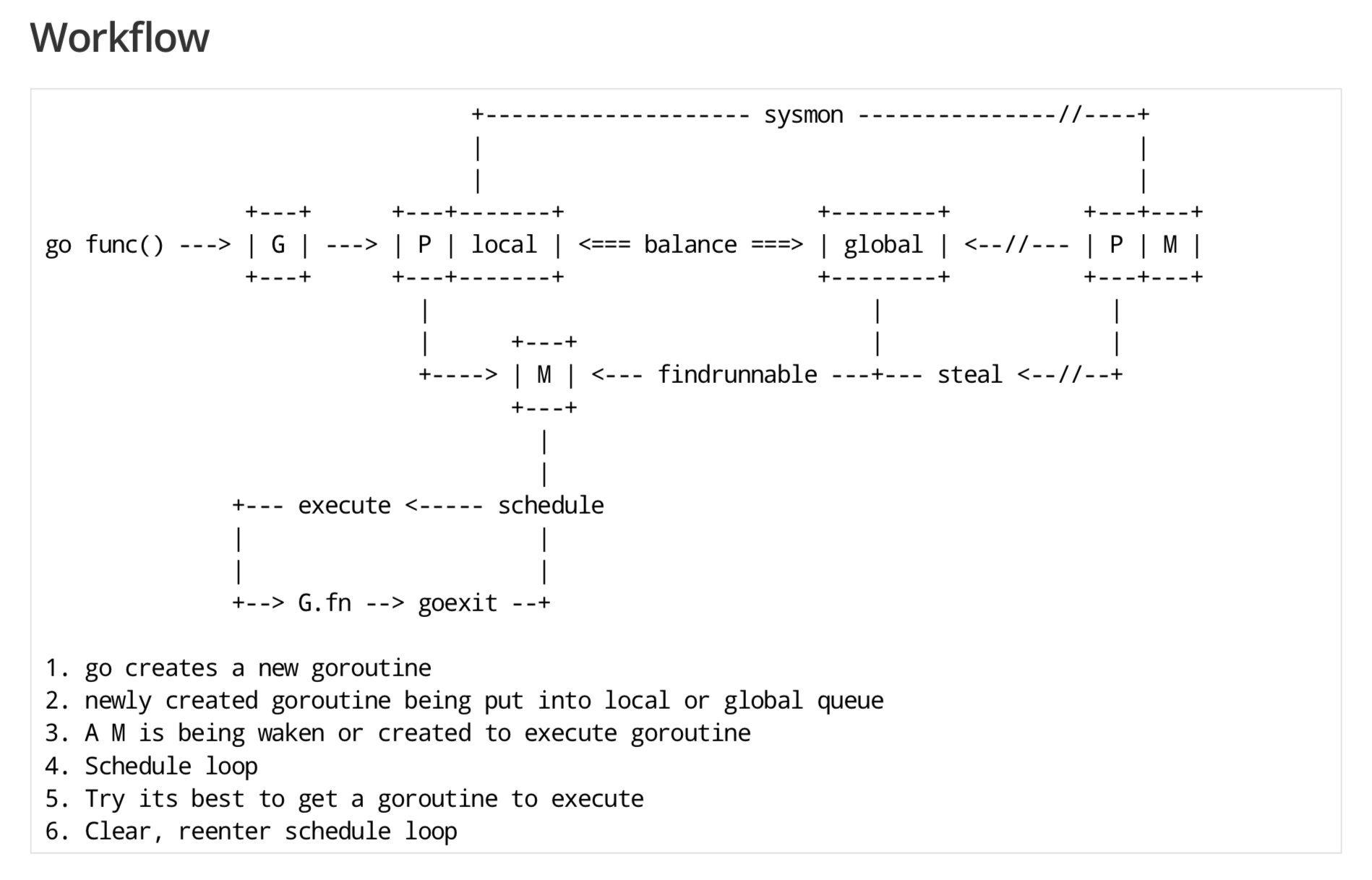
下面这张 GPM 全局的运行示意图见得比较多,可以留着,看完后面的系列文章之后再回头来看,还是很有感触的:
8.3 goroutine 调度时机有哪些
在四种情形下,goroutine 可能会发生调度,但也并不一定会发生,只是说 Go scheduler 有机会进行调度。
| 情形 | 说明 |
|---|---|
使用关键字 go |
go 创建一个新的 goroutine,Go scheduler 会考虑调度 |
| GC | 由于进行 GC 的 goroutine 也需要在 M 上运行,因此肯定会发生调度。当然,Go scheduler 还会做很多其他的调度,例如调度不涉及堆访问的 goroutine 来运行。GC 不管栈上的内存,只会回收堆上的内存 |
| 系统调用 | 当 goroutine 进行系统调用时,会阻塞 M,所以它会被调度走,同时一个新的 goroutine 会被调度上来 |
| 内存同步访问 | atomic,mutex,channel 操作等会使 goroutine 阻塞,因此会被调度走。等条件满足后(例如其他 goroutine 解锁了)还会被调度上来继续运行 |
8.4 什么是 M:N 模型
我们都知道,Go runtime 会负责 goroutine 的生老病死,从创建到销毁,都一手包办。Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。这就是 M:N 模型:
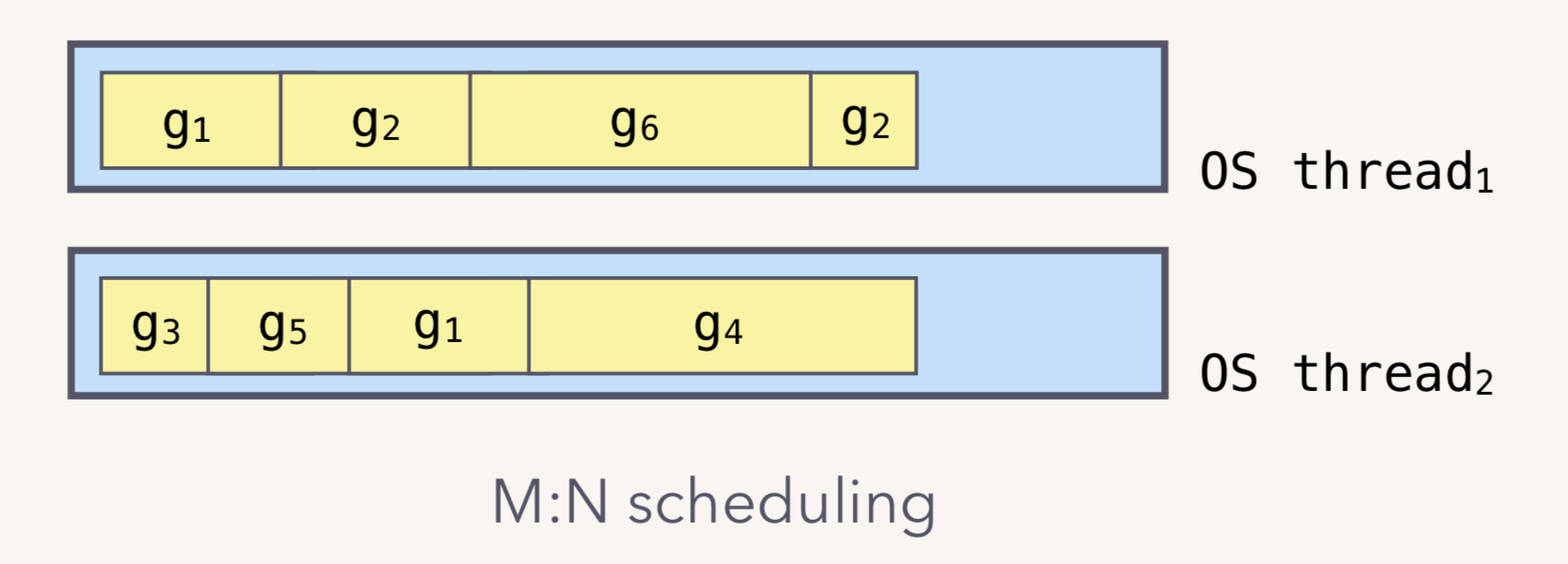
在同一时刻,一个线程上只能跑一个 goroutine。当 goroutine 发生阻塞(例如上篇文章提到的向一个 channel 发送数据,被阻塞)时,runtime 会把当前 goroutine 调度走,让其他 goroutine 来执行。目的就是不让一个线程闲着,榨干 CPU 的每一滴油水。
8.5 什么是 workstealing
Go scheduler 的职责就是将所有处于 runnable 的 goroutines 均匀分布到在 P 上运行的 M。
当一个 P 发现自己的 LRQ 已经没有 G 时,会从其他 P “偷” 一些 G 来运行。看看这是什么精神!自己的工作做完了,为了全局的利益,主动为别人分担。这被称为 Work-stealing,Go 从 1.1 开始实现。
Go scheduler 使用 M:N 模型,在任一时刻,M 个 goroutines(G) 要分配到 N 个内核线程(M),这些 M 跑在个数最多为 GOMAXPROCS 的逻辑处理器(P)上。每个 M 必须依附于一个 P,每个 P 在同一时刻只能运行一个 M。如果 P 上的 M 阻塞了,那它就需要其他的 M 来运行 P 的 LRQ 里的 goroutines。
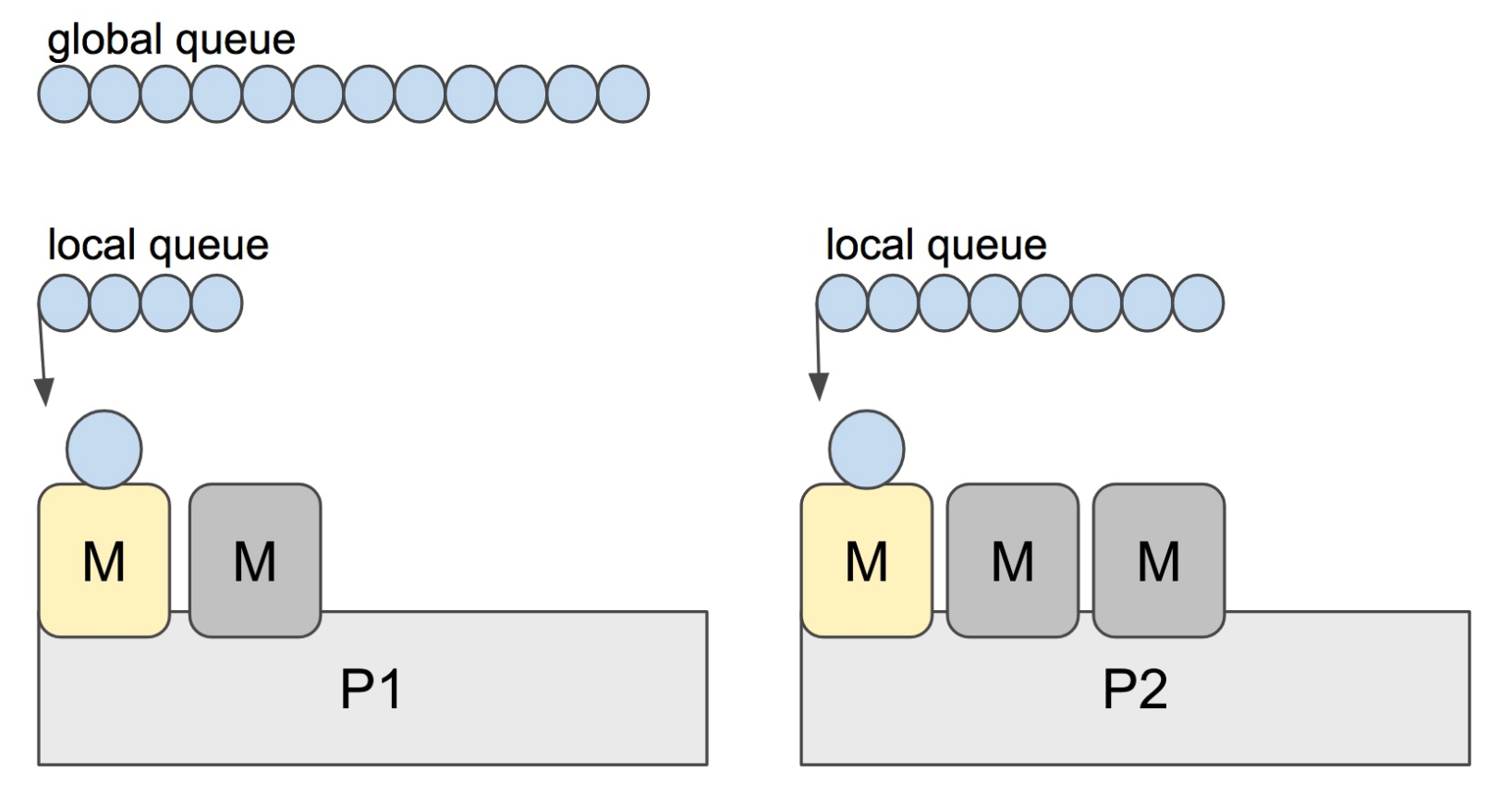
个人感觉,上面这张图比常见的那些用三角形表示 M,圆形表示 G,矩形表示 P 的那些图更生动形象。
实际上,Go scheduler 每一轮调度要做的工作就是找到处于 runnable 的 goroutines,并执行它。找的顺序如下:
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}找到一个可执行的 goroutine 后,就会一直执行下去,直到被阻塞。
当 P2 上的一个 G 执行结束,它就会去 LRQ 获取下一个 G 来执行。如果 LRQ 已经空了,就是说本地可运行队列已经没有 G 需要执行,并且这时 GRQ 也没有 G 了。这时,P2 会随机选择一个 P(称为 P1),P2 会从 P1 的 LRQ “偷”过来一半的 G。
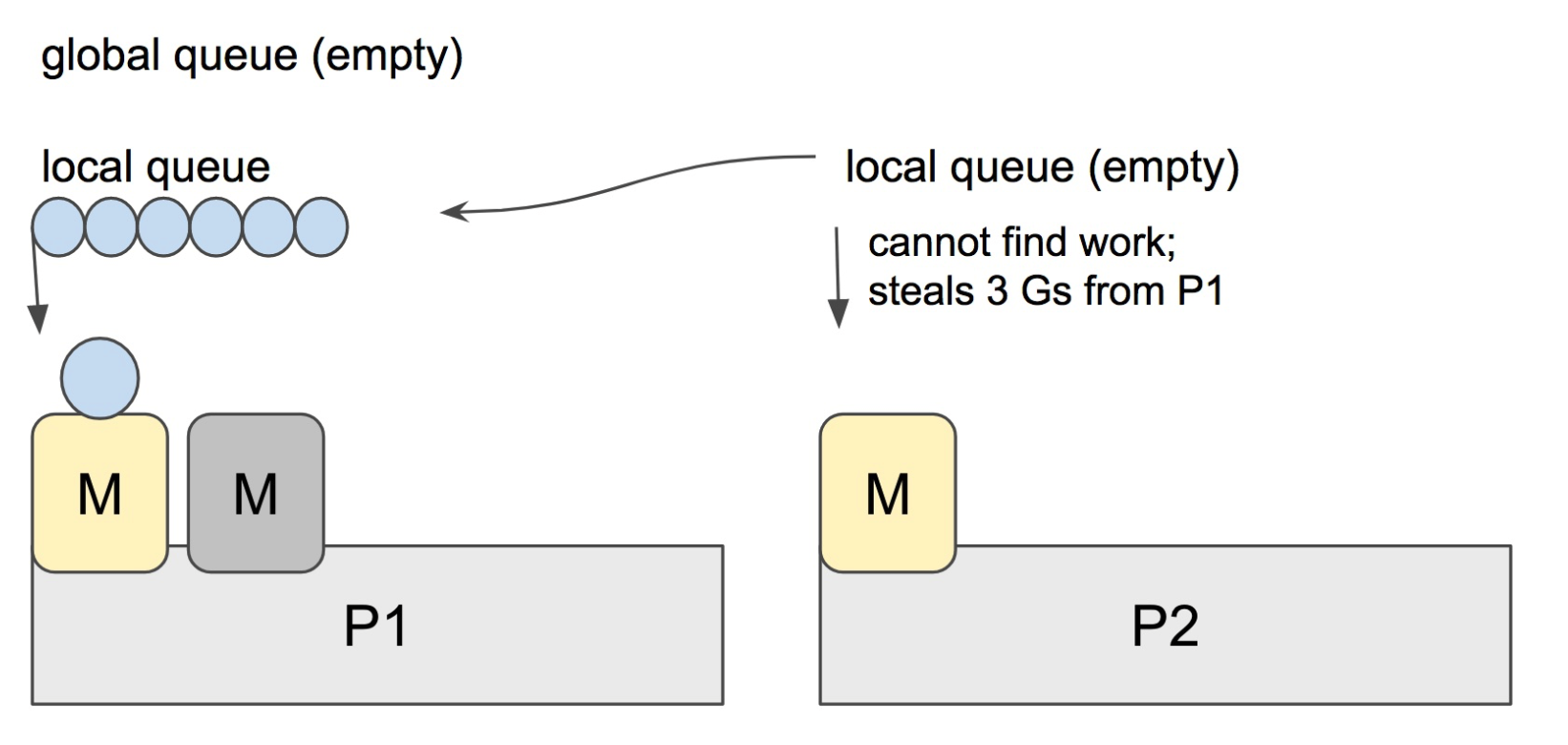
这样做的好处是,有更多的 P 可以一起工作,加速执行完所有的 G。
8.6 GPM 是什么
G、P、M 是 Go 调度器的三个核心组件,各司其职。在它们精密地配合下,Go 调度器得以高效运转,这也是 Go 天然支持高并发的内在动力。今天这篇文章我们来深入理解 GPM 模型。
先看 G,取 goroutine 的首字母,主要保存 goroutine 的一些状态信息以及 CPU 的一些寄存器的值,例如 IP 寄存器,以便在轮到本 goroutine 执行时,CPU 知道要从哪一条指令处开始执行。
当 goroutine 被调离 CPU 时,调度器负责把 CPU 寄存器的值保存在 g 对象的成员变量之中。
当 goroutine 被调度起来运行时,调度器又负责把 g 对象的成员变量所保存的寄存器值恢复到 CPU 的寄存器。
本系列使用的代码版本是 1.9.2,来看一下 g 的源码:
type g struct {
// goroutine 使用的栈
stack stack // offset known to runtime/cgo
// 用于栈的扩张和收缩检查,抢占标志
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
// 当前与 g 绑定的 m
m *m // current m; offset known to arm liblink
// goroutine 的运行现场
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
// wakeup 时传入的参数
param unsafe.Pointer // passed parameter on wakeup
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
// g 被阻塞之后的近似时间
waitsince int64 // approx time when the g become blocked
// g 被阻塞的原因
waitreason string // if status==Gwaiting
// 指向全局队列里下一个 g
schedlink guintptr
// 抢占调度标志。这个为 true 时,stackguard0 等于 stackpreempt
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
paniconfault bool // panic (instead of crash) on unexpected fault address
preemptscan bool // preempted g does scan for gc
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
gcscanvalid bool // false at start of gc cycle, true if G has not run since last scan; TODO: remove?
throwsplit bool // must not split stack
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
// syscall 返回之后的 cputicks,用来做 tracing
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
// 如果调用了 LockOsThread,那么这个 g 会绑定到某个 m 上
lockedm *m
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
// 创建该 goroutine 的语句的指令地址
gopc uintptr // pc of go statement that created this goroutine
// goroutine 函数的指令地址
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
// time.Sleep 缓存的定时器
timer *timer // cached timer for time.Sleep
gcAssistBytes int64
}源码中,比较重要的字段我已经作了注释,其他未作注释的与调度关系不大或者我暂时也没有理解的。
g 结构体关联了两个比较简单的结构体,stack 表示 goroutine 运行时的栈:
// 描述栈的数据结构,栈的范围:[lo, hi)
type stack struct {
// 栈顶,低地址
lo uintptr
// 栈低,高地址
hi uintptr
}Goroutine 运行时,光有栈还不行,至少还得包括 PC,SP 等寄存器,gobuf 就保存了这些值:
type gobuf struct {
// 存储 rsp 寄存器的值
sp uintptr
// 存储 rip 寄存器的值
pc uintptr
// 指向 goroutine
g guintptr
ctxt unsafe.Pointer // this has to be a pointer so that gc scans it
// 保存系统调用的返回值
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}再来看 M,取 machine 的首字母,它代表一个工作线程,或者说系统线程。G 需要调度到 M 上才能运行,M 是真正工作的人。结构体 m 就是我们常说的 M,它保存了 M 自身使用的栈信息、当前正在 M 上执行的 G 信息、与之绑定的 P 信息……
当 M 没有工作可做的时候,在它休眠前,会“自旋”地来找工作:检查全局队列,查看 network poller,试图执行 gc 任务,或者“偷”工作。
结构体 m 的源码如下:
// m 代表工作线程,保存了自身使用的栈信息
type m struct {
// 记录工作线程(也就是内核线程)使用的栈信息。在执行调度代码时需要使用
// 执行用户 goroutine 代码时,使用用户 goroutine 自己的栈,因此调度时会发生栈的切换
g0 *g // goroutine with scheduling stack/
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
sigmask sigset // storage for saved signal mask
// 通过 tls 结构体实现 m 与工作线程的绑定
// 这里是线程本地存储
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
// 指向正在运行的 goroutine 对象
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
// 当前工作线程绑定的 p
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
id int32
mallocing int32
throwing int32
// 该字段不等于空字符串的话,要保持 curg 始终在这个 m 上运行
preemptoff string // if != "", keep curg running on this m
locks int32
softfloat int32
dying int32
profilehz int32
helpgc int32
// 为 true 时表示当前 m 处于自旋状态,正在从其他线程偷工作
spinning bool // m is out of work and is actively looking for work
// m 正阻塞在 note 上
blocked bool // m is blocked on a note
// m 正在执行 write barrier
inwb bool // m is executing a write barrier
newSigstack bool // minit on C thread called sigaltstack
printlock int8
// 正在执行 cgo 调用
incgo bool // m is executing a cgo call
fastrand uint32
// cgo 调用总计数
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 成员上,
// 其它线程通过这个 park 唤醒该工作线程
park note
// 记录所有工作线程的链表
alllink *m // on allm
schedlink muintptr
mcache *mcache
lockedg *g
createstack [32]uintptr // stack that created this thread.
freglo [16]uint32 // d[i] lsb and f[i]
freghi [16]uint32 // d[i] msb and f[i+16]
fflag uint32 // floating point compare flags
locked uint32 // tracking for lockosthread
// 正在等待锁的下一个 m
nextwaitm uintptr // next m waiting for lock
needextram bool
traceback uint8
waitunlockf unsafe.Pointer // todo go func(*g, unsafe.pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
// 工作线程 id
thread uintptr // thread handle
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
mOS
}再来看 P,取 processor 的首字母,为 M 的执行提供“上下文”,保存 M 执行 G 时的一些资源,例如本地可运行 G 队列,memeory cache 等。
一个 M 只有绑定 P 才能执行 goroutine,当 M 被阻塞时,整个 P 会被传递给其他 M ,或者说整个 P 被接管。
// p 保存 go 运行时所必须的资源
type p struct {
lock mutex
// 在 allp 中的索引
id int32
status uint32 // one of pidle/prunning/...
link puintptr
// 每次调用 schedule 时会加一
schedtick uint32
// 每次系统调用时加一
syscalltick uint32
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
sysmontick sysmontick // last tick observed by sysmon
// 指向绑定的 m,如果 p 是 idle 的话,那这个指针是 nil
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
racectx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
// 本地可运行的队列,不用通过锁即可访问
runqhead uint32 // 队列头
runqtail uint32 // 队列尾
// 使用数组实现的循环队列
runq [256]guintptr
// runnext 非空时,代表的是一个 runnable 状态的 G,
// 这个 G 被 当前 G 修改为 ready 状态,相比 runq 中的 G 有更高的优先级。
// 如果当前 G 还有剩余的可用时间,那么就应该运行这个 G
// 运行之后,该 G 会继承当前 G 的剩余时间
runnext guintptr
// Available G's (status == Gdead)
// 空闲的 g
gfree *g
gfreecnt int32
sudogcache []*sudog
sudogbuf [128]*sudog
tracebuf traceBufPtr
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcBgMarkWorker guintptr
gcMarkWorkerMode gcMarkWorkerMode
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad [sys.CacheLineSize]byte
}GPM 三足鼎力,共同成就 Go scheduler。G 需要在 M 上才能运行,M 依赖 P 提供的资源,P 则持有待运行的 G。你中有我,我中有你。
描述三者的关系:
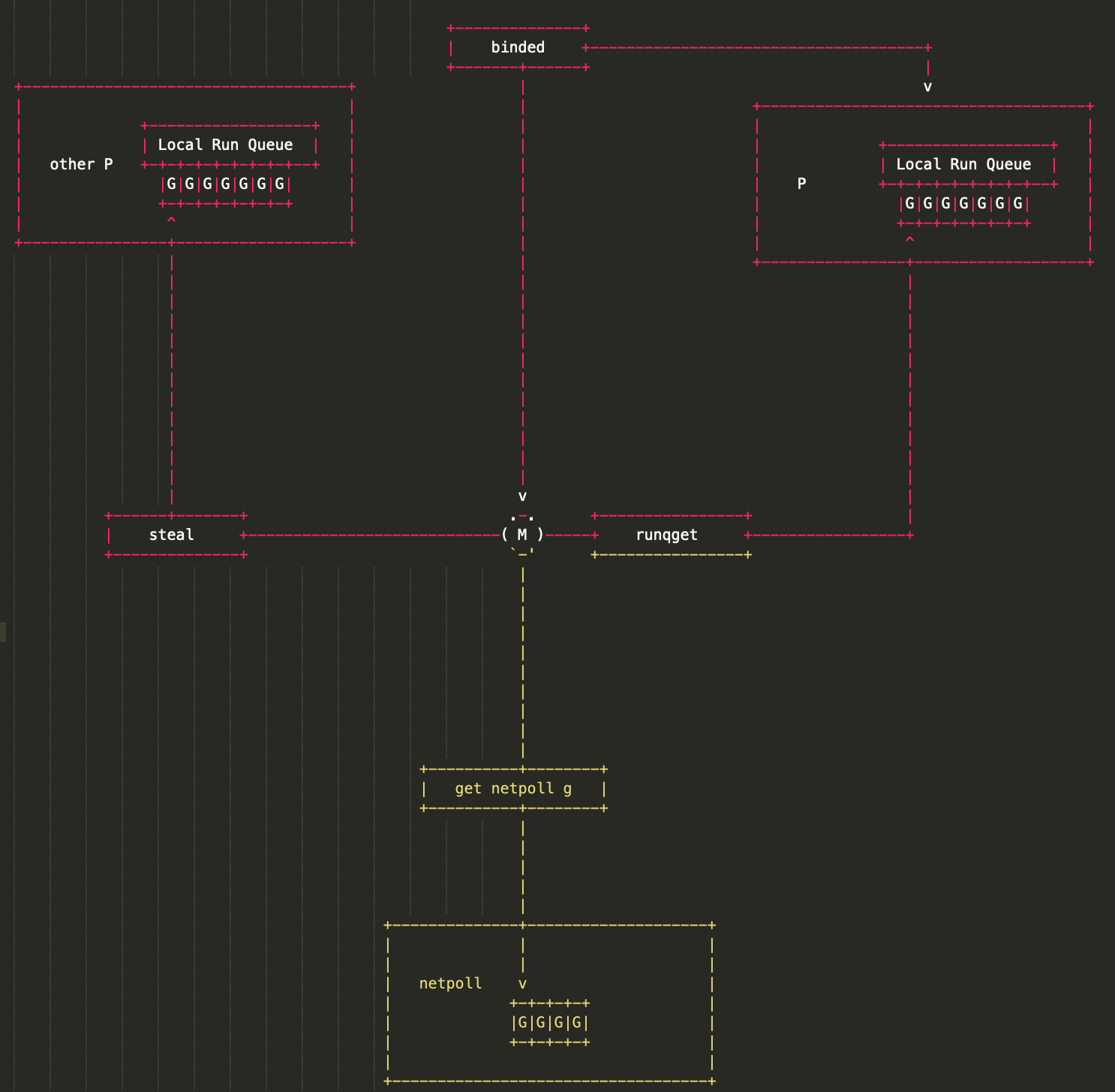
M 会从与它绑定的 P 的本地队列获取可运行的 G,也会从 network poller 里获取可运行的 G,还会从其他 P 偷 G。
最后我们从宏观上总结一下 GPM,这篇文章尝试从它们的状态流转角度总结。
首先是 G 的状态流转:
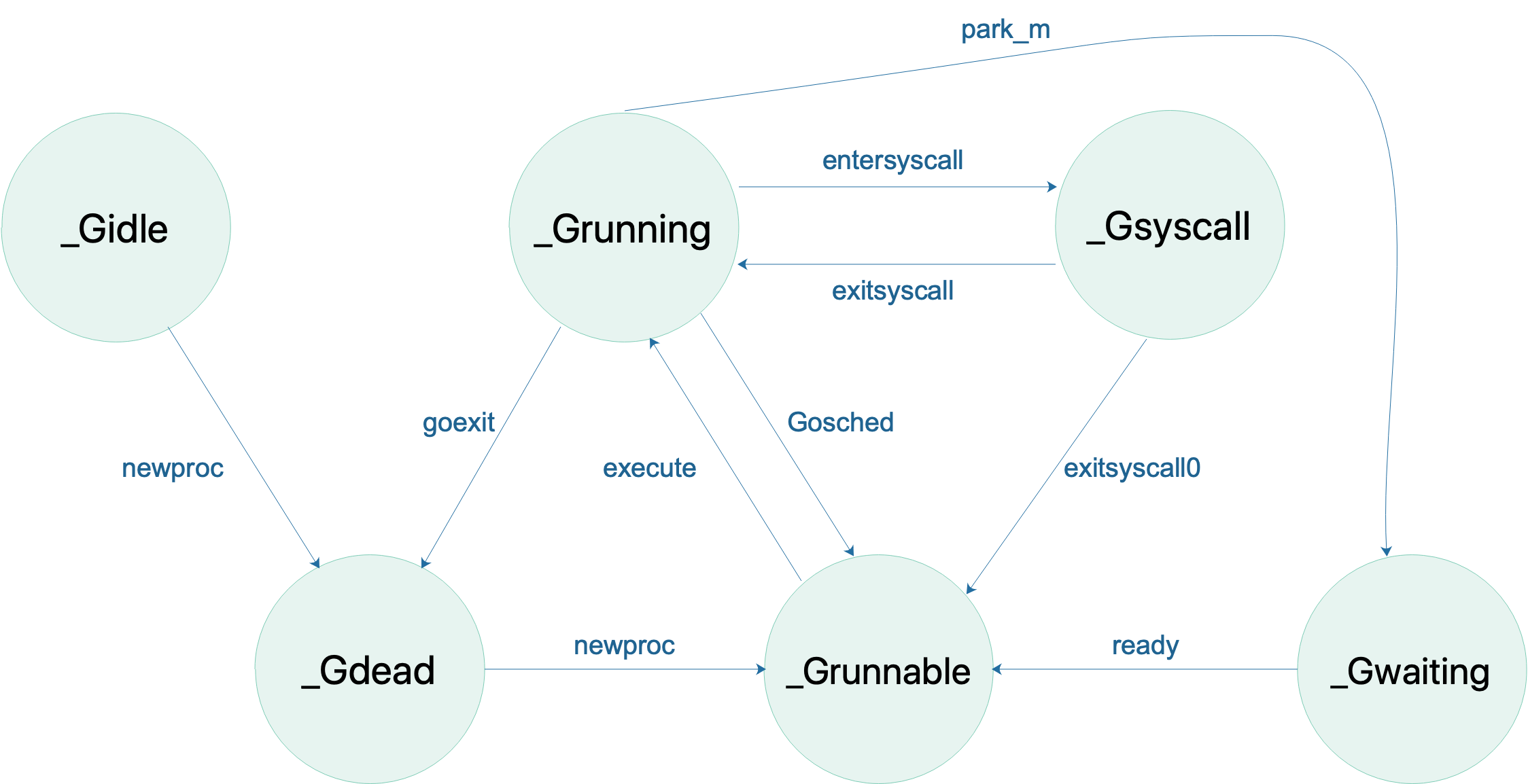
说明一下,上图省略了一些垃圾回收的状态。
接着是 P 的状态流转:
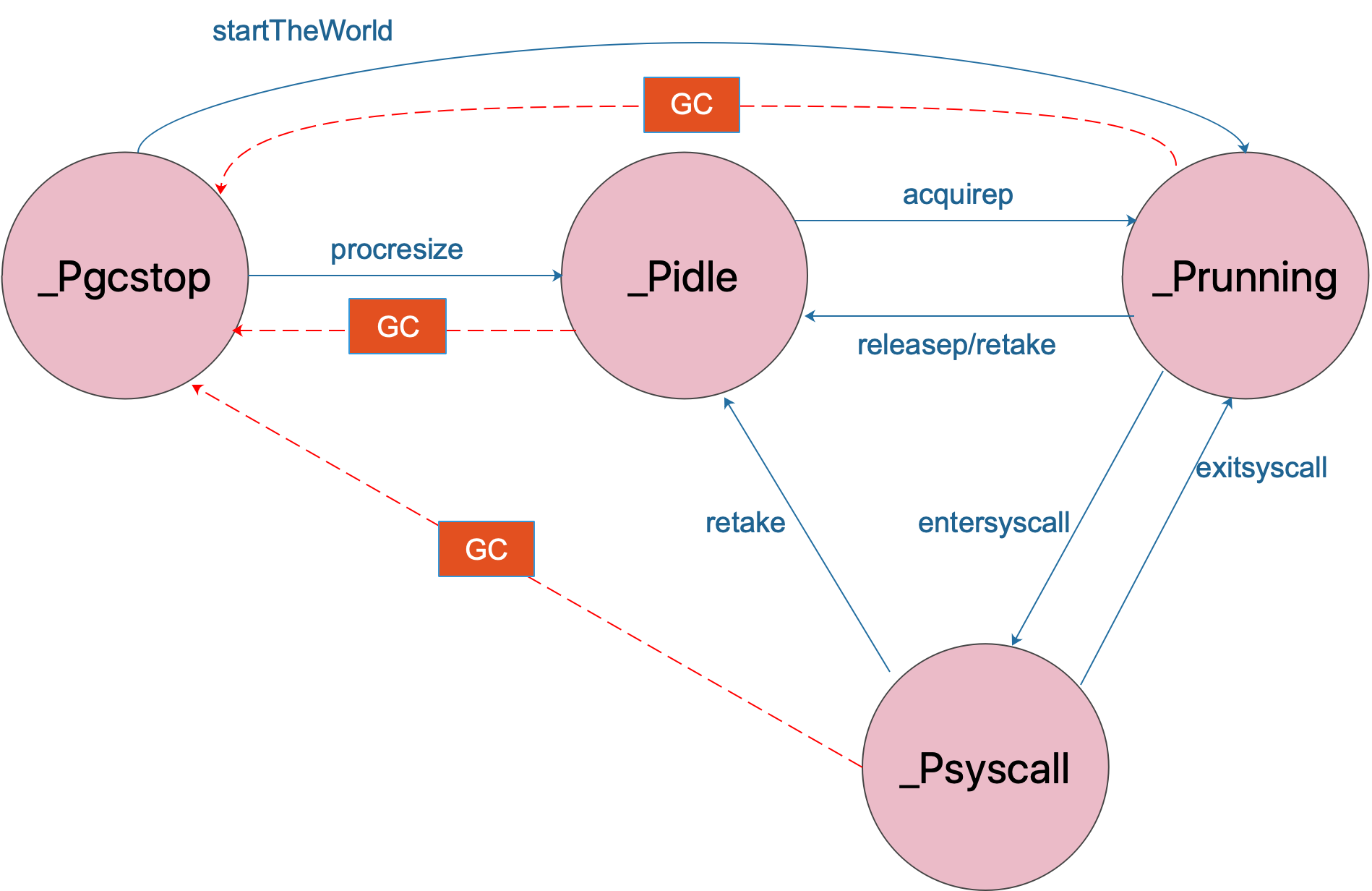
通常情况下(在程序运行时不调整 P 的个数),P 只会在上图中的四种状态下进行切换。 当程序刚开始运行进行初始化时,所有的 P 都处于
_Pgcstop状态, 随着 P 的初始化(runtime.procresize),会被置于_Pidle。
当 M 需要运行时,会
runtime.acquirep来使 P 变成Prunning状态,并通过runtime.releasep来释放。
当 G 执行时需要进入系统调用,P 会被设置为
_Psyscall, 如果这个时候被系统监控抢夺(runtime.retake),则 P 会被重新修改为_Pidle。
如果在程序运行中发生
GC,则 P 会被设置为_Pgcstop, 并在runtime.startTheWorld时重新调整为_Prunning。
最后,我们来看 M 的状态变化:

M 只有自旋和非自旋两种状态。自旋的时候,会努力找工作;找不到的时候会进入非自旋状态,之后会休眠,直到有工作需要处理时,被其他工作线程唤醒,又进入自旋状态。
8.7 描述 scheduler 的初始化过程
上一节我们说完了 GPM 结构体,这一讲,我们来研究 Go sheduler 结构体,以及整个调度器的初始化过程。
Go scheduler 在源码中的结构体为 schedt,保存调度器的状态信息、全局的可运行 G 队列等。源码如下:
// 保存调度器的信息
type schedt struct {
// accessed atomically. keep at top to ensure alignment on 32-bit systems.
// 需以原子访问访问。
// 保持在 struct 顶部,以使其在 32 位系统上可以对齐
goidgen uint64
lastpoll uint64
lock mutex
// 由空闲的工作线程组成的链表
midle muintptr // idle m's waiting for work
// 空闲的工作线程数量
nmidle int32 // number of idle m's waiting for work
// 空闲的且被 lock 的 m 计数
nmidlelocked int32 // number of locked m's waiting for work
// 已经创建的工作线程数量
mcount int32 // number of m's that have been created
// 表示最多所能创建的工作线程数量
maxmcount int32 // maximum number of m's allowed (or die)
// goroutine 的数量,自动更新
ngsys uint32 // number of system goroutines; updated atomically
// 由空闲的 p 结构体对象组成的链表
pidle puintptr // idle p's
// 空闲的 p 结构体对象的数量
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
// 全局可运行的 G队列
runqhead guintptr // 队列头
runqtail guintptr // 队列尾
runqsize int32 // 元素数量
// Global cache of dead G's.
// dead G 的全局缓存
// 已退出的 goroutine 对象,缓存下来
// 避免每次创建 goroutine 时都重新分配内存
gflock mutex
gfreeStack *g
gfreeNoStack *g
// 空闲 g 的数量
ngfree int32
// Central cache of sudog structs.
// sudog 结构的集中缓存
sudoglock mutex
sudogcache *sudog
// Central pool of available defer structs of different sizes.
// 不同大小的可用的 defer struct 的集中缓存池
deferlock mutex
deferpool [5]*_defer
gcwaiting uint32 // gc is waiting to run
stopwait int32
stopnote note
sysmonwait uint32
sysmonnote note
// safepointFn should be called on each P at the next GC
// safepoint if p.runSafePointFn is set.
safePointFn func(*p)
safePointWait int32
safePointNote note
profilehz int32 // cpu profiling rate
// 上次修改 gomaxprocs 的纳秒时间
procresizetime int64 // nanotime() of last change to gomaxprocs
totaltime int64 // ∫gomaxprocs dt up to procresizetime
}在程序运行过程中,schedt 对象只有一份实体,它维护了调度器的所有信息。
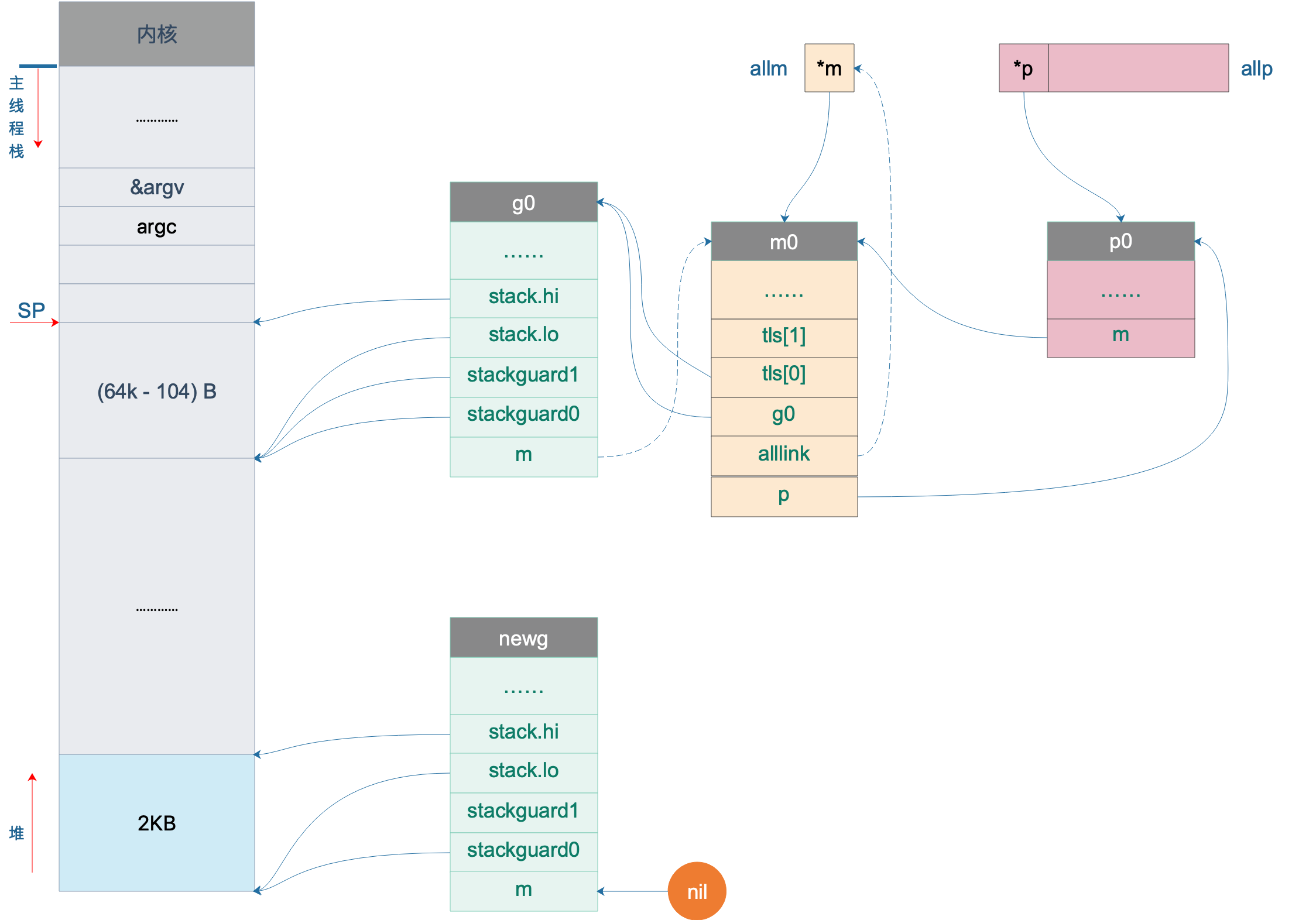
在 proc.go 和 runtime2.go 文件中,有一些很重要全局的变量,我们先列出来:
// 所有 g 的长度
allglen uintptr
// 保存所有的 g
allgs []*g
// 保存所有的 m
allm *m
// 保存所有的 p,_MaxGomaxprocs = 1024
allp [_MaxGomaxprocs + 1]*p
// p 的最大值,默认等于 ncpu
gomaxprocs int32
// 程序启动时,会调用 osinit 函数获得此值
ncpu int32
// 调度器结构体对象,记录了调度器的工作状态
sched schedt
// 代表进程的主线程
m0 m
// m0 的 g0,即 m0.g0 = &g0
g0 g在程序初始化时,这些全局变量都会被初始化为零值:指针被初始化为 nil 指针,切片被初始化为 nil 切片,int 被初始化为 0,结构体的所有成员变量按其类型被初始化为对应的零值。
因此程序刚启动时 allgs,allm 和allp 都不包含任何 g,m 和 p。
不仅是 Go 程序,系统加载可执行文件大概都会经过这几个阶段:
- 从磁盘上读取可执行文件,加载到内存
- 创建进程和主线程
- 为主线程分配栈空间
- 把由用户在命令行输入的参数拷贝到主线程的栈
- 把主线程放入操作系统的运行队列等待被调度
上面这段描述,来自公众号“go语言核心编程技术”的调度系列教程。
我们从一个 Hello World 的例子来回顾一下 Go 程序初始化的过程:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}在项目根目录下执行:
go build -gcflags "-N -l" -o hello src/main.go-gcflags "-N -l" 是为了关闭编译器优化和函数内联,防止后面在设置断点的时候找不到相对应的代码位置。
得到了可执行文件 hello,执行:
[qcrao@qcrao hello-world]$ gdb hello进入 gdb 调试模式,执行 info files,得到可执行文件的文件头,列出了各种段:

同时,我们也得到了入口地址:0x450e20。
(gdb) b *0x450e20
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.这就是 Go 程序的入口地址,我是在 linux 上运行的,所以入口文件为 src/runtime/rt0_linux_amd64.s,runtime 目录下有各种不同名称的程序入口文件,支持各种操作系统和架构,代码为:
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
LEAQ 8(SP), SI // argv
MOVQ 0(SP), DI // argc
MOVQ $main(SB), AX
JMP AX主要是把 argc,argv 从内存拉到了寄存器。这里 LEAQ 是计算内存地址,然后把内存地址本身放进寄存器里,也就是把 argv 的地址放到了 SI 寄存器中。最后跳转到:
TEXT main(SB),NOSPLIT,$-8
MOVQ $runtime·rt0_go(SB), AX
JMP AX继续跳转到 runtime·rt0_go(SB),完成 go 启动时所有的初始化工作。位于 /usr/local/go/src/runtime/asm_amd64.s,代码:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// copy arguments forward on an even stack
MOVQ DI, AX // argc
MOVQ SI, BX // argv
SUBQ $(4*8+7), SP // 2args 2auto
// 调整栈顶寄存器使其按 16 字节对齐
ANDQ $~15, SP
// argc 放在 SP+16 字节处
MOVQ AX, 16(SP)
// argv 放在 SP+24 字节处
MOVQ BX, 24(SP)
// create istack out of the given (operating system) stack.
// _cgo_init may update stackguard.
// 给 g0 分配栈空间
// 把 g0 的地址存入 DI
MOVQ $runtime·g0(SB), DI
// BX = SP - 64*1024 + 104
LEAQ (-64*1024+104)(SP), BX
// g0.stackguard0 = SP - 64*1024 + 104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1 = SP - 64*1024 + 104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo = SP - 64*1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi = SP
MOVQ SP, (g_stack+stack_hi)(DI)
// ……………………
// 省略了很多检测 CPU 信息的代码
// ……………………
// 初始化 m 的 tls
// DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
LEAQ runtime·m0+m_tls(SB), DI
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 之后,可通过 fs 段寄存器找到 m.tls
CALL runtime·settls(SB)
// store through it, to make sure it works
// 获取 fs 段基址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
ok:
// set the per-goroutine and per-mach "registers"
// 获取 fs 段基址到 BX 寄存器
get_tls(BX)
// 将 g0 的地址存储到 CX,CX = &g0
LEAQ runtime·g0(SB), CX
// 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0
MOVQ CX, g(BX)
// 将 m0 的地址存储到 AX,AX = &m0
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
// m0.g0 = &g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
// g0.m = &m0
MOVQ AX, g_m(CX)
CLD // convention is D is always left cleared
CALL runtime·check(SB)
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
// 初始化系统核心数
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
// newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数
// AX = &funcval{runtime·main},
PUSHQ AX
// newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小,
// 因为 runtime.main 没有参数,所以这里是 0
PUSHQ $0 // arg size
// 创建 main goroutine
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)
// 永远不会返回,万一返回了,crash 掉
MOVL $0xf1, 0xf1 // crash
RET这段代码完成之后,整个 Go 程序就可以跑起来了,是非常核心的代码。这一讲其实只讲到了第 80 行,也就是调度器初始化函数:
CALL runtime·schedinit(SB)schedinit 函数返回后,调度器的相关参数都已经初始化好了,犹如盘古开天辟地,万事万物各就其位。接下来详细解释上面的汇编代码。
调整 SP
第一段代码,将 SP 调整到了一个地址是 16 的倍数的位置:
SUBQ $(4*8+7), SP // 2args 2auto
// 调整栈顶寄存器使其按 16 个字节对齐
ANDQ $~15, SP先是将 SP 减掉 39,也就是向下移动了 39 个 Byte,再进行与运算。
15 的二进制低四位是全 1:1111,其他位都是 0;取反后,变成了 0000,高位则是全 1。这样,与 SP 进行了与运算后,低 4 位变成了全 0,高位则不变。因此 SP 继续向下移动,并且这回是在一个地址值为 16 的倍数的地方,16 字节对齐的地方。
为什么要这么做?画一张图就明白了。不过先得说明一点,前面 _rt0_amd64_linux 函数里讲过,DI 里存的是 argc 的值,8 个字节,而 SI 里则存的是 argv 的地址,8 个字节。

上面两张图中,左侧用箭头标注了 16 字节对齐的位置。第一步表示向下移动 39 B,第二步表示与 ~15 相与。
存在两种情况,这也是第一步将 SP 下移的时候,多移了 7 个 Byte 的原因。第一张图里,与 ~15 相与的时候,SP 值减少了 1,第二张图则减少了 9。最后都是移位到了 16 字节对齐的位置。
两张图的共同点是 SP 与 argc 中间多出了 16 个字节的空位。这个后面应该会用到,我们接着探索。
至于为什么进行 16 个字节对齐,就比较好理解了:因为 CPU 有一组 SSE 指令,这些指令中出现的内存地址必须是 16 的倍数。
初始化 g0 栈
接着往后看,开始初始化 g0 的栈了。g0 栈的作用就是为运行 runtime 代码提供一个“环境”。
// 把 g0 的地址存入 DI
MOVQ $runtime·g0(SB), DI
// BX = SP - 64*1024 + 104
LEAQ (-64*1024+104)(SP), BX
// g0.stackguard0 = SP - 64*1024 + 104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1 = SP - 64*1024 + 104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo = SP - 64*1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi = SP
MOVQ SP, (g_stack+stack_hi)(DI)代码 L2 把 g0 的地址存入 DI 寄存器;L4 将 SP 下移 (64K-104)B,并将地址存入 BX 寄存器;L6 将 BX 里存储的地址赋给 g0.stackguard0;L8,L10,L12 分别 将 BX 里存储的地址赋给 g0.stackguard1, g0.stack.lo, g0.stack.hi。
这部分完成之后,g0 栈空间如下图:
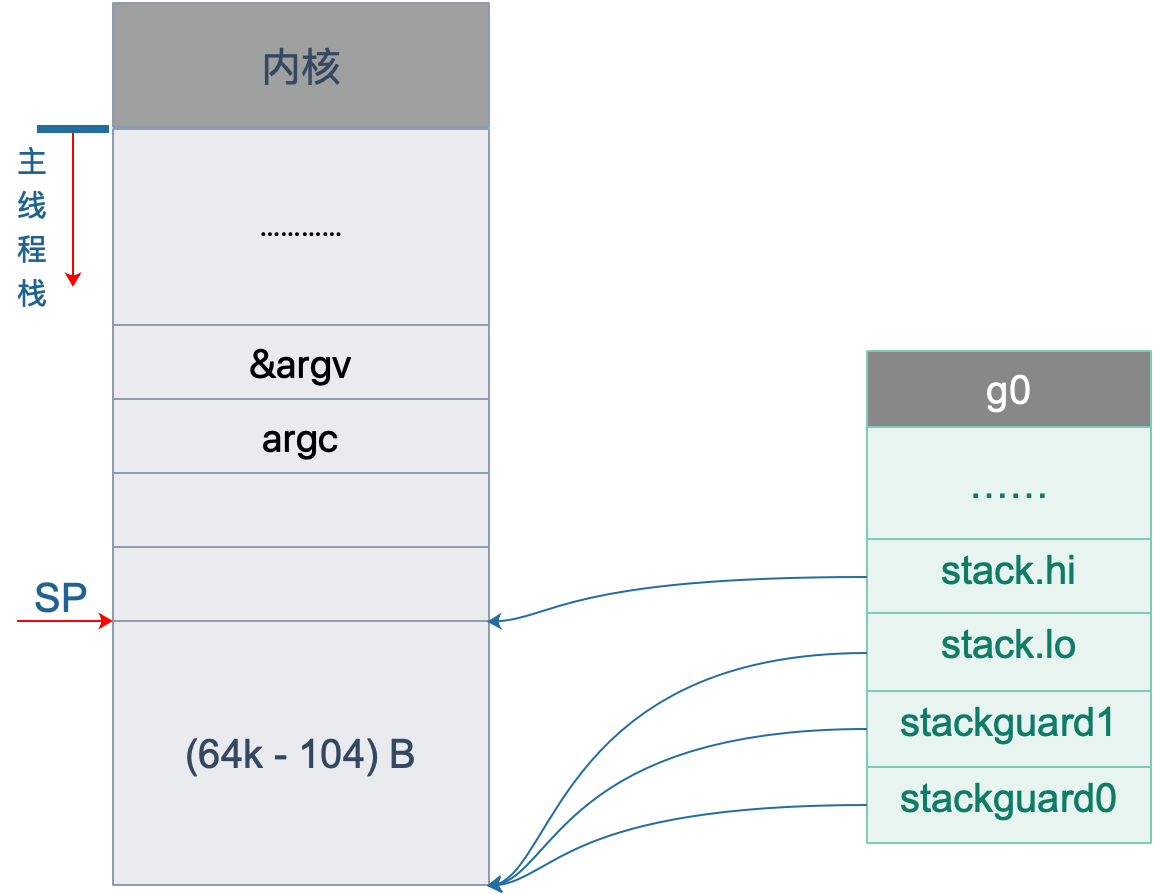
主线程绑定 m0
接着往下看,中间我们省略了很多检查 CPU 相关的代码,直接看主线程绑定 m0 的部分:
// 初始化 m 的 tls
// DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
LEAQ runtime·m0+m_tls(SB), DI
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 之后,可通过 fs 段寄存器找到 m.tls
CALL runtime·settls(SB)
// store through it, to make sure it works
// 获取 fs 段基地址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort因为 m0 是全局变量,而 m0 又要绑定到工作线程才能执行。我们又知道,runtime 会启动多个工作线程,每个线程都会绑定一个 m0。而且,代码里还得保持一致,都是用 m0 来表示。这就要用到线程本地存储的知识了,也就是常说的 TLS(Thread Local Storage)。简单来说,TLS 就是线程本地的私有的全局变量。
一般而言,全局变量对进程中的多个线程同时可见。进程中的全局变量与函数内定义的静态(static)变量,是各个线程都可以访问的共享变量。一个线程修改了,其他线程就会“看见”。要想搞出一个线程私有的变量,就需要用到 TLS 技术。
如果需要在一个线程内部的各个函数调用都能访问、但其它线程不能访问的变量(被称为 static memory local to a thread,线程局部静态变量),就需要新的机制来实现。这就是 TLS。
继续来看源码,L3 将 m0.tls 地址存储到 DI 寄存器,再调用 settls 完成 tls 的设置,tls 是 m 结构体中的一个数组。
// thread-local storage (for x86 extern register)
tls [6]uintptr设置 tls 的函数 runtime·settls(SB) 位于源码 src/runtime/sys_linux_amd64.s 处,主要内容就是通过一个系统调用将 fs 段基址设置成 m.tls[1] 的地址,而 fs 段基址又可以通过 CPU 里的寄存器 fs 来获取。
而每个线程都有自己的一组 CPU 寄存器值,操作系统在把线程调离 CPU 时会帮我们把所有寄存器中的值保存在内存中,调度线程来运行时又会从内存中把这些寄存器的值恢复到 CPU。
这样,工作线程代码就可以通过 fs 寄存器来找到 m.tls。
关于 settls 这个函数的解析可以去看阿波张的教程第 12 篇,写得很详细。
设置完 tls 之后,又来了一段验证上面 settls 是否能正常工作。如果不能,会直接 crash。
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort第一行代码,获取 tls,get_tls(BX) 的代码由编译器生成,源码中并没有看到,可以理解为将 m.tls 的地址存入 BX 寄存器。
L2 将一个数 0x123 放入 m.tls[0] 处,L3 则将 m.tls[0] 处的数据取出来放到 AX 寄存器,L4 则比较两者是否相等。如果相等,则跳过 L6 行的代码,否则执行 L6,程序 crash。
继续看代码:
// set the per-goroutine and per-mach "registers"
// 获取 fs 段基址到 BX 寄存器
get_tls(BX)
// 将 g0 的地址存储到 CX,CX = &g0
LEAQ runtime·g0(SB), CX
// 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0
MOVQ CX, g(BX)
// 将 m0 的地址存储到 AX,AX = &m0
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
// m0.g0 = &g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
// g0.m = &m0
MOVQ AX, g_m(CX)L3 将 m.tls 地址存入 BX;L5 将 g0 的地址存入 CX;L7 将 CX,也就是 g0 的地址存入 m.tls[0];L9 将 m0 的地址存入 AX;L13 将 g0 的地址存入 m0.g0;L16 将 m0 存入 g0.m。也就是:
tls[0] = g0
m0.g0 = &g0
g0.m = &m0代码中寄存器前面的符号看着比较奇怪,其实它们最后会被链接器转化为偏移量。
看曹大 golang_notes 用 gobuf_sp(BX) 这个例子讲的:
这种写法在标准 plan9 汇编中只是个 symbol,没有任何偏移量的意思,但这里却用名字来代替了其偏移量,这是怎么回事呢?
实际上这是 runtime 的特权,是需要链接器配合完成的,再来看看 gobuf 在 runtime 中的 struct 定义开头部分的注释:
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
对于我们而言,这种写法读起来比较容易。
这一段执行完之后,就把 m0,g0,m.tls[0] 串联起来了。通过 m.tls[0] 可以找到 g0,通过 g0 可以找到 m0(通过 g 结构体的 m 字段)。并且,通过 m 的字段 g0,m0 也可以找到 g0。于是,主线程和 m0,g0 就关联起来了。
从这里还可以看到,保存在主线程本地存储中的值是 g0 的地址,也就是说工作线程的私有全局变量其实是一个指向 g 的指针而不是指向 m 的指针。
目前这个指针指向g0,表示代码正运行在 g0 栈。
于是,前面的图又增加了新的玩伴 m0:
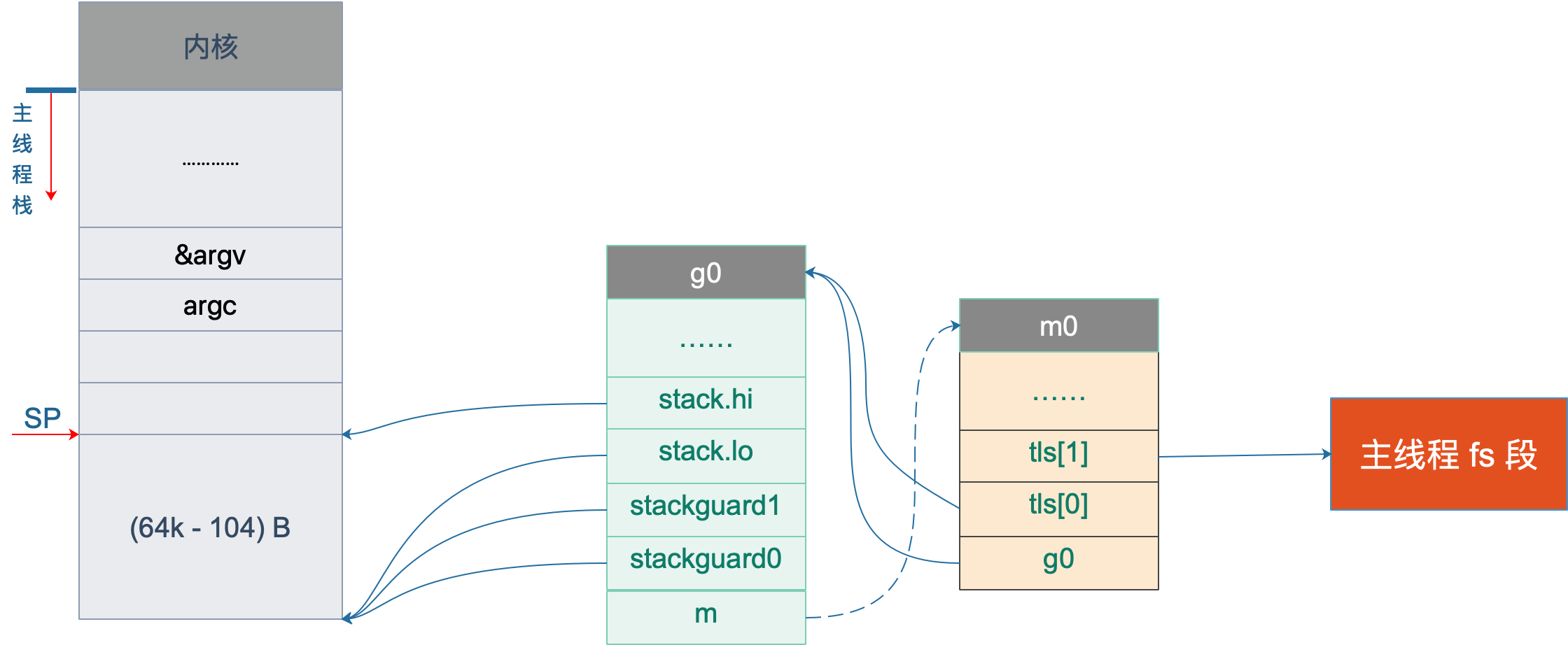
初始化 m0
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
// 初始化系统核心数
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)L1-L2 将 16(SP) 处的内容移动到 0(SP),也就是栈顶,通过前面的图,16(SP) 处的内容为 argc;L3-L4 将 argv 存入 8(SP),接下来调用 runtime·args 函数,处理命令行参数。
接着,连续调用了两个 runtime 函数。osinit 函数初始化系统核心数,将全局变量 ncpu 初始化的核心数,schedinit 则是本文的核心:调度器的初始化。
下面,我们来重点看 schedinit 函数:
// src/runtime/proc.go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
// getg 由编译器实现
// get_tls(CX)
// MOVQ g(CX), BX; BX存器里面现在放的是当前g结构体对象的地址
_g_ := getg()
if raceenabled {
_g_.racectx, raceprocctx0 = raceinit()
}
// 最多启动 10000 个工作线程
sched.maxmcount = 10000
tracebackinit()
moduledataverify()
// 初始化栈空间复用管理链表
stackinit()
mallocinit()
// 初始化 m0
mcommoninit(_g_.m)
alginit() // maps must not be used before this call
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
msigsave(_g_.m)
initSigmask = _g_.m.sigmask
goargs()
goenvs()
parsedebugvars()
gcinit()
sched.lastpoll = uint64(nanotime())
// 初始化 P 的个数
// 系统中有多少核,就创建和初始化多少个 p 结构体对象
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procs > _MaxGomaxprocs {
procs = _MaxGomaxprocs
}
// 初始化所有的 P,正常情况下不会返回有本地任务的 P
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
// ……………………
}这个函数开头的注释很贴心地把 Go 程序初始化的过程又说了一遍:
- call osinit。初始化系统核心数。
- call schedinit。初始化调度器。
- make & queue new G。创建新的 goroutine。
- call runtime·mstart。调用 mstart,启动调度。
- The new G calls runtime·main。在新的 goroutine 上运行 runtime.main 函数。
函数首先调用 getg() 函数获取当前正在运行的 g,getg() 在 src/runtime/stubs.go 中声明,真正的代码由编译器生成。
// getg returns the pointer to the current g.
// The compiler rewrites calls to this function into instructions
// that fetch the g directly (from TLS or from the dedicated register).
func getg() *g注释里也说了,getg 返回当前正在运行的 goroutine 的指针,它会从 tls 里取出 tls[0],也就是当前运行的 goroutine 的地址。编译器插入类似下面的代码:
get_tls(CX)
MOVQ g(CX), BX; // BX存器里面现在放的是当前g结构体对象的地址继续往下看:
sched.maxmcount = 10000设置最多只能创建 10000 个工作线程。
然后,调用了一堆 init 函数,初始化各种配置,现在不去深究。只关心本小节的重点,m0 的初始化:
// 初始化 m
func mcommoninit(mp *m) {
// 初始化过程中_g_ = g0
_g_ := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if _g_ != _g_.m.g0 {
callers(1, mp.createstack[:])
}
// random 初始化
mp.fastrand = 0x49f6428a + uint32(mp.id) + uint32(cputicks())
if mp.fastrand == 0 {
mp.fastrand = 0x49f6428a
}
lock(&sched.lock)
// 设置 m 的 id
mp.id = sched.mcount
sched.mcount++
// 检查已创建系统线程是否超过了数量限制(10000)
checkmcount()
// ………………省略了初始化 gsignal
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
// ………………
}因为 sched 是一个全局变量,多个线程同时操作 sched 会有并发问题,因此先要加锁,操作结束之后再解锁。
mp.id = sched.mcount
sched.mcount++
checkmcount()可以看到,m0 的 id 是 0,并且之后创建的 m 的 id 是递增的。checkmcount() 函数检查已创建系统线程是否超过了数量限制(10000)。
mp.alllink = allm将 m 挂到全局变量 allm 上,allm 是一个指向 m 的的指针。
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))这一行将 allm 变成 m 的地址,这样变成了一个循环链表。之后再新建 m 的时候,新 m 的 alllink 就会指向本次的 m,最后 allm 又会指向新创建的 m。

上图中,1 将 m0 挂在 allm 上。之后,若新创建 m,则 m1 会和 m0 相连。
完成这些操作后,大功告成!解锁。
初始化 allp
跳过一些其他的初始化代码,继续往后看:
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procs > _MaxGomaxprocs {
procs = _MaxGomaxprocs
}这里就是设置 procs,它决定创建 P 的数量。ncpu 这里已经被赋上了系统的核心数,因此代码里不设置 GOMAXPROCS 也是没问题的。这里还限制了 procs 的最大值,为 1024。
来看最后一个核心的函数:
// src/runtime/proc.go
func procresize(nprocs int32) *p {
old := gomaxprocs
if old < 0 || old > _MaxGomaxprocs || nprocs <= 0 || nprocs > _MaxGomaxprocs {
throw("procresize: invalid arg")
}
// ……………………
// update statistics
// 更新数据
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
// 初始化所有的 P
for i := int32(0); i < nprocs; i++ {
pp := allp[i]
if pp == nil {
// 申请新对象
pp = new(p)
pp.id = i
// pp 的初始状态为 stop
pp.status = _Pgcstop
pp.sudogcache = pp.sudogbuf[:0]
for i := range pp.deferpool {
pp.deferpool[i] = pp.deferpoolbuf[i][:0]
}
// 将 pp 存放到 allp 处
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
// ……………………
}
// 释放多余的 P。由于减少了旧的 procs 的数量,因此需要释放
// ……………………
// 获取当前正在运行的 g 指针,初始化时 _g_ = g0
_g_ := getg()
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// continue to use the current P
// 继续使用当前 P
_g_.m.p.ptr().status = _Prunning
} else {
// 初始化时执行这个分支
// ……………………
_g_.m.p = 0
_g_.m.mcache = nil
// 取出第 0 号 p
p := allp[0]
p.m = 0
p.status = _Pidle
// 将 p0 和 m0 关联起来
acquirep(p)
if trace.enabled {
traceGoStart()
}
}
var runnablePs *p
// 下面这个 for 循环把所有空闲的 p 放入空闲链表
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
// allp[0] 跟 m0 关联了,不会进行之后的“放入空闲链表”
if _g_.m.p.ptr() == p {
continue
}
// 状态转为 idle
p.status = _Pidle
// p 的 LRQ 里没有 G
if runqempty(p) {
// 放入全局空闲链表
pidleput(p)
} else {
p.m.set(mget())
p.link.set(runnablePs)
runnablePs = p
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
// 返回有本地任务的 P 链表
return runnablePs
}
代码比较长,这个函数不仅是初始化的时候会执行到,在中途改变 procs 的值的时候,仍然会调用它。所有存在很多一般不用关心的代码,因为一般不会在中途重新设置 procs 的值。我把初始化无关的代码删掉了,这样会更清晰一些。
函数先是从堆上创建了 nproc 个 P,并且把 P 的状态设置为 _Pgcstop,现在全局变量 allp 里就维护了所有的 P。
接着,调用函数 acquirep 将 p0 和 m0 关联起来。我们来详细看一下:
func acquirep(_p_ *p) {
// Do the part that isn't allowed to have write barriers.
acquirep1(_p_)
// have p; write barriers now allowed
_g_ := getg()
_g_.m.mcache = _p_.mcache
// ……………………
}先调用 acquirep1 函数真正地进行关联,之后,将 p0 的 mcache 资源赋给 m0。再来看 acquirep1:
func acquirep1(_p_ *p) {
_g_ := getg()
// ……………………
_g_.m.p.set(_p_)
_p_.m.set(_g_.m)
_p_.status = _Prunning
}可以看到就是一些字段相互设置,执行完成后:
g0.m.p = p0
p0.m = m0并且,p0 的状态变成了 _Prunning。
接下来是一个循环,它将除了 p0 的所有非空闲的 P,放入 P 链表 runnablePs,并返回给 procresize 函数的调用者,并由调用者来“调度”这些 P。
函数 runqempty 用来判断一个 P 是否是空闲,依据是 P 的本地 run queue 队列里有没有 runnable 的 G,如果没有,那 P 就是空闲的。
// src/runtime/proc.go
// 如果 _p_ 的本地队列里没有待运行的 G,则返回 true
func runqempty(_p_ *p) bool {
// 这里涉及到一些数据竞争,并不是简单地判断 runqhead == runqtail 并且 runqnext == nil 就可以
//
for {
head := atomic.Load(&_p_.runqhead)
tail := atomic.Load(&_p_.runqtail)
runnext := atomic.Loaduintptr((*uintptr)(unsafe.Pointer(&_p_.runnext)))
if tail == atomic.Load(&_p_.runqtail) {
return head == tail && runnext == 0
}
}
}并不是简单地判断 head == tail 并且 runnext == nil 为真,就可以说明 runq 是空的。因为涉及到一些数据竞争,例如在比较 head == tail 时为真,但此时 runnext 上其实有一个 G,之后再去比较 runnext == nil 的时候,这个 G 又通过 runqput 跑到了 runq 里去了或者通过 runqget 拿走了,runnext 也为真,于是函数就判断这个 P 是空闲的,这就会形成误判。
因此 runqempty 函数先是通过原子操作取出了 head,tail,runnext,然后再次确认 tail 没有发生变化,最后再比较 head == tail 以及 runnext == nil,保证了在观察三者都是在“同时”观察到的,因此,返回的结果就是正确的。
说明一下,runnext 上有时会绑定一个 G,这个 G 是被当前 G 唤醒的,相比其他 G 有更高的执行优先级,因此把它单独拿出来。
函数的最后,初始化了一个“随机分配器”:
stealOrder.reset(uint32(nprocs))将来有些 m 去偷工作的时候,会遍历所有的 P,这时为了偷地随机一些,就会用到 stealOrder 来返回一个随机选择的 P,后面的文章会再讲。
这样,整个 procresize 函数就讲完了,这也意味着,调度器的初始化工作已经完成了。
还是引用阿波张公号文章里的总结,写得太好了,很简洁,很难再优化了:
- 使用 make([]p, nprocs) 初始化全局变量 allp,即 allp = make([]p, nprocs)
- 循环创建并初始化 nprocs 个 p 结构体对象并依次保存在 allp 切片之中
- 把 m0 和 allp[0] 绑定在一起,即 m0.p = allp[0],allp[0].m = m0
- 把除了 allp[0] 之外的所有 p 放入到全局变量 sched 的 pidle 空闲队列之中
说明一下,最后一步,代码里是将所有空闲的 P 放入到调度器的全局空闲队列;对于非空闲的 P(本地队列里有 G 待执行),则是生成一个 P 链表,返回给 procresize 函数的调用者。
最后我们将 allp 和 allm 都添加到图上:

8.8 主 goroutine 怎么创建
上一讲我们讲完了 Go scheduler 的初始化,现在调度器一切就绪,就差被调度的实体了。本文就来讲述 main goroutine 是如何诞生,并且被调度的。
继续看代码,前面我们完成了 schedinit 函数,这是 runtime·rt0_go 函数里的一步,接着往后看:
// 创建一个新的 goroutine 来启动程序
MOVQ $runtime·mainPC(SB), AX // entry
// newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数
// AX = &funcval{runtime·main},
PUSHQ AX
// newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小,
// 因为 runtime.main 没有参数,所以这里是 0
PUSHQ $0 // arg size
// 创建 main goroutine
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)
// 永远不会返回,万一返回了,crash 掉
MOVL $0xf1, 0xf1 // crash
RET代码前面几行是在为调用 newproc 函数“构造栈”,执行完 runtime·newproc(SB) 后,就会以一个新的 goroutine 来执行 mainPC 也就是 runtime.main() 函数。runtime.main() 函数最终会执行到我们写的 main 函数,舞台交给我们。
重点来看 newproc 函数:
// src/runtime/proc.go
// 创建一个新的 g,运行 fn 函数,需要 siz byte 的参数
// 将其放至 G 队列等待运行
// 编译器会将 go 关键字的语句转化成此函数
//go:nosplit
func newproc(siz int32, fn *funcval)从这里开始要进入 hard 模式了,打起精神!当我们随手一句:
go func() {
// 要做的事
}()就启动了一个 goroutine 的时候,一定要知道,在 Go 编译器的作用下,这条语句最终会转化成 newproc 函数。
因此,newproc 函数需要两个参数:一个是新创建的 goroutine 需要执行的任务,也就是 fn,它代表一个函数 func;还有一个是 fn 的参数大小。
再回过头看,构造 newproc 函数调用栈的时候,第一个参数是 0,因为 runtime.main 函数没有参数:
// src/runtime/proc.go
func main()第二个参数则是 runtime.main 函数的地址。
可能会感到奇怪,为什么要给 newproc 传一个表示 fn 的参数大小的参数呢?
我们知道,goroutine 和线程一样,都有自己的栈,不同的是 goroutine 的初始栈比较小,只有 2K,而且是可伸缩的,这也是创建 goroutine 的代价比创建线程代价小的原因。
换句话说,每个 goroutine 都有自己的栈空间,newproc 函数会新创建一个新的 goroutine 来执行 fn 函数,在新 goroutine 上执行指令,就要用新 goroutine 的栈。而执行函数需要参数,这个参数又是在老的 goroutine 上,所以需要将其拷贝到新 goroutine 的栈上。拷贝的起始位置就是栈顶,这好办,那拷贝多少数据呢?由 siz 来确定。
继续看代码,newproc 函数的第二个参数:
type funcval struct {
fn uintptr
// variable-size, fn-specific data here
}它是一个变长结构,第一个字段是一个指针 fn,内存中,紧挨着 fn 的是函数的参数。
参考资料【欧神 关键字 go】有一个例子:
package main
func hello(msg string) {
println(msg)
}
func main() {
go hello("hello world")
}栈布局是这样的:

栈顶是 siz,再往上是函数的地址,再往上就是传给 hello 函数的参数,string 在这里是一个地址。因此前面代码里先 push 参数的地址,再 push 参数大小。
// src/runtime/proc.go
//go:nosplit
func newproc(siz int32, fn *funcval) {
// 获取第一个参数地址
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
// 获取调用者的指令地址,也就是调用 newproc 时由 call 指令压栈的函数返回地址
pc := getcallerpc(unsafe.Pointer(&siz))
// systemstack 的作用是切换到 g0 栈执行作为参数的函数
// 用 g0 系统栈创建 goroutine 对象
// 传递的参数包括 fn 函数入口地址,argp 参数起始地址,siz 参数长度,调用方 pc(goroutine)
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, 0, pc)
})
}因此,argp 跳过 fn,向上跳一个指针的长度,拿到 fn 参数的地址。
接着通过 getcallerpc 获取调用者的指令地址,也就是调用 newproc 时由 call 指令压栈的函数返回地址,也就是 runtime·rt0_go 函数里 CALL runtime·newproc(SB) 指令后面的 POPQ AX 这条指令的地址。
最后,调用 systemstack 函数在 g0 栈执行 fn 函数。由于本文讲述的是初始化过程中,由 runtime·rt0_go 函数调用,本身是在 g0 栈执行,因此会直接执行 fn 函数。而如果是我们在程序中写的 go xxx 代码,在执行时,就会先切换到 g0 栈执行,然后再切回来。
一鼓作气,继续看 newproc1 函数,为了连贯性,我先将整个函数的代码贴出来,并且加上了注释。当然,这篇文章不会涉及到所有的代码,只会讲部分内容。放在这里,方便阅读后面的文章时对照:
// 创建一个新的 g 来跑 fn
func newproc1(fn *funcval, argp *uint8, narg int32, nret int32, callerpc uintptr) *g {
// 当前 goroutine 的指针
// 因为已经切换到 g0 栈,所以无论什么场景都是 _g_ = g0
// g0 是指当前工作线程的 g0
_g_ := getg()
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
_g_.m.locks++ // disable preemption because it can be holding p in a local var
// 参数加返回值所需要的空间(经过内存对齐)
siz := narg + nret
siz = (siz + 7) &^ 7
// …………………………
// 当前工作线程所绑定的 p
// 初始化时 _p_ = g0.m.p,也就是 _p_ = allp[0]
_p_ := _g_.m.p.ptr()
// 从 p 的本地缓冲里获取一个没有使用的 g,初始化时为空,返回 nil
newg := gfget(_p_)
if newg == nil {
// new 一个 g 结构体对象,然后从堆上为其分配栈,并设置 g 的 stack 成员和两个 stackgard 成员
newg = malg(_StackMin)
// 初始化 g 的状态为 _Gdead
casgstatus(newg, _Gidle, _Gdead)
// 放入全局变量 allgs 切片中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
// 计算运行空间大小,对齐
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
// 确定 sp 位置
sp := newg.stack.hi - totalSize
// 确定参数入栈位置
spArg := sp
// …………………………
if narg > 0 {
// 将参数从执行 newproc 函数的栈拷贝到新 g 的栈
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
// …………………………
}
// 把 newg.sched 结构体成员的所有成员设置为 0
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
// 设置 newg 的 sched 成员,调度器需要依靠这些字段才能把 goroutine 调度到 CPU 上运行
newg.sched.sp = sp
newg.stktopsp = sp
// newg.sched.pc 表示当 newg 被调度起来运行时从这个地址开始执行指令
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
// 设置 newg 的 startpc 为 fn.fn,该成员主要用于函数调用栈的 traceback 和栈收缩
// newg 真正从哪里开始执行并不依赖于这个成员,而是 sched.pc
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg) {
atomic.Xadd(&sched.ngsys, +1)
}
newg.gcscanvalid = false
// 设置 g 的状态为 _Grunnable,可以运行了
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
// 设置 goid
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
// ……………………
// 将 G 放入 _p_ 的本地待运行队列
runqput(_p_, newg, true)
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
_g_.m.locks--
if _g_.m.locks == 0 && _g_.preempt {
_g_.stackguard0 = stackPreempt
}
return newg
}当前代码在 g0 栈上执行,因此执行完 _g_ := getg() 之后,无论是在什么情况下都可以得到 _g_ = g0。之后通过 g0 找到其绑定的 P,也就是 p0。
接着,尝试从 p0 上找一个空闲的 G:
// 从 p 的本地缓冲里获取一个没有使用的 g,初始化时为空,返回 nil
newg := gfget(_p_)如果拿不到,则会在堆上创建一个新的 G,为其分配 2KB 大小的栈,并设置好新 goroutine 的 stack 成员,设置其状态为 _Gdead,并将其添加到全局变量 allgs 中。创建完成之后,我们就在堆上有了一个 2K 大小的栈。于是,我们的图再次丰富:
这样,main goroutine 就诞生了。
8.9 g0 栈和用户栈如何切换
上一讲讲完了 main goroutine 的诞生,它不是第一个,算上 g0,它要算第二个了。不过,我们要考虑的就是这个 goroutine,它会真正执行用户代码。
g0 栈用于执行调度器的代码,执行完之后,要跳转到执行用户代码的地方,如何跳转?这中间涉及到栈和寄存器的切换。要知道,函数调用和返回主要靠的也是 CPU 寄存器的切换。goroutine 的切换和此类似。
继续看 proc1 函数的代码。中间有一段调整运行空间的代码,计算出的结果一般为 0,也就是一般不会调整 SP 的位置,忽略好了。
// 确定参数入栈位置
spArg := sp参数的入参位置也是从 SP 处开始,通过:
// 将参数从执行 newproc 函数的栈拷贝到新 g 的栈
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))将 fn 的参数从 g0 栈上拷贝到 newg 的栈上,memmove 函数需要传入源地址、目的地址、参数大小。由于 main 函数在这里没有参数需要拷贝,因此这里相当于没做什么。
接着,初始化 newg 的各种字段,而且涉及到最重要的 pc,sp 等字段:
// 把 newg.sched 结构体成员的所有成员设置为 0
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
// 设置 newg 的 sched 成员,调度器需要依靠这些字段才能把 goroutine 调度到 CPU 上运行
newg.sched.sp = sp
newg.stktopsp = sp
// newg.sched.pc 表示当 newg 被调度起来运行时从这个地址开始执行指令
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
// 设置 newg 的 startpc 为 fn.fn,该成员主要用于函数调用栈的 traceback 和栈收缩
// newg 真正从哪里开始执行并不依赖于这个成员,而是 sched.pc
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}首先,memclrNoHeapPointers 将 newg.sched 的内存全部清零。接着,设置 sched 的 sp 字段,当 goroutine 被调度到 m 上运行时,需要通过 sp 字段来指示栈顶的位置,这里设置的就是新栈的栈顶位置。
最关键的一行来了:
// newg.sched.pc 表示当 newg 被调度起来运行时从这个地址开始执行指令
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function设置 pc 字段为函数 goexit 的地址加 1,也说是 goexit 函数的第二条指令,goexit 函数是 goroutine 退出后的一些清理工作。有点奇怪,这是要干嘛?接着往后看。
newg.sched.g = guintptr(unsafe.Pointer(newg))设置 g 字段为 newg 的地址。插一句,sched 是 g 结构体的一个字段,它本身也是一个结构体,保存调度信息。复习一下:
type gobuf struct {
// 存储 rsp 寄存器的值
sp uintptr
// 存储 rip 寄存器的值
pc uintptr
// 指向 goroutine
g guintptr
ctxt unsafe.Pointer // this has to be a pointer so that gc scans it
// 保存系统调用的返回值
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}接下来的这个函数非常重要,可以解释之前为什么要那样设置 pc 字段的值。调用 gostartcallfn:
gostartcallfn(&newg.sched, fn) //调整sched成员和newg的栈传入 newg.sched 和 fn。
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
// fn: gorotine 的入口地址,初始化时对应的是 runtime.main
fn = unsafe.Pointer(fv.fn)
} else {
fn = unsafe.Pointer(funcPC(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
// newg 的栈顶,目前 newg 栈上只有 fn 函数的参数,sp 指向的是 fn 的第一参数
sp := buf.sp
// …………………………
// 为返回地址预留空间
sp -= sys.PtrSize
// 这里填的是 newproc1 函数里设置的 goexit 函数的第二条指令
// 伪装 fn 是被 goexit 函数调用的,使得 fn 执行完后返回到 goexit 继续执行,从而完成清理工作
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
// 重新设置 buf.sp
buf.sp = sp
// 当 goroutine 被调度起来执行时,会从这里的 pc 值开始执行,初始化时就是 runtime.main
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}函数 gostartcallfn 只是拆解出了包含在 funcval 结构体里的函数指针,转过头就调用 gostartcall。将 sp 减小了一个指针的位置,这是给返回地址留空间。果然接着就把 buf.pc 填入了栈顶的位置:
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc原来 buf.pc 只是做了一个搬运工,搞什么啊。重新设置 buf.sp 为送减掉一个指针位置之后的值,设置 buf.pc 为 fn,指向要执行的函数,这里就是指的 runtime.main 函数。
对嘛,这才是应有的操作。之后,当调度器“光顾”此 goroutine 时,取出 buf.sp 和 buf.pc,恢复 CPU 相应的寄存器,就可以构造出 goroutine 的运行环境。
而 goexit 函数也通过“偷天换日”将自己的地址“强行”放到 newg 的栈顶,达到自己不可告人的目的:每个 goroutine 执行完之后,都要经过我的一些清理工作,才能“放行”。这样一说,goexit 函数还真是无私,默默地做一些“扫尾”的工作。
设置完 newg.sched 这后,我们的图又可以前进一步:
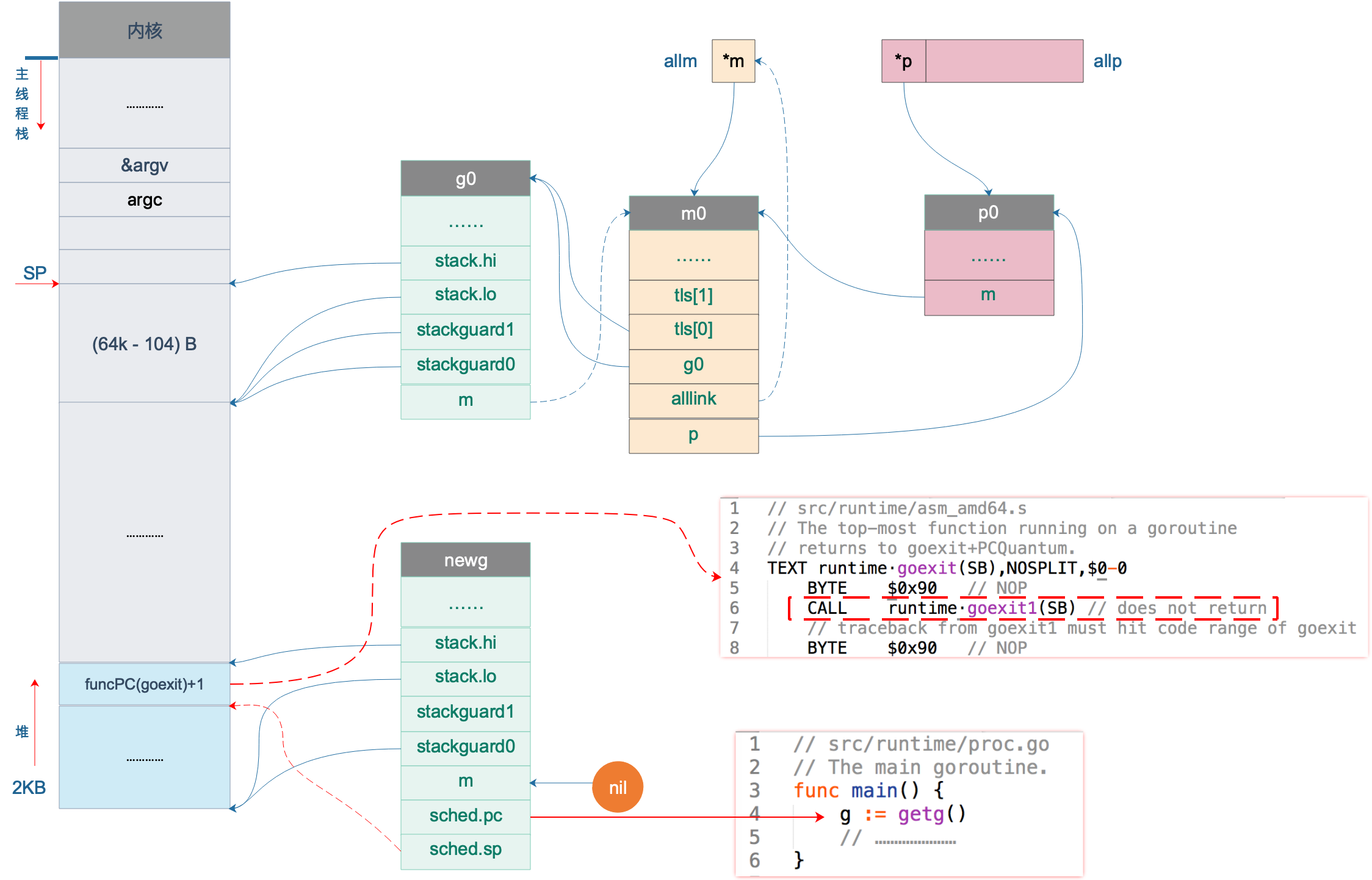
上图中,newg 新增了 sched.pc 指向 runtime.main 函数,当它被调度起来执行时,就从这里开始;新增了 sched.sp 指向了 newg 栈顶位置,同时,newg 栈顶位置的内容是一个跳转地址,指向 runtime.goexit 的第二条指令,当 goroutine 退出时,这条地址会载入 CPU 的 PC 寄存器,跳转到这里执行“扫尾”工作。
之后,将 newg 的状态改为 runnable,设置 goroutine 的 id:
// 设置 g 的状态为 _Grunnable,可以运行了
casgstatus(newg, _Gdead, _Grunnable)
newg.goid = int64(_p_.goidcache)每个 P 每次会批量(16个)申请 id,每次调用 newproc 函数,新创建一个 goroutine,id 加 1。因此 g0 的 id 是 0,而 main goroutine 的 id 就是 1。
newg 的状态变成可执行后(Runnable),就可以将它加入到 P 的本地运行队列里,等待调度。所以,goroutine 何时被执行,用户代码决定不了。来看源码:
// 将 G 放入 _p_ 的本地待运行队列
runqput(_p_, newg, true)
// runqput 尝试将 g 放到本地可执行队列里。
// 如果 next 为假,runqput 将 g 添加到可运行队列的尾部
// 如果 next 为真,runqput 将 g 添加到 p.runnext 字段
// 如果 run queue 满了,runnext 将 g 放到全局队列里
//
// runnext 成员中的 goroutine 会被优先调度起来运行
func runqput(_p_ *p, gp *g, next bool) {
// ……………………
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
// 有其它线程在操作 runnext 成员,需要重试
goto retryNext
}
// 老的 runnext 为 nil,不用管了
if oldnext == 0 {
return
}
// 把之前的 runnext 踢到正常的 runq 中
// 原本存放在 runnext 的 gp 放入 runq 的尾部
gp = oldnext.ptr()
}
retry:
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
// 如果 P 的本地队列没有满,入队
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
// 原子写入
atomic.Store(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 可运行队列已经满了,放入全局队列了
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
// 没有成功放入全局队列,说明本地队列没满,重试一下
goto retry
}runqput 函数的主要作用就是将新创建的 goroutine 加入到 P 的可运行队列,如果本地队列满了,则加入到全局可运行队列。前两个参数都好理解,最后一个参数 next 的作用是,当它为 true 时,会将 newg 加入到 P 的 runnext 字段,具有最高优先级,将先于普通队列中的 goroutine 得到执行。
先将 P 老的 runnext 成员取出,接着用一个原子操作 cas 来试图将 runnext 成员设置成 newg,目的是防止其他线程在同时修改 runnext 字段。
设置成功之后,相当于 newg “挤掉” 了原来老的处于 runnext 的 goroutine,还得给人遣散费,安顿好人家嘛,不然和强盗有何区别?
“安顿”的动作在 retry 代码段中执行。先通过 head,tail,len(_p_.runq) 来判断队列是否已满,如果没满,则直接写到队列尾部,同时修改队列尾部的指针。
// store-release, makes it available for consumption
atomic.Store(&_p_.runqtail, t+1)这里使用原子操作写入 runtail,防止编译器和 CPU 指令重排,保证上一行代码对 runq 的修改发生在修改 runqtail 之前,并且保证当前线程对队列的修改对其它线程立即可见。
如果本地队列满了,那就只能试图将 newg 添加到全局可运行队列中了。调用 runqputslow(_p_, gp, h, t) 完成。
// 将 g 和 _p_ 本地队列的一半 goroutine 放入全局队列。
// 因为要获取锁,所以会慢
func runqputslow(_p_ *p, gp *g, h, t uint32) bool {
var batch [len(_p_.runq)/2 + 1]*g
// First, grab a batch from local queue.
n := t - h
n = n / 2
if n != uint32(len(_p_.runq)/2) {
throw("runqputslow: queue is not full")
}
for i := uint32(0); i < n; i++ {
batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr()
}
// 如果 cas 操作失败,说明本地队列不满了,直接返回
if !atomic.Cas(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return false
}
batch[n] = gp
// …………………………
// Link the goroutines.
// 全局运行队列是一个链表,这里首先把所有需要放入全局运行队列的 g 链接起来,
// 减小锁粒度,从而降低锁冲突,提升性能
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
// Now put the batch on global queue.
lock(&sched.lock)
globrunqputbatch(batch[0], batch[n], int32(n+1))
unlock(&sched.lock)
return true
}先将 P 本地队列里所有的 goroutine 加入到一个数组中,数组长度为 len(_p_.runq)/2 + 1,也就是 runq 的一半加上 newg。
接着,将从 runq 的头部开始的前一半 goroutine 存入 bacth 数组。然后,使用原子操作尝试修改 P 的队列头,因为出队了一半 goroutine,所以 head 要向后移动 1/2 的长度。如果修改失败,说明 runq 的本地队列被其他线程修改了,因此后面的操作就不进行了,直接返回 false,表示 newg 没被添加进来。
batch[n] = gp将 newg 本身添加到数组。
通过循环将 batch 数组里的所有 g 串成链表:
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
最后,将链表添加到全局队列中。由于操作的是全局队列,因此需要获取锁,因为存在竞争,所以代价较高。这也是本地可运行队列存在的原因。调用 globrunqputbatch(batch[0], batch[n], int32(n+1)):
// Put a batch of runnable goroutines on the global runnable queue.
// Sched must be locked.
func globrunqputbatch(ghead *g, gtail *g, n int32) {
gtail.schedlink = 0
if sched.runqtail != 0 {
sched.runqtail.ptr().schedlink.set(ghead)
} else {
sched.runqhead.set(ghead)
}
sched.runqtail.set(gtail)
sched.runqsize += n
}如果全局的队列尾 sched.runqtail 不为空,则直接将其和前面生成的链表头相接,否则说明全局的可运行列队为空,那就直接将前面生成的链表头设置到 sched.runqhead。
最后,再设置好队列尾,增加 runqsize。
设置完成之后:

再回到 runqput 函数,如果将 newg 添加到全局队列失败了,说明本地队列在此过程中发生了变化,又有了位置可以添加 newg,因此重试 retry 代码段。我们也可以发现,P 的本地可运行队列的长度为 256,它是一个循环队列,因此最多只能放下 256 个 goroutine。
因为本文还是处于初始化的场景,所以 newg 被成功放入 p0 的本地可运行队列,等待被调度。
将我们的图再完善一下:

8.10 schedule 循环如何启动
上一讲新创建了一个 goroutine,设置好了 sched 成员的 sp 和 pc 字段,并且将其添加到了 p0 的本地可运行队列,坐等调度器的调度。
我们继续看代码。搞了半天,我们其实还在 runtime·rt0_go 函数里,执行完 runtime·newproc(SB) 后,两条 POP 指令将之前为调用它构建的参数弹出栈。好消息是,最后就只剩下一个函数了:
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)这到达了本系列的核心区,前面铺垫了半天,调度器终于要开始运转了。
mstart 函数设置了 stackguard0 和 stackguard1 字段后,就直接调用 mstart1() 函数:
func mstart1() {
// 启动过程时 _g_ = m0.g0
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// Record top of stack for use by mcall.
// Once we call schedule we're never coming back,
// so other calls can reuse this stack space.
//
// 一旦调用 schedule() 函数,永不返回
// 所以栈帧可以被复用
gosave(&_g_.m.g0.sched)
_g_.m.g0.sched.pc = ^uintptr(0) // make sure it is never used
asminit()
minit()
// ……………………
// 执行启动函数。初始化过程中,fn == nil
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
if _g_.m.helpgc != 0 {
_g_.m.helpgc = 0
stopm()
} else if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
// 进入调度循环。永不返回
schedule()
}调用 gosave 函数来保存调度信息到 g0.sched 结构体,来看源码:
// void gosave(Gobuf*)
// save state in Gobuf; setjmp
TEXT runtime·gosave(SB), NOSPLIT, $0-8
// 将 gobuf 赋值给 AX
MOVQ buf+0(FP), AX // gobuf
// 取参数地址,也就是 caller 的 SP
LEAQ buf+0(FP), BX // caller's SP
// 保存 caller's SP,再次运行时的栈顶
MOVQ BX, gobuf_sp(AX)
MOVQ 0(SP), BX // caller's PC
// 保存 caller's PC,再次运行时的指令地址
MOVQ BX, gobuf_pc(AX)
MOVQ $0, gobuf_ret(AX)
MOVQ BP, gobuf_bp(AX)
// Assert ctxt is zero. See func save.
MOVQ gobuf_ctxt(AX), BX
TESTQ BX, BX
JZ 2(PC)
CALL runtime·badctxt(SB)
// 获取 tls
get_tls(CX)
// 将 g 的地址存入 BX
MOVQ g(CX), BX
// 保存 g 的地址
MOVQ BX, gobuf_g(AX)
RET主要是设置了 g0.sched.sp 和 g0.sched.pc,前者指向 mstart1 函数栈上参数的位置,后者则指向 gosave 函数返回后的下一条指令。如下图:
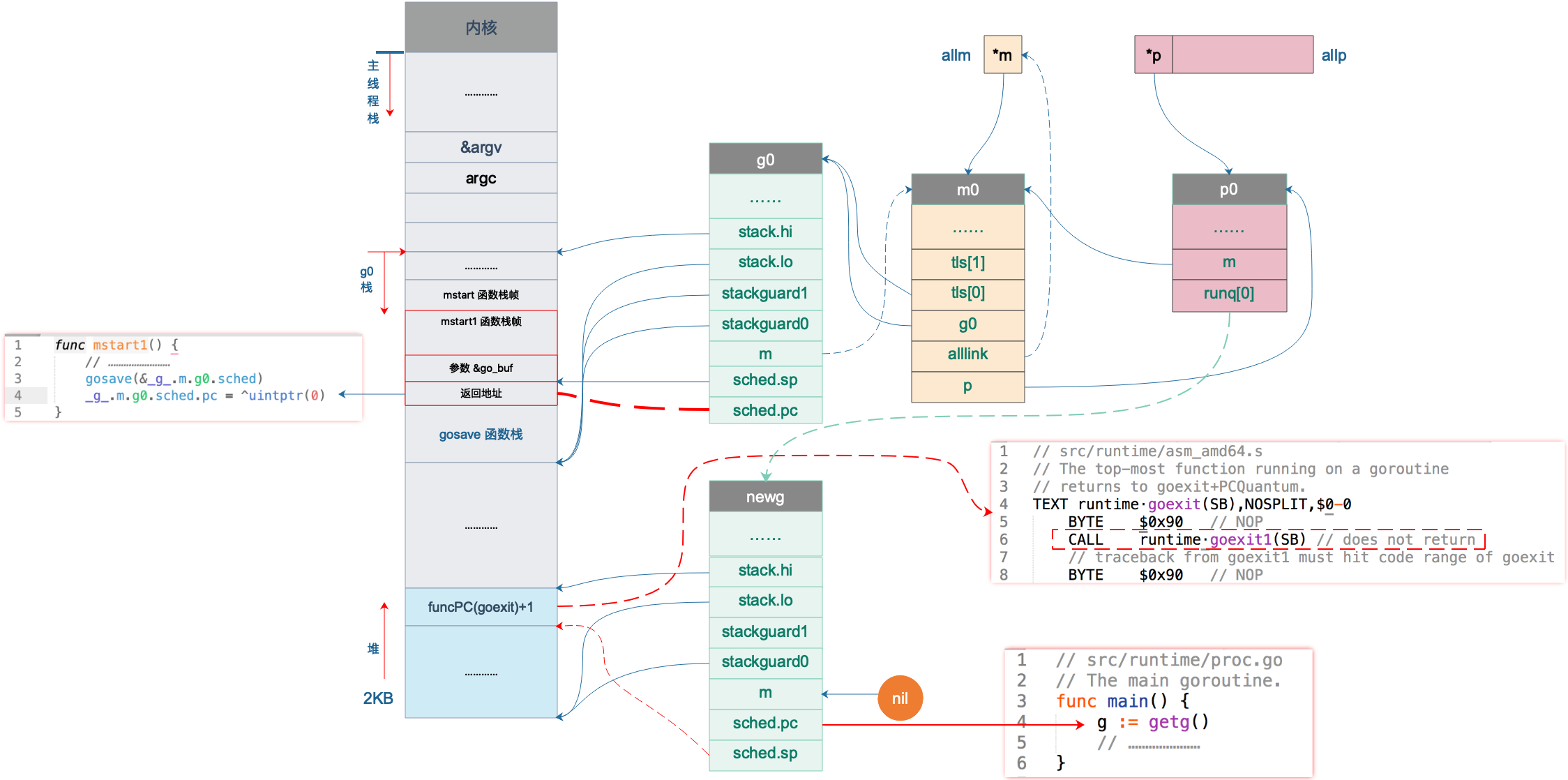
图中 sched.pc 并不直接指向返回地址,所以图中的虚线并没有箭头。
接下来,进入 schedule 函数,永不返回。
// 执行一轮调度器的工作:找到一个 runnable 的 goroutine,并且执行它
// 永不返回
func schedule() {
// _g_ = 每个工作线程 m 对应的 g0,初始化时是 m0 的 g0
_g_ := getg()
// ……………………
top:
// ……………………
var gp *g
var inheritTime bool
// ……………………
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
// 为了公平,每调用 schedule 函数 61 次就要从全局可运行 goroutine 队列中获取
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列最大获取 1 个 goroutine
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从 P 本地获取 G 任务
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
// 从本地运行队列和全局运行队列都没有找到需要运行的 goroutine,
// 调用 findrunnable 函数从其它工作线程的运行队列中偷取,如果偷不到,则当前工作线程进入睡眠
// 直到获取到 runnable goroutine 之后 findrunnable 函数才会返回。
gp, inheritTime = findrunnable() // blocks until work is available
}
// This thread is going to run a goroutine and is not spinning anymore,
// so if it was marked as spinning we need to reset it now and potentially
// start a new spinning M.
if _g_.m.spinning {
resetspinning()
}
if gp.lockedm != nil {
// Hands off own p to the locked m,
// then blocks waiting for a new p.
startlockedm(gp)
goto top
}
// 执行 goroutine 任务函数
// 当前运行的是 runtime 的代码,函数调用栈使用的是 g0 的栈空间
// 调用 execute 切换到 gp 的代码和栈空间去运行
execute(gp, inheritTime)
}调用 runqget,从 P 本地可运行队列先选出一个可运行的 goroutine;为了公平,调度器每调度 61 次的时候,都会尝试从全局队列里取出待运行的 goroutine 来运行,调用 globrunqget;如果还没找到,就要去其他 P 里面去偷一些 goroutine 来执行,调用 findrunnable 函数。
经过千辛万苦,终于找到了可以运行的 goroutine,调用 execute(gp, inheritTime) 切换到选出的 goroutine 栈执行,调度器的调度次数会在这里更新,源码如下:
// 调度 gp 在当前 M 上运行
// 如果 inheritTime 为真,gp 执行当前的时间片
// 否则,开启一个新的时间片
//
//go:yeswritebarrierrec
func execute(gp *g, inheritTime bool) {
// g0
_g_ := getg()
// 将 gp 的状态改为 running
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
// 调度器调度次数增加 1
_g_.m.p.ptr().schedtick++
}
// 将 gp 和 m 关联起来
_g_.m.curg = gp
gp.m = _g_.m
// …………………………
// gogo 完成从 g0 到 gp 真正的切换
// CPU 执行权的转让以及栈的切换
// 执行流的切换从本质上来说就是 CPU 寄存器以及函数调用栈的切换,
// 然而不管是 go 还是 c 这种高级语言都无法精确控制 CPU 寄存器的修改,
// 因而高级语言在这里也就无能为力了,只能依靠汇编指令来达成目的
gogo(&gp.sched)
}将 gp 的状态改为 _Grunning,将 m 和 gp 相互关联起来。最后,调用 gogo 完成从 g0 到 gp 的切换,CPU 的执行权将从 g0 转让到 gp。 gogo 函数用汇编语言写成,原因如下:
gogo函数也是通过汇编语言编写的,这里之所以需要使用汇编,是因为 goroutine 的调度涉及不同执行流之间的切换。
前面我们在讨论操作系统切换线程时已经看到过,执行流的切换从本质上来说就是 CPU 寄存器以及函数调用栈的切换,然而不管是 go 还是 c 这种高级语言都无法精确控制 CPU 寄存器,因而高级语言在这里也就无能为力了,只能依靠汇编指令来达成目的。
继续看 gogo 函数的实现,传入 &gp.sched 参数,源码如下:
TEXT runtime·gogo(SB), NOSPLIT, $16-8
// 0(FP) 表示第一个参数,即 buf = &gp.sched
MOVQ buf+0(FP), BX // gobuf
// ……………………
MOVQ buf+0(FP), BX
nilctxt:
// DX = gp.sched.g
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
get_tls(CX)
// 将 g 放入到 tls[0]
// 把要运行的 g 的指针放入线程本地存储,这样后面的代码就可以通过线程本地存储
// 获取到当前正在执行的 goroutine 的 g 结构体对象,从而找到与之关联的 m 和 p
// 运行这条指令之前,线程本地存储存放的是 g0 的地址
MOVQ DX, g(CX)
// 把 CPU 的 SP 寄存器设置为 sched.sp,完成了栈的切换
MOVQ gobuf_sp(BX), SP // restore SP
// 恢复调度上下文到CPU相关寄存器
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
// 清空 sched 的值,因为我们已把相关值放入 CPU 对应的寄存器了,不再需要,这样做可以少 GC 的工作量
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
// 把 sched.pc 值放入 BX 寄存器
MOVQ gobuf_pc(BX), BX
// JMP 把 BX 寄存器的包含的地址值放入 CPU 的 IP 寄存器,于是,CPU 跳转到该地址继续执行指令
JMP BX注释地比较详细了。核心的地方是:
MOVQ gobuf_g(BX), DX
// ……
get_tls(CX)
MOVQ DX, g(CX)第一行,将 gp.sched.g 保存到 DX 寄存器;第二行,我们见得已经比较多了,get_tls 将 tls 保存到 CX 寄存器,再将 gp.sched.g 放到 tls[0] 处。这样,当下次再调用 get_tls 时,取出的就是 gp,而不再是 g0,这一行完成从 g0 栈切换到 gp。
可能需要提一下的是,Go plan9 汇编中的一些奇怪的符号:
MOVQ buf+0(FP), BX # &gp.sched --> BXFP 是个伪奇存器,前面加 0 表示是第一个寄存器,表示参数的位置,最前面的 buf 表示一个符号。关于 Go 汇编语言的一些知识,可以参考曹大在夜读上的分享和《Go 语言高级编程》的相关章节,地址见参考资料。
接下来,将 gp.sched 的相关成员恢复到 CPU 对应的寄存器。最重要的是 sched.sp 和 sched.pc,前者被恢复到了 SP 寄存器,后者被保存到 BX 寄存器,最后一条跳转指令跳转到新的地址开始执行。通过之前的文章,我们知道,这里保存的就是 runtime.main 函数的地址。
最终,调度器完成了这个值得铭记的时刻,从 g0 转到 gp,开始执行 runtime.main 函数。
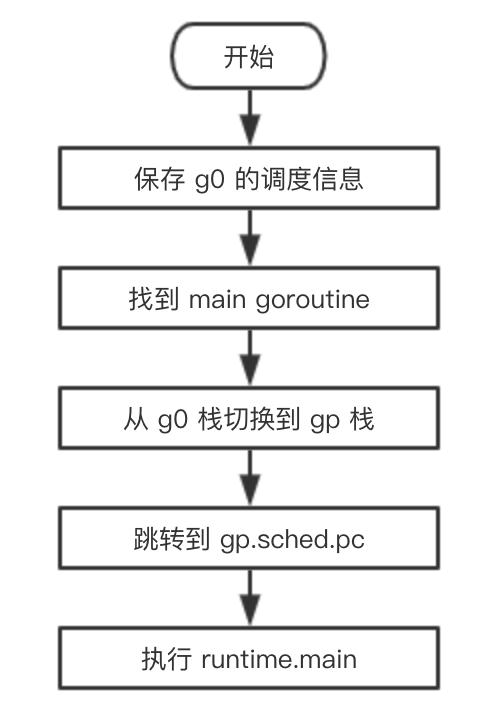
用一张流程图总结一下从 g0 切换到 main goroutine 的过程:
8.11 goroutine 如何退出
上一讲说到调度器将 main goroutine 推上舞台,为它铺好了道路,开始执行 runtime.main 函数。这一讲,我们探索 main goroutine 以及普通 goroutine 从执行到退出的整个过程。
// The main goroutine.
func main() {
// g = main goroutine,不再是 g0 了
g := getg()
// ……………………
if sys.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
// Allow newproc to start new Ms.
mainStarted = true
systemstack(func() {
// 创建监控线程,该线程独立于调度器,不需要跟 p 关联即可运行
newm(sysmon, nil)
})
lockOSThread()
if g.m != &m0 {
throw("runtime.main not on m0")
}
// 调用 runtime 包的初始化函数,由编译器实现
runtime_init() // must be before defer
if nanotime() == 0 {
throw("nanotime returning zero")
}
// Defer unlock so that runtime.Goexit during init does the unlock too.
needUnlock := true
defer func() {
if needUnlock {
unlockOSThread()
}
}()
// Record when the world started. Must be after runtime_init
// because nanotime on some platforms depends on startNano.
runtimeInitTime = nanotime()
// 开启垃圾回收器
gcenable()
main_init_done = make(chan bool)
// ……………………
// main 包的初始化,递归的调用我们 import 进来的包的初始化函数
fn := main_init
fn()
close(main_init_done)
needUnlock = false
unlockOSThread()
// ……………………
// 调用 main.main 函数
fn = main_main
fn()
if raceenabled {
racefini()
}
// ……………………
// 进入系统调用,退出进程,可以看出 main goroutine 并未返回,而是直接进入系统调用退出进程了
exit(0)
// 保护性代码,如果 exit 意外返回,下面的代码会让该进程 crash 死掉
for {
var x *int32
*x = 0
}
}main 函数执行流程如下图:
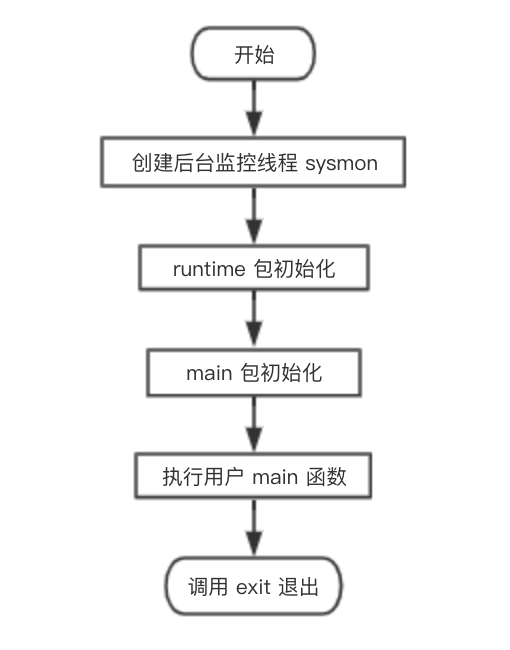
从流程图可知,main goroutine 执行完之后就直接调用 exit(0) 退出了,这会导致整个进程退出,太粗暴了。
不过,main goroutine 实际上就是代表用户的 main 函数,它都执行完了,肯定是用户的任务都执行完了,直接退出就可以了,就算有其他的 goroutine 没执行完,同样会直接退出。
package main
import "fmt"
func main() {
go func() {fmt.Println("hello qcrao.com")}()
}在这个例子中,main goroutine 退出时,还来不及执行 go 出去的函数,整个进程就直接退出了,打印语句不会执行。因此,main goroutine 不会等待其他 goroutine 执行完再退出,知道这个有时能解释一些现象,比如上面那个例子。
这时,心中可能会跳出疑问,我们在新创建 goroutine 的时候,不是整出了个“偷天换日”,风风火火地设置了 goroutine 退出时应该跳到 runtime.goexit 函数吗,怎么这会不用了,闲得慌?
回顾一下上一讲的内容,跳转到 main 函数的两行代码:
// 把 sched.pc 值放入 BX 寄存器
MOVQ gobuf_pc(BX), BX
// JMP 把 BX 寄存器的包含的地址值放入 CPU 的 IP 寄存器,于是,CPU 跳转到该地址继续执行指令
JMP BX直接使用了一个跳转,并没有使用 CALL 指令,而 runtime.main 函数中确实也没有 RET 返回的指令。所以,main goroutine 执行完后,直接调用 exit(0) 退出整个进程。
那之前整地“偷天换日”还有用吗?有的!这是针对非 main goroutine 起作用。
参考资料【阿波张 非 goroutine 的退出】中用调试工具验证了非 main goroutine 的退出,感兴趣的可以去跟着实践一遍。
我们继续探索非 main goroutine (后文我们就称 gp 好了)的退出流程。
gp 执行完后,RET 指令弹出 goexit 函数地址(实际上是 funcPC(goexit)+1),CPU 跳转到 goexit 的第二条指令继续执行:
// src/runtime/asm_amd64.s
// The top-most function running on a goroutine
// returns to goexit+PCQuantum.
TEXT runtime·goexit(SB),NOSPLIT,$0-0
BYTE $0x90 // NOP
CALL runtime·goexit1(SB) // does not return
// traceback from goexit1 must hit code range of goexit
BYTE $0x90 // NOP直接调用 runtime·goexit1:
// src/runtime/proc.go
// Finishes execution of the current goroutine.
func goexit1() {
// ……………………
mcall(goexit0)
}调用 mcall 函数:
// 切换到 g0 栈,执行 fn(g)
// Fn 不能返回
TEXT runtime·mcall(SB), NOSPLIT, $0-8
// 取出参数的值放入 DI 寄存器,它是 funcval 对象的指针,此场景中 fn.fn 是 goexit0 的地址
MOVQ fn+0(FP), DI
get_tls(CX)
// AX = g
MOVQ g(CX), AX // save state in g->sched
// mcall 返回地址放入 BX
MOVQ 0(SP), BX // caller's PC
// g.sched.pc = BX,保存 g 的 PC
MOVQ BX, (g_sched+gobuf_pc)(AX)
LEAQ fn+0(FP), BX // caller's SP
// 保存 g 的 SP
MOVQ BX, (g_sched+gobuf_sp)(AX)
MOVQ AX, (g_sched+gobuf_g)(AX)
MOVQ BP, (g_sched+gobuf_bp)(AX)
// switch to m->g0 & its stack, call fn
MOVQ g(CX), BX
MOVQ g_m(BX), BX
// SI = g0
MOVQ m_g0(BX), SI
CMPQ SI, AX // if g == m->g0 call badmcall
JNE 3(PC)
MOVQ $runtime·badmcall(SB), AX
JMP AX
// 把 g0 的地址设置到线程本地存储中
MOVQ SI, g(CX) // g = m->g0
// 从 g 的栈切换到了 g0 的栈D
MOVQ (g_sched+gobuf_sp)(SI), SP // sp = m->g0->sched.sp
// AX = g,参数入栈
PUSHQ AX
MOVQ DI, DX
// DI 是结构体 funcval 实例对象的指针,它的第一个成员才是 goexit0 的地址
// 读取第一个成员到 DI 寄存器
MOVQ 0(DI), DI
// 调用 goexit0(g)
CALL DI
POPQ AX
MOVQ $runtime·badmcall2(SB), AX
JMP AX
RET函数参数是:
type funcval struct {
fn uintptr
// variable-size, fn-specific data here
}字段 fn 就表示 goexit0 函数的地址。
L5 将函数参数保存到 DI 寄存器,这里 fn.fn 就是 goexit0 的地址。
L7 将 tls 保存到 CX 寄存器,L9 将 当前线程指向的 goroutine (非 main goroutine,称为 gp)保存到 AX 寄存器,L11 将调用者(调用 mcall 函数)的栈顶,这里就是 mcall 完成后的返回地址,存入 BX 寄存器。
L13 将 mcall 的返回地址保存到 gp 的 g.sched.pc 字段,L14 将 gp 的栈顶,也就是 SP 保存到 BX 寄存器,L16 将 SP 保存到 gp 的 g.sched.sp字段,L17 将 g 保存到 gp 的 g.sched.g 字段,L18 将 BP 保存到 gp 的 g.sched.bp 字段。这一段主要是保存 gp 的调度信息。
L21 将当前指向的 g 保存到 BX 寄存器,L22 将 g.m 字段保存到 BX 寄存器,L23 将 g.m.g0 字段保存到 SI,g.m.g0 就是当前工作线程的 g0。
现在,SI = g0, AX = gp,L25 判断 gp 是否是 g0,如果 gp == g0 说明有问题,执行 runtime·badmcall。正常情况下,PC 值加 3,跳过下面的两条指令,直接到达 L30。
L30 将 g0 的地址设置到线程本地存储中,L32 将 g0.SP 设置到 CPU 的 SP 寄存器,这也就意味着我们从 gp 栈切换到了 g0 的栈,要变天了!
L34 将参数 gp 入栈,为调用 goexit0 构造参数。L35 将 DI 寄存器的内容设置到 DX 寄存器,DI 是结构体 funcval 实例对象的指针,它的第一个成员才是 goexit0 的地址。L36 读取 DI 第一成员,也就是 goexit0 函数的地址。
L40 调用 goexit0 函数,这已经是在 g0 栈上执行了,函数参数就是 gp。
到这里,就会去执行 goexit0 函数,注意,这里永远都不会返回。所以,在 CALL 指令后面,如果返回了,又会去调用 runtime.badmcall2 函数去处理意外情况。
来继续看 goexit0:
// goexit continuation on g0.
// 在 g0 上执行
func goexit0(gp *g) {
// g0
_g_ := getg()
casgstatus(gp, _Grunning, _Gdead)
if isSystemGoroutine(gp) {
atomic.Xadd(&sched.ngsys, -1)
}
// 清空 gp 的一些字段
gp.m = nil
gp.lockedm = nil
_g_.m.lockedg = nil
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = ""
gp.param = nil
gp.labels = nil
gp.timer = nil
// Note that gp's stack scan is now "valid" because it has no
// stack.
gp.gcscanvalid = true
// 解除 g 与 m 的关系
dropg()
if _g_.m.locked&^_LockExternal != 0 {
print("invalid m->locked = ", _g_.m.locked, "\n")
throw("internal lockOSThread error")
}
_g_.m.locked = 0
// 将 g 放入 free 队列缓存起来
gfput(_g_.m.p.ptr(), gp)
schedule()
}它主要完成最后的清理工作:
- 把 g 的状态从
_Grunning更新为_Gdead;- 清空 g 的一些字段;
- 调用 dropg 函数解除 g 和 m 之间的关系,其实就是设置 g->m = nil, m->currg = nil;
- 把 g 放入 p 的 freeg 队列缓存起来供下次创建 g 时快速获取而不用从内存分配。freeg 就是 g 的一个对象池;
- 调用 schedule 函数再次进行调度。
到这里,gp 就完成了它的历史使命,功成身退,进入了 goroutine 缓存池,待下次有任务再重新启用。
而工作线程,又继续调用 schedule 函数进行新一轮的调度,整个过程形成了一个循环。
总结一下,main goroutine 和普通 goroutine 的退出过程:
对于 main goroutine,在执行完用户定义的 main 函数的所有代码后,直接调用 exit(0) 退出整个进程,非常霸道。
对于普通 goroutine 则没这么“舒服”,需要经历一系列的过程。先是跳转到提前设置好的 goexit 函数的第二条指令,然后调用 runtime.goexit1,接着调用 mcall(goexit0),而 mcall 函数会切换到 g0 栈,运行 goexit0函数,清理 goroutine 的一些字段,并将其添加到 goroutine 缓存池里,然后进入 schedule 调度循环。到这里,普通 goroutine 才算完成使命。
8.12 schedule 循环如何运转
上一节,我们讲完 main goroutine 以及普通 goroutine 的退出过程。main goroutine 退出后直接调用 exit(0) 使得整个进程退出,而普通 goroutine 退出后,则进行了一系列的调用,最终又切到 g0 栈,执行 schedule 函数。
从前面的文章我们知道,普通 goroutine(gp)就是在 schedule 函数中被选中,然后才有机会执行。而现在,gp 执行完之后,再次进入 schedule 函数,形成一个循环。这个循环太长了,我们有必要再重新梳理一下。
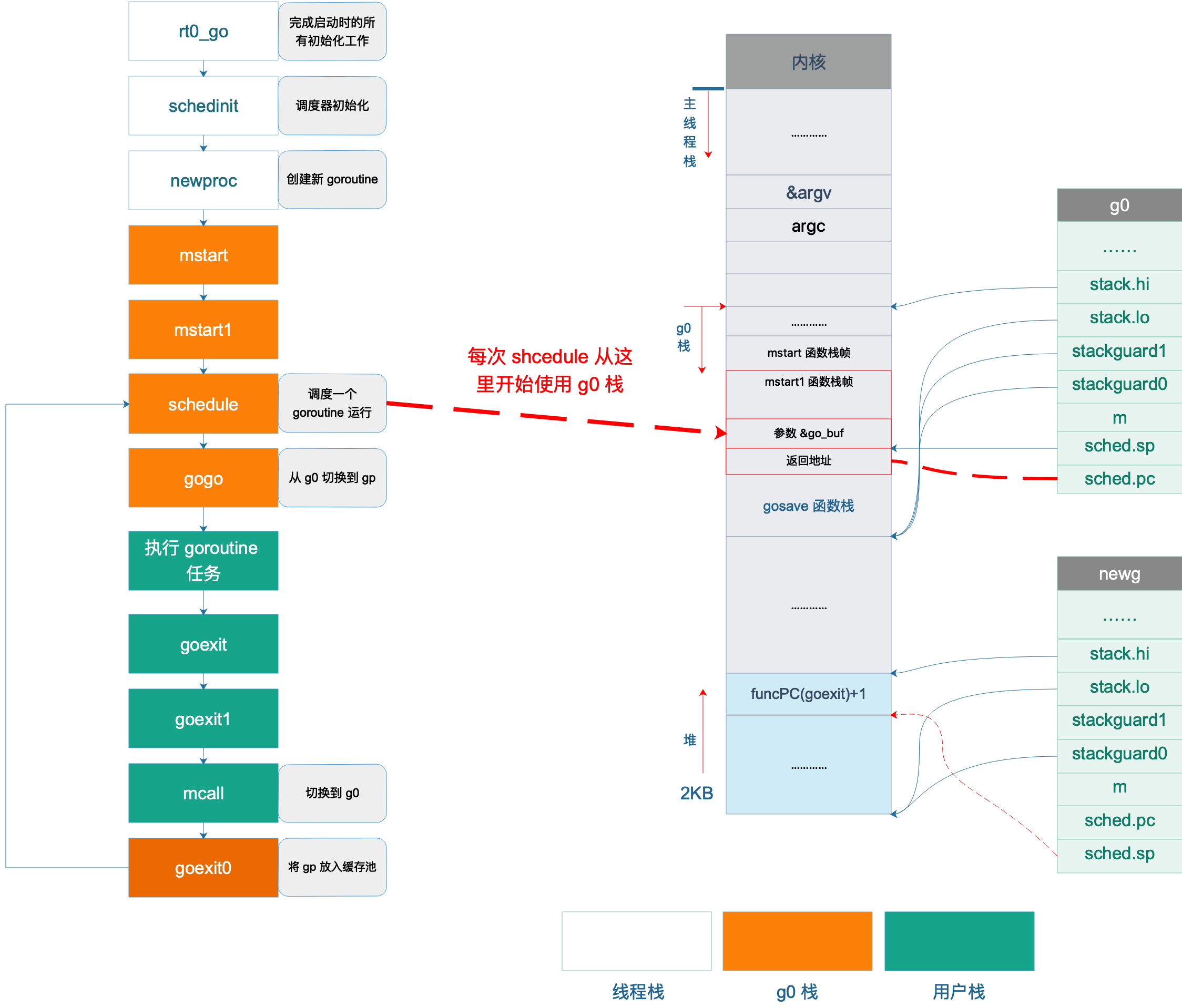
如图所示,rt0_go 负责 Go 程序启动的所有初始化,中间进行了很多初始化工作,调用 mstart 之前,已经切换到了 g0 栈,图中不同色块表示使用不同的栈空间。
接着调用 gogo 函数,完成从 g0 栈到用户 goroutine 栈的切换,包括 main goroutine 和普通 goroutine。
之后,执行 main 函数或者用户自定义的 goroutine 任务。
执行完成后,main goroutine 直接调用 eixt(0) 退出,普通 goroutine 则调用 goexit -> goexit1 -> mcall,完成普通 goroutine 退出后的清理工作,然后切换到 g0 栈,调用 goexit0 函数,将普通 goroutine 添加到缓存池中,再调用 schedule 函数进行新一轮的调度。
schedule() -> execute() -> gogo() -> goroutine 任务 -> goexit() -> goexit1() -> mcall() -> goexit0() -> schedule()可以看出,一轮调度从调用 schedule 函数开始,经过一系列过程再次调用 schedule 函数来进行新一轮的调度,从一轮调度到新一轮调度的过程称之为一个调度循环。
这里说的调度循环是指某一个工作线程的调度循环,而同一个Go 程序中存在多个工作线程,每个工作线程都在进行着自己的调度循环。
从前面的代码分析可以得知,上面调度循环中的每一个函数调用都没有返回,虽然
goroutine 任务-> goexit() -> goexit1() -> mcall()是在 g2 的栈空间执行的,但剩下的函数都是在 g0 的栈空间执行的。
那么问题就来了,在一个复杂的程序中,调度可能会进行无数次循环,也就是说会进行无数次没有返回的函数调用,大家都知道,每调用一次函数都会消耗一定的栈空间,而如果一直这样无返回的调用下去无论 g0 有多少栈空间终究是会耗尽的,那么这里是不是有问题?其实没有问题!关键点就在于,每次执行 mcall 切换到 g0 栈时都是切换到 g0.sched.sp 所指的固定位置,这之所以行得通,正是因为从 schedule 函数开始之后的一系列函数永远都不会返回,所以重用这些函数上一轮调度时所使用过的栈内存是没有问题的。
我再解释一下:栈空间在调用函数时会自动“增大”,而函数返回时,会自动“减小”,这里的增大和减小是指栈顶指针 SP 的变化。上述这些函数都没有返回,说明调用者不需要用到被调用者的返回值,有点像“尾递归”。
因为 g0 一直没有动过,所有它之前保存的 sp 还能继续使用。每一次调度循环都会覆盖上一次调度循环的栈数据,完美!
8.13 M 如何找工作
在 schedule 函数中,我们简单提过找一个 runnable goroutine 的过程,这一讲我们来详细分析源码。
工作线程 M 费尽心机也要找到一个可运行的 goroutine,这是它的工作和职责,不达目的,绝不罢体,这种锲而不舍的精神值得每个人学习。
共经历三个过程:先从本地队列找,定期会从全局队列找,最后实在没办法,就去别的 P 偷。如下图所示:
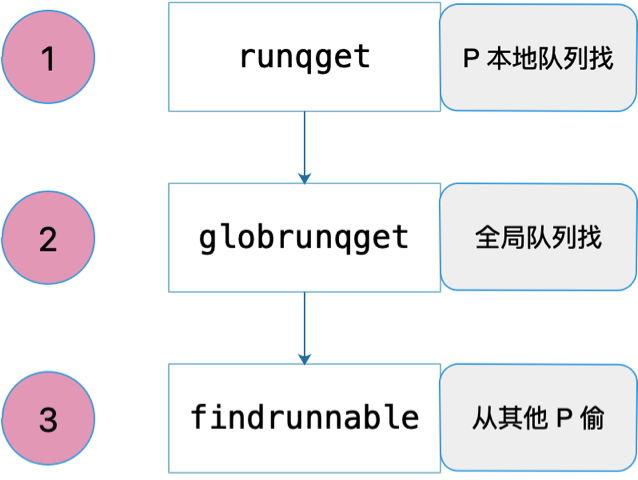
先看第一个:从 P 本地队列找。源码如下:
// 从本地可运行队列里找到一个 g
// 如果 inheritTime 为真,gp 应该继承这个时间片,否则,新开启一个时间片
func runqget(_p_ *p) (gp *g, inheritTime bool) {
// If there's a runnext, it's the next G to run.
// 如果 runnext 不为空,则 runnext 是下一个待运行的 G
for {
next := _p_.runnext
if next == 0 {
// 为空,则直接跳出循环
break
}
// 再次比较 next 是否没有变化
if _p_.runnext.cas(next, 0) {
// 如果没有变化,则返回 next 所指向的 g。且需要继承时间片
return next.ptr(), true
}
}
for {
// 获取队列头
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with other consumers
// 获取队列尾
t := _p_.runqtail
if t == h {
// 头和尾相等,说明本地队列为空,找不到 g
return nil, false
}
// 获取队列头的 g
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
// 原子操作,防止这中间被其他线程因为偷工作而修改
if atomic.Cas(&_p_.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}整个源码结构比较简单,主要是两个 for 循环。
第一个 for 循环尝试返回 P 的 runnext 成员,因为 runnext 具有最高的运行优先级,因此要首先尝试获取 runnext。当发现 runnext 为空时,直接跳出循环,进入第二个。否则,用原子操作获取 runnext,并将其值修改为 0,也就是空。这里用到原子操作的原因是防止在这个过程中,有其他线程过来“偷工作”,导致并发修改 runnext 成员。
第二个 for 循环则是在尝试获取 runnext 成员失败后,尝试从本地队列中返回队列头的 goroutine。同样,先用原子操作获取队列头,使用原子操作的原因同样是防止其他线程“偷工作”时并发对队列头的并发写操作。之后,直接获取队列尾,因为不担心其他线程同时更改,所以直接获取。注意,“偷工作”时只会修改队列头。
比较队列头和队列尾,如果两者相等,说明 P 本地队列没有可运行的 goroutine,直接返回空。否则,算出队列头指向的 goroutine,再用一个 CAS 原子操作来尝试修改队列头,使用原子操作的原因同上。
从本地队列获取可运行 goroutine 的过程比较简单,我们再来看从全局队列获取 goroutine 的过程。在 schedule 函数中调用 globrunqget 的代码:
// 为了公平,每调用 schedule 函数 61 次就要从全局可运行 goroutine 队列中获取
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列最大获取 1 个 goroutine
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}这说明,并不是每次调度都会从全局队列获取可运行的 goroutine。实际情況是调度器每调度 61 次并且全局队列有可运行 goroutine 的情况下才会调用 globrunqget 函数尝试从全局获取可运行 goroutine。毕竟,从全局获取需要上锁,这个开销可就大了,能不做就不做。
我们来详细看下 globrunqget 的源码:
// 尝试从全局队列里获取可运行的 goroutine 队列
func globrunqget(_p_ *p, max int32) *g {
// 如果队列大小为 0
if sched.runqsize == 0 {
return nil
}
// 根据 p 的数量平分全局运行队列中的 goroutines
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize // 如果 gomaxprocs 为 1
}
// 修正"偷"的数量
if max > 0 && n > max {
n = max
}
// 最多只能"偷"本地工作队列一半的数量
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2
}
// 更新全局可运行队列长度
sched.runqsize -= n
// 如果都要被"偷"走,修改队列尾
if sched.runqsize == 0 {
sched.runqtail = 0
}
// 获取队列头指向的 goroutine
gp := sched.runqhead.ptr()
// 移动队列头
sched.runqhead = gp.schedlink
n--
for ; n > 0; n-- {
// 获取当前队列头
gp1 := sched.runqhead.ptr()
// 移动队列头
sched.runqhead = gp1.schedlink
// 尝试将 gp1 放入 P 本地,使全局队列得到更多的执行机会
runqput(_p_, gp1, false)
}
// 返回最开始获取到的队列头所指向的 goroutine
return gp
}代码比较简单。首先根据全局队列的可运行 goroutine 长度和 P 的总数,来计算一个数值,表示每个 P 可平均分到的 goroutine 数量。
然后根据函数参数中的 max 以及 P 本地队列的长度来决定把多少全局队列中的 goroutine 转移到 P 本地。
最后,for 循环挨个把全局队列中 n-1 个 goroutine 转移到本地,并且返回最开始获取到的队列头所指向的 goroutine,毕竟它最需要得到运行的机会。
把全局队列中的可运行 goroutine 转移到本地队列,给了全局队列中可运行 goroutine 运行的机会,不然全局队列中的 goroutine 一直得不到运行。
最后,我们继续看第三个过程,从其他 P “偷工作”:
// 从本地运行队列和全局运行队列都没有找到需要运行的 goroutine,
// 调用 findrunnable 函数从其它工作线程的运行队列中偷取,如果偷不到,则当前工作线程进入睡眠
// 直到获取到 runnable goroutine 之后 findrunnable 函数才会返回。
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}这是整个找工作过程最复杂的部分:
// 从其他地方找 goroutine 来执行
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
// ……………………
// local runq
// 从本地队列获取
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// global runq
// 从全局队列获取
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// ……………………
// Steal work from other P's.
// 如果其他的 P 都处于空闲状态,那肯定没有其他工作要做
procs := uint32(gomaxprocs)
if atomic.Load(&sched.npidle) == procs-1 {
goto stop
}
// 如果有很多工作线程在找工作,那我就停下休息。避免消耗太多 CPU
if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {
goto stop
}
if !_g_.m.spinning {
// 设置自旋状态为 true
_g_.m.spinning = true
// 自旋状态数加 1
atomic.Xadd(&sched.nmspinning, 1)
}
// 从其它 p 的本地运行队列盗取 goroutine
for i := 0; i < 4; i++ {
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
// ……………………
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil {
return gp, false
}
}
}
stop:
// ……………………
// return P and block
lock(&sched.lock)
if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
// 当前工作线程解除与 p 之间的绑定,准备去休眠
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
// 把 p 放入空闲队列
pidleput(_p_)
unlock(&sched.lock)
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
// m 即将睡眠,不再处于自旋
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
}
// check all runqueues once again
// 休眠之前再检查一下所有的 p,看一下是否有工作要做
for i := 0; i < int(gomaxprocs); i++ {
_p_ := allp[i]
if _p_ != nil && !runqempty(_p_) {
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
break
}
}
// ……………………
// 休眠
stopm()
goto top
}这部分也是最能说明 M 找工作的锲而不舍精神:尽力去各个运行队列中寻找 goroutine,如果实在找不到则进入睡眠状态,等待有工作时,被其他 M 唤醒。
先获取当前指向的 g,也就是 g0,然后拿到其绑定的 p,即 _p_。
首先再次尝试从 _p_ 本地队列获取 goroutine,如果没有获取到,则尝试从全局队列获取。如果还没有获取到就会尝试去“偷”了,这也是没有办法的事。
不过,在偷之前,先看大的局势。如果其他所有的 P 都处于空闲状态,就说明其他 P 肯定没有工作可做,就没必要再去偷了,毕竟“地主家也没有余粮了”,跳到 stop 部分。接着再看下当前正在“偷工作”的线程数量“太多了”,就没必要扎堆了,这么多人,竞争肯定大,工作肯定不好找,也不好偷。
在真正的“偷”工作之前,把自己的自旋状态设置为 true,全局自旋数量加 1。
终于到了“偷工作”的部分了,好紧张!整个过程由两层 for 循环组成,外层控制尝试偷的次数,内层控制“偷”的顺序,并真正的去“偷”。实际上,内层会遍历所有的 P,因此,整体看来,会尝试 4 次扫遍所有的 P,并去“偷工作”,是不是非常有毅力!
第二层的循环并不是每次都按一个固定的顺序去遍历所有的 P,这样不太科学,而是使用了一些方法,“随机”地遍历。具体是使用了下面这个变量:
var stealOrder randomOrder
type randomOrder struct {
count uint32
coprimes []uint32
}初始化的时候会给 count 赋一个值,例如 8,根据 count 计算出 coprimes,里面的元素是小于 count 的值,且和 8 互质,算出来是:[1, 3, 5, 7]。
第二层循环,开始随机给一个值,例如 2,则第一个访问的 P 就是 P2;从 coprimes 里取出索引为 2 的值为 5,那么,第二个访问的 P 索引就是 2+5=7;依此类推,第三个就是 7+5=12,和 count 做一个取余操作,即 12%8=4……
在最后一次遍历所有的 P 的过程中,连人家的 runnext 也要尝试偷过来,毕竟前三次的失败经验证明,工作太不好“偷”了,民不聊生啊,只能做得绝一点了,stealRunNextG 控制是否要打 runnext 的主意:
stealRunNextG := i > 2确定好准备偷的对象 allp[enum.position() 之后,调用 runqsteal(_p_, allp[enum.position()], stealRunNextG) 函数执行。
// 从 p2 偷走一半的工作放到 _p_ 的本地
func runqsteal(_p_, p2 *p, stealRunNextG bool) *g {
// 队尾
t := _p_.runqtail
// 从 p2 偷取工作,放到 _p_.runq 的队尾
n := runqgrab(p2, &_p_.runq, t, stealRunNextG)
if n == 0 {
return nil
}
n--
// 找到最后一个 g,准备返回
gp := _p_.runq[(t+n)%uint32(len(_p_.runq))].ptr()
if n == 0 {
// 说明只偷了一个 g
return gp
}
// 队列头
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with consumers
// 判断是否偷太多了
if t-h+n >= uint32(len(_p_.runq)) {
throw("runqsteal: runq overflow")
}
// 更新队尾,将偷来的工作加入队列
atomic.Store(&_p_.runqtail, t+n) // store-release, makes the item available for consumption
return gp
}调用 runqgrab 从 p2 偷走它一半的工作放到 _p_ 本地:
n := runqgrab(p2, &_p_.runq, t, stealRunNextG)runqgrab 函数将从 p2 偷来的工作放到以 t 为地址的数组里,数组就是 _p_.runq。 我们知道,t 是 _p_.runq 的队尾,因此这行代码表达的真正意思是将从 p2 偷来的工作,神不知,鬼不觉地放到 _p_.runq 的队尾,之后,再悄悄改一下 ``p.runqtail` 就把这些偷来的工作据为己有了。
接着往下看,返回的 n 表示偷到的工作数量。先将 n 自减 1,目的是把第 n 个工作(也就是 g)直接返回,如果这时候 n 变成 0 了,说明就只偷到了一个 g,那就直接返回。否则,将队尾往后移动 n,把偷来的工作合法化,简直完美!
我们接着往下看 runqgrab 函数的实现:
// 从 _p_ 批量获取可运行 goroutine,放到 batch 数组里
// batch 是一个环,起始于 batchHead
// 返回偷的数量,返回的 goroutine 可被任何 P 执行
func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
// 队列头
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with other consumers
// 队列尾
t := atomic.Load(&_p_.runqtail) // load-acquire, synchronize with the producer
// g 的数量
n := t - h
// 取一半
n = n - n/2
if n == 0 {
if stealRunNextG {
// 连 runnext 都要偷,没有人性
// Try to steal from _p_.runnext.
if next := _p_.runnext; next != 0 {
// 这里是为了防止 _p_ 执行当前 g,并且马上就要阻塞,所以会马上执行 runnext,
// 这个时候偷就没必要了,因为让 g 在 P 之间"游走"不太划算,
// 就不偷了,给他们一个机会。
// channel 一次同步的的接收发送需要 50ns 左右,因此 3us 差不多给了他们 50 次机会了,做得还是不错的
if GOOS != "windows" {
usleep(3)
} else {
osyield()
}
if !_p_.runnext.cas(next, 0) {
continue
}
// 真的偷走了 next
batch[batchHead%uint32(len(batch))] = next
// 返回偷的数量,只有 1 个
return 1
}
}
// 没偷到
return 0
}
// 如果 n 这时变得太大了,重新来一遍了,不能偷的太多,做得太过分了
if n > uint32(len(_p_.runq)/2) { // read inconsistent h and t
continue
}
// 将 g 放置到 bacth 中
for i := uint32(0); i < n; i++ {
g := _p_.runq[(h+i)%uint32(len(_p_.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
// 工作被偷走了,更新一下队列头指针
if atomic.Cas(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}
}外层直接就是一个无限循环,先用原子操作取出 p 的队列头和队列尾,算出一半的 g 的数量,如果 n == 0,说明地主家也没有余粮,这时看 stealRunNextG 的值。如果为假,说明不偷 runnext,那就直接返回 0,啥也没偷到;如果为真,则要尝试偷一下 runnext。
先判断 runnext 不为空,那就真的准备偷了。不过在这之前,要先休眠 3 us。这是为了防止 p 正在执行当前的 g,马上就要阻塞(可能是向一个非缓冲的 channel 发送数据,没有接收者),之后会马上执行 runnext。这个时候偷就没必要了,因为 runnext 马上就要执行了,偷走它还不是要去执行,那何必要偷呢?大家的愿望就是提高效率,这样让 g 在 P 之间”游走”不太划算,索性先不偷了,给他们一个机会。channel 一次同步的的接收或发送需要 50ns 左右,因此休眠 3us 差不多给了他们 50 次机会了,做得还是挺厚道的。
继续看,再次判断 n 是否小于等于 p.runq 长度的一半,因为这个时候很可能 p 也被其他线程偷了,它的 p.runq 就没那么多工作了,这个时候就不能偷这么多了,要重新再走一次循环。
最后一个 for 循环,将 p.runq 里的 g 放到 batch 数组里。使用原子操作更新 p 的队列头指针,往后移动 n 个位置,这些都是被偷走的,伤心!
回到 findrunnable 函数,经过上述三个层面的“偷窃”过程,我们仍然没有找到工作,真惨!于是就走到了 stop 这个代码块。
先上锁,因为要将 P 放到全局空闲 P 链表里去。在这之前还不死心,再瞧一下全局队列里是否有工作,如果有,再去尝试偷全局。
如果没有,就先解除当前工作线程和当前 P 的绑定关系:
// 解除 p 与 m 的关联
func releasep() *p {
_g_ := getg()
// ……………………
_p_ := _g_.m.p.ptr()
// ……………………
// 清空一些字段
_g_.m.p = 0
_g_.m.mcache = nil
_p_.m = 0
_p_.status = _Pidle
return _p_
}主要的工作就是将 p 的 m 字段清空,并将 p 的状态修改为 _Pidle。
这之后,将其放入全局空闲 P 列表:
// 将 p 放到 _Pidle 列表里
//go:nowritebarrierrec
func pidleput(_p_ *p) {
if !runqempty(_p_) {
throw("pidleput: P has non-empty run queue")
}
_p_.link = sched.pidle
sched.pidle.set(_p_)
// 增加全局空闲 P 的数量
atomic.Xadd(&sched.npidle, 1) // TODO: fast atomic
}构造链表的过程其实比较简单,先将 p.link 指向原来的 sched.pidle 所指向的 p,也就是原空闲链表的最后一个 P,最后,再更新 sched.pidle,使其指向当前 p,这样,新的链表就构造完成。
接下来就要真正地准备休眠了,但是仍然不死心!还要再查看一次所有的 P 是否有工作,如果发现任何一个 P 有工作的话(判断 P 的本地队列不空),就先从全局空闲 P 链表里先拿到一个 P:
// 试图从 _Pidle 列表里获取 p
//go:nowritebarrierrec
func pidleget() *p {
_p_ := sched.pidle.ptr()
if _p_ != nil {
sched.pidle = _p_.link
atomic.Xadd(&sched.npidle, -1) // TODO: fast atomic
}
return _p_
}比较简单,获取链表最后一个,再更新 sched.pidle,使其指向前一个 P。调用 acquirep(_p_) 绑定获取到的 p 和 m,主要的动作就是设置 p 的 m 字段,更改 p 的工作状态为 _Prunning,并且设置 m 的 p 字段。做完这些之后,再次进入 top 代码段,再走一遍之前找工作的过程。
// 休眠,停止执行工作,直到有新的工作需要做为止
func stopm() {
// 当前 goroutine,g0
_g_ := getg()
// ……………………
retry:
lock(&sched.lock)
// 将 m 放到全局空闲链表里去
mput(_g_.m)
unlock(&sched.lock)
// 进入睡眠状态
notesleep(&_g_.m.park)
// 这里被其他工作线程唤醒
noteclear(&_g_.m.park)
// ……………………
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}先将 m 放入全局空闲链表里,注意涉及到全局变量的修改,要上锁。接着,调用 notesleep(&_g_.m.park) 使得当前工作线程进入休眠状态。其他工作线程在检测到“当前有很多工作要做”,会调用 noteclear(&_g_.m.park) 将其唤醒。注意,这两个函数传入的参数都是一样的:&_g_.m.park,它的类型是:
type note struct {
key uintptr
}很简单,只有一个 key 字段。
note 的底层实现机制跟操作系统相关,不同系统使用不同的机制,比如 linux 下使用的 futex 系统调用,而 mac 下则是使用的 pthread_cond_t 条件变量,note 对这些底层机制做了一个抽象和封装。
这种封装给扩展性带来了很大的好处,比如当睡眠和唤醒功能需要支持新平台时,只需要在 note 层增加对特定平台的支持即可,不需要修改上层的任何代码。
上面这一段来自阿波张的系列教程。我们接着来看下 notesleep 的实现:
// runtime/lock_futex.go
func notesleep(n *note) {
// g0
gp := getg()
if gp != gp.m.g0 {
throw("notesleep not on g0")
}
// -1 表示无限期休眠
ns := int64(-1)
// ……………………
// 这里之所以需要用一个循环,是因为 futexsleep 有可能意外从睡眠中返回,
// 所以 futexsleep 函数返回后还需要检查 note.key 是否还是 0,
// 如果是 0 则表示并不是其它工作线程唤醒了我们,
// 只是 futexsleep 意外返回了,需要再次调用 futexsleep 进入睡眠
for atomic.Load(key32(&n.key)) == 0 {
// 表示 m 被阻塞
gp.m.blocked = true
futexsleep(key32(&n.key), 0, ns)
// ……………………
// 被唤醒,更新标志
gp.m.blocked = false
}
}继续往下追:
// runtime/os_linux.go
func futexsleep(addr *uint32, val uint32, ns int64) {
var ts timespec
if ns < 0 {
futex(unsafe.Pointer(addr), _FUTEX_WAIT, val, nil, nil, 0)
return
}
// ……………………
}当 *addr 和 val 相等的时候,休眠。futex 由汇编语言实现:
TEXT runtime·futex(SB),NOSPLIT,$0
// 为系统调用准备参数
MOVQ addr+0(FP), DI
MOVL op+8(FP), SI
MOVL val+12(FP), DX
MOVQ ts+16(FP), R10
MOVQ addr2+24(FP), R8
MOVL val3+32(FP), R9
// 系统调用编号
MOVL $202, AX
// 执行 futex 系统调用进入休眠,被唤醒后接着执行下一条 MOVL 指令
SYSCALL
// 保存系统调用的返回值
MOVL AX, ret+40(FP)
RET这样,找不到工作的 m 就休眠了。当其他线程发现有工作要做时,就会先找到空闲的 m,再通过 m.park 字段来唤醒本线程。唤醒之后,回到 findrunnable 函数,继续寻找 goroutine,找到后返回 schedule 函数,然后就会去运行找到的 goroutine。
这就是 m 找工作的整个过程,历尽千辛万苦,终于修成正果。
8.14 sysmon 后台监控线程做了什么
在 runtime.main() 函数中,执行 runtime_init() 前,会启动一个 sysmon 的监控线程,执行后台监控任务:
systemstack(func() {
// 创建监控线程,该线程独立于调度器,不需要跟 p 关联即可运行
newm(sysmon, nil)
})sysmon 函数不依赖 P 直接执行,通过 newm 函数创建一个工作线程:
func newm(fn func(), _p_ *p) {
// 创建 m 对象
mp := allocm(_p_, fn)
// 暂存 m
mp.nextp.set(_p_)
mp.sigmask = initSigmask
// ……………………
execLock.rlock() // Prevent process clone.
// 创建系统线程
newosproc(mp, unsafe.Pointer(mp.g0.stack.hi))
execLock.runlock()
}先调用 allocm 在堆上创建一个 m,接着调用 newosproc 函数启动一个工作线程:
// src/runtime/os_linux.go
//go:nowritebarrier
func newosproc(mp *m, stk unsafe.Pointer) {
// ……………………
ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart)))
// ……………………
}核心就是调用 clone 函数创建系统线程,新线程从 mstart 函数开始执行。clone 函数由汇编语言实现:
// int32 clone(int32 flags, void *stk, M *mp, G *gp, void (*fn)(void));
TEXT runtime·clone(SB),NOSPLIT,$0
// 准备系统调用的参数
MOVL flags+0(FP), DI
MOVQ stk+8(FP), SI
MOVQ $0, DX
MOVQ $0, R10
// 将 mp,gp,fn 拷贝到寄存器,对子线程可见
MOVQ mp+16(FP), R8
MOVQ gp+24(FP), R9
MOVQ fn+32(FP), R12
// 系统调用 clone
MOVL $56, AX
SYSCALL
// In parent, return.
CMPQ AX, $0
JEQ 3(PC)
// 父线程,返回
MOVL AX, ret+40(FP)
RET
// In child, on new stack.
// 在子线程中。设置 CPU 栈顶寄存器指向子线程的栈顶
MOVQ SI, SP
// If g or m are nil, skip Go-related setup.
CMPQ R8, $0 // m
JEQ nog
CMPQ R9, $0 // g
JEQ nog
// Initialize m->procid to Linux tid
// 通过 gettid 系统调用获取线程 ID(tid)
MOVL $186, AX // gettid
SYSCALL
// 设置 m.procid = tid
MOVQ AX, m_procid(R8)
// Set FS to point at m->tls.
// 新线程刚刚创建出来,还未设置线程本地存储,即 m 结构体对象还未与工作线程关联起来,
// 下面的指令负责设置新线程的 TLS,把 m 对象和工作线程关联起来
LEAQ m_tls(R8), DI
CALL runtime·settls(SB)
// In child, set up new stack
get_tls(CX)
MOVQ R8, g_m(R9) // g.m = m
MOVQ R9, g(CX) // tls.g = &m.g0
CALL runtime·stackcheck(SB)
nog:
// Call fn
// 调用 mstart 函数。永不返回
CALL R12
// It shouldn't return. If it does, exit that thread.
MOVL $111, DI
MOVL $60, AX
SYSCALL
JMP -3(PC) // keep exiting先是为 clone 系统调用准备参数,参数通过寄存器传递。第一个参数指定内核创建线程时的选项,第二个参数指定新线程应该使用的栈,这两个参数都是通过 newosproc 函数传递进来的。
接着将 m, g0, fn 分别保存到寄存器中,待子线程创建好后再拿出来使用。因为这些参数此时是在父线程的栈上,若不保存到寄存器中,子线程就取不出来了。
这个几个参数保存在父线程的寄存器中,创建子线程时,操作系统内核会把父线程所有的寄存器帮我们复制一份给子线程,所以当子线程开始运行时就能拿到父线程保存在寄存器中的值,从而拿到这几个参数。
之后,调用 clone 系统调用,内核帮我们创建出了一个子线程。相当于原来的一个执行分支现在变成了两个执行分支,于是会有两个返回。这和著名的 fork 系统调用类似,根据返回值来判断现在是处于父线程还是子线程。
如果是父线程,就直接返回了。如果是子线程,接着还要执行一堆操作,例如设置 tls,设置 m.procid 等等。
最后执行 mstart 函数,这是在 newosproc 函数传递进来的。mstart 函数再调用 mstart1,在 mstart1 里会执行这一行:
// 执行启动函数。初始化过程中,fn == nil
if fn := _g_.m.mstartfn; fn != nil {
fn()
}之前我们在讲初始化的时候,这里的 fn 是空,会跳过的。但在这里,fn 就是最开始在 runtime.main 里设置的 sysmon 函数,因此这里会执行 sysmon,而它又是一个无限循环,永不返回。
所以,这里不会执行到 mstart1 函数后面的 schedule 函数,也就不会进入 schedule 循环。因此这是一个不用和 p 结合的 m,它直接在后台执行,默默地执行监控任务。
接下来,我们就来看 sysmon 函数到底做了什么?
sysmon执行一个无限循环,一开始每次循环休眠 20us,之后(1 ms 后)每次休眠时间倍增,最终每一轮都会休眠 10ms。
sysmon中会进行 netpool(获取 fd 事件)、retake(抢占)、forcegc(按时间强制执行 gc),scavenge heap(释放自由列表中多余的项减少内存占用)等处理。
和调度相关的,我们只关心 retake 函数:
func retake(now int64) uint32 {
n := 0
// 遍历所有的 p
for i := int32(0); i < gomaxprocs; i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
pd := &_p_.sysmontick
// p 的状态
s := _p_.status
if s == _Psyscall {
// P 处于系统调用之中,需要检查是否需要抢占
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
// _p_.syscalltick 用于记录系统调用的次数,在完成系统调用之后加 1
t := int64(_p_.syscalltick)
if int64(pd.syscalltick) != t {
// pd.syscalltick != _p_.syscalltick,说明已经不是上次观察到的系统调用了,
// 而是另外一次系统调用,所以需要重新记录 tick 和 when 值
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// 只要满足下面三个条件中的任意一个,则抢占该 p,否则不抢占
// 1. p 的运行队列里面有等待运行的 goroutine
// 2. 没有无所事事的 p
// 3. 从上一次监控线程观察到 p 对应的 m 处于系统调用之中到现在已经超过 10 毫秒
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) {
// ……………………
n++
_p_.syscalltick++
// 寻找一新的 m 接管 p
handoffp(_p_)
}
incidlelocked(1)
} else if s == _Prunning {
// P 处于运行状态,检查是否运行得太久了
// Preempt G if it's running for too long.
// 每发生一次调度,调度器 ++ 该值
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
//pd.schedtick == t 说明(pd.schedwhen ~ now)这段时间未发生过调度
// 这段时间是同一个goroutine一直在运行,检查是否连续运行超过了 10 毫秒
if pd.schedwhen+forcePreemptNS > now {
continue
}
// 连续运行超过 10 毫秒了,发起抢占请求
preemptone(_p_)
}
}
return uint32(n)
}从代码来看,主要会对处于 _Psyscall 和 _Prunning 状态的 p 进行抢占。
抢占进行系统调用的 P
当 P 处于 _Psyscall 状态时,表明对应的 goroutine 正在进行系统调用。如果抢占 p,需要满足几个条件:
p的本地运行队列里面有等待运行的goroutine。这时p绑定的g正在进行系统调用,无法去执行其他的g,因此需要接管p来执行其他的g。- 没有“无所事事”的
p。sched.nmspinning和sched.npidle都为 0,这就意味着没有“找工作”的m,也没有空闲的p,大家都在“忙”,可能有很多工作要做。因此要抢占当前的p,让它来承担一部分工作。 - 从上一次监控线程观察到
p对应的m处于系统调用之中到现在已经超过 10 毫秒。这说明系统调用所花费的时间较长,需要对其进行抢占,以此来使得retake函数返回值不为 0,这样,会保持sysmon线程 20 us 的检查周期,提高sysmon监控的实时性。
注意,原代码是用的三个与条件,三者都要满足才会执行下面的 continue,也就是不进行抢占。因此要想进行抢占的话,只需要三个条件有一个不满足就行了。于是就有了上述三种情况。
确定要抢占当前 p 后,先使用原子操作将 p 的状态修改为 _Pidle,最后调用 handoffp 进行抢占。
func handoffp(_p_ *p) {
// 如果 p 本地有工作或者全局有工作,需要绑定一个 m
if !runqempty(_p_) || sched.runqsize != 0 {
startm(_p_, false)
return
}
// ……………………
// 所有其它 p 都在运行 goroutine,说明系统比较忙,需要启动 m
if atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) == 0 && atomic.Cas(&sched.nmspinning, 0, 1) { // TODO: fast atomic
// p 没有本地工作,启动一个自旋 m 来找工作
startm(_p_, true)
return
}
lock(&sched.lock)
// ……………………
// 全局队列有工作
if sched.runqsize != 0 {
unlock(&sched.lock)
startm(_p_, false)
return
}
// ……………………
// 没有工作要处理,把 p 放入全局空闲队列
pidleput(_p_)
unlock(&sched.lock)
}handoffp 再次进行场景判断,以调用 startm 启动一个工作线程来绑定 p,使得整体工作继续推进。
当 p 的本地运行队列或全局运行队列里面有待运行的 goroutine,说明还有很多工作要做,调用 startm(_p_, false) 启动一个 m 来结合 p,继续工作。
当除了当前的 p 外,其他所有的 p 都在运行 goroutine,说明天下太平,每个人都有自己的事做,唯独自己没有。为了全局更快地完成工作,需要启动一个 m,且要使得 m 处于自旋状态,和 p 结合之后,尽快找到工作。
最后,如果实在没有工作要处理,就将 p 放入全局空闲队列里。
我们接着来看 startm 函数都做了些什么:
// runtime/proc.go
//
// 调用 m 来绑定 p,如果没有 m,那就新建一个
// 如果 p 为空,那就尝试获取一个处于空闲状态的 p,如果找到 p,那就什么都不做
func startm(_p_ *p, spinning bool) {
lock(&sched.lock)
if _p_ == nil {
// 没有指定 p 则需要从全局空闲队列中获取一个 p
_p_ = pidleget()
if _p_ == nil {
unlock(&sched.lock)
if spinning {
// 如果找到 p,放弃。还原全局处于自旋状态的 m 的数量
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
// 没有空闲的 p,直接返回
return
}
}
// 从 m 空闲队列中获取正处于睡眠之中的工作线程,
// 所有处于睡眠状态的 m 都在此队列中
mp := mget()
unlock(&sched.lock)
if mp == nil {
// 如果没有找到 m
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
// 创建新的工作线程
newm(fn, _p_)
return
}
if mp.spinning {
throw("startm: m is spinning")
}
if mp.nextp != 0 {
throw("startm: m has p")
}
if spinning && !runqempty(_p_) {
throw("startm: p has runnable gs")
}
// The caller incremented nmspinning, so set m.spinning in the new M.
mp.spinning = spinning
// 设置 m 马上要结合的 p
mp.nextp.set(_p_)
// 唤醒 m
notewakeup(&mp.park)
}首先处理 p 为空的情况,直接从全局空闲 p 队列里找,如果没找到,则直接返回。如果设置了 spinning 为 true 的话,还需要还原全局的处于自旋状态的 m 的数值:&sched.nmspinning 。
搞定了 p,接下来看 m。先调用 mget 函数从全局空闲的 m 队列里获取一个 m,如果没找到 m,则要调用 newm 新创建一个 m,并且如果设置了 spinning 为 true 的话,先要设置好 mstartfn:
func mspinning() {
// startm's caller incremented nmspinning. Set the new M's spinning.
getg().m.spinning = true
}这样,启动 m 后,在 mstart1 函数里,进入 schedule 循环前,执行 mstartfn 函数,使得 m 处于自旋状态。
接下来是正常情况下(找到了 p 和 m)的处理:
mp.spinning = spinning
// 设置 m 马上要结合的 p
mp.nextp.set(_p_)
// 唤醒 m
notewakeup(&mp.park)设置 nextp 为找到的 p,调用 notewakeup 唤醒 m。之前我们讲 findrunnable 函数的时候,对于最后没有找到工作的 m,我们调用 notesleep(&_g_.m.park),使得 m 进入睡眠状态。现在终于有工作了,需要老将出山,将其唤醒:
// src/runtime/lock_futex.go
func notewakeup(n *note) {
// 设置 n.key = 1, 被唤醒的线程通过查看该值是否等于 1
// 来确定是被其它线程唤醒还是意外从睡眠中苏醒
old := atomic.Xchg(key32(&n.key), 1)
if old != 0 {
print("notewakeup - double wakeup (", old, ")\n")
throw("notewakeup - double wakeup")
}
futexwakeup(key32(&n.key), 1)
}
notewakeup函数首先使用atomic.Xchg设置note.key值为 1,这是为了使被唤醒的线程可以通过查看该值是否等于 1 来确定是被其它线程唤醒还是意外从睡眠中苏醒了过来。
如果该值为 1 则表示是被唤醒的,可以继续工作,但如果该值为 0 则表示是意外苏醒,需要再次进入睡眠。
调用 futexwakeup 来唤醒工作线程,它和 futexsleep 是相对的。
func futexwakeup(addr *uint32, cnt uint32) {
// 调用 futex 函数唤醒工作线程
ret := futex(unsafe.Pointer(addr), _FUTEX_WAKE, cnt, nil, nil, 0)
if ret >= 0 {
return
}
// ……………………
}futex 由汇编语言实现,前面已经分析过,这里就不重复了。主要内容就是先准备好参数,然后进行系统调用,由内核唤醒线程。
内核在完成唤醒工作之后当前工作线程从内核返回到 futex 函数继续执行 SYSCALL 指令之后的代码并按函数调用链原路返回,继续执行其它代码。
而被唤醒的工作线程则由内核负责在适当的时候调度到 CPU 上运行。
抢占长时间运行的 P
我们知道,Go scheduler 采用的是一种称为协作式的抢占式调度,就是说并不强制调度,大家保持协作关系,互相信任。对于长时间运行的 P,或者说绑定在 P 上的长时间运行的 goroutine,sysmon 会检测到这种情况,然后设置一些标志,表示 goroutine 自己让出 CPU 的执行权,给其他 goroutine 一些机会。
接下来我们就来分析当 P 处于 _Prunning 状态的情况。sysmon 扫描每个 p 时,都会记录下当前调度器调度的次数和当前时间,数据记录在结构体:
type sysmontick struct {
schedtick uint32
schedwhen int64
syscalltick uint32
syscallwhen int64
}前面两个字段记录调度器调度的次数和时间,后面两个字段记录系统调用的次数和时间。
在下一次扫描时,对比 sysmon 记录下的 p 的调度次数和时间,与当前 p 自己记录下的调度次数和时间对比,如果一致。说明 P 在这一段时间内一直在运行同一个 goroutine。那就来计算一下运行时间是否太长了。
如果发现运行时间超过了 10 ms,则要调用 preemptone(_p_) 发起抢占的请求:
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
// 被抢占的 goroutine
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
// 设置抢占标志
gp.preempt = true
// 在 goroutine 内部的每次调用都会比较栈顶指针和 g.stackguard0,
// 来判断是否发生了栈溢出。stackPreempt 非常大的一个数,比任何栈都大
// stackPreempt = 0xfffffade
gp.stackguard0 = stackPreempt
return true
}基本上只是将 stackguard0 设置了一个很大的值,而检查 stackguard0 的地方在函数调用前的一段汇编代码里进行。
举一个简单的例子:
package main
import "fmt"
func main() {
fmt.Println("hello qcrao.com!")
}执行命令:
go tool compile -S main.go得到汇编代码:
"".main STEXT size=120 args=0x0 locals=0x48
0x0000 00000 (test26.go:5) TEXT "".main(SB), $72-0
0x0000 00000 (test26.go:5) MOVQ (TLS), CX
0x0009 00009 (test26.go:5) CMPQ SP, 16(CX)
0x000d 00013 (test26.go:5) JLS 113
0x000f 00015 (test26.go:5) SUBQ $72, SP
0x0013 00019 (test26.go:5) MOVQ BP, 64(SP)
0x0018 00024 (test26.go:5) LEAQ 64(SP), BP
0x001d 00029 (test26.go:5) FUNCDATA $0, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x001d 00029 (test26.go:5) FUNCDATA $1, gclocals·e226d4ae4a7cad8835311c6a4683c14f(SB)
0x001d 00029 (test26.go:6) MOVQ $0, ""..autotmp_0+48(SP)
0x0026 00038 (test26.go:6) MOVQ $0, ""..autotmp_0+56(SP)
0x002f 00047 (test26.go:6) LEAQ type.string(SB), AX
0x0036 00054 (test26.go:6) MOVQ AX, ""..autotmp_0+48(SP)
0x003b 00059 (test26.go:6) LEAQ "".statictmp_0(SB), AX
0x0042 00066 (test26.go:6) MOVQ AX, ""..autotmp_0+56(SP)
0x0047 00071 (test26.go:6) LEAQ ""..autotmp_0+48(SP), AX
0x004c 00076 (test26.go:6) MOVQ AX, (SP)
0x0050 00080 (test26.go:6) MOVQ $1, 8(SP)
0x0059 00089 (test26.go:6) MOVQ $1, 16(SP)
0x0062 00098 (test26.go:6) PCDATA $0, $1
0x0062 00098 (test26.go:6) CALL fmt.Println(SB)
0x0067 00103 (test26.go:7) MOVQ 64(SP), BP
0x006c 00108 (test26.go:7) ADDQ $72, SP
0x0070 00112 (test26.go:7) RET
0x0071 00113 (test26.go:7) NOP
0x0071 00113 (test26.go:5) PCDATA $0, $-1
0x0071 00113 (test26.go:5) CALL runtime.morestack_noctxt(SB)
0x0076 00118 (test26.go:5) JMP 0以前看这段代码的时候会直接跳过前面的几行代码,看不懂。这次能看懂了!所以,那些暂时看不懂的,先放一放,没关系,让子弹飞一会儿,很多东西回过头再来看就会豁然开朗,这就是一个很好的例子。
0x0000 00000 (test26.go:5) MOVQ (TLS), CX将本地存储 tls 保存到 CX 寄存器中,(TLS)表示它所关联的 g,这里就是前面所讲到的 main gouroutine。
0x0009 00009 (test26.go:5) CMPQ SP, 16(CX)比较 SP 寄存器(代表当前 main goroutine 的栈顶寄存器)和 16(CX),我们看下 g 结构体:
type g struct {
// goroutine 使用的栈
stack stack // offset known to runtime/cgo
// 用于栈的扩张和收缩检查
stackguard0 uintptr // offset known to liblink
// ……………………
}对象 g 的第一个字段是 stack 结构体:
type stack struct {
lo uintptr
hi uintptr
}共 16 字节。而 16(CX) 表示 g 对象的第 16 个字节,跳过了 g 的第一个字段,也就是 g.stackguard0 字段。
如果 SP 小于 g.stackguard0,这是必然的,因为前面已经把 g.stackguard0 设置成了一个非常大的值,因此跳转到了 113 行。
0x0071 00113 (test26.go:7) NOP
0x0071 00113 (test26.go:5) PCDATA $0, $-1
0x0071 00113 (test26.go:5) CALL runtime.morestack_noctxt(SB)
0x0076 00118 (test26.go:5) JMP 0调用 runtime.morestack_noctxt 函数:
// src/runtime/asm_amd64.s
TEXT runtime·morestack_noctxt(SB),NOSPLIT,$0
MOVL $0, DX
JMP runtime·morestack(SB)直接跳转到 morestack 函数:
TEXT runtime·morestack(SB),NOSPLIT,$0-0
// Cannot grow scheduler stack (m->g0).
get_tls(CX)
// BX = g,g 表示 main goroutine
MOVQ g(CX), BX
// BX = g.m
MOVQ g_m(BX), BX
// SI = g.m.g0
MOVQ m_g0(BX), SI
CMPQ g(CX), SI
JNE 3(PC)
CALL runtime·badmorestackg0(SB)
INT $3
// ……………………
// Set g->sched to context in f.
// 将函数的返回地址保存到 AX 寄存器
MOVQ 0(SP), AX // f's PC
// 将函数的返回地址保存到 g.sched.pc
MOVQ AX, (g_sched+gobuf_pc)(SI)
// g.sched.g = g
MOVQ SI, (g_sched+gobuf_g)(SI)
// 取地址操作符,调用 morestack_noctxt 之前的 rsp
LEAQ 8(SP), AX // f's SP
// 将 main 函数的栈顶地址保存到 g.sched.sp
MOVQ AX, (g_sched+gobuf_sp)(SI)
// 将 BP 寄存器保存到 g.sched.bp
MOVQ BP, (g_sched+gobuf_bp)(SI)
// newstack will fill gobuf.ctxt.
// Call newstack on m->g0's stack.
// BX = g.m.g0
MOVQ m_g0(BX), BX
// 将 g0 保存到本地存储 tls
MOVQ BX, g(CX)
// 把 g0 栈的栈顶寄存器的值恢复到 CPU 的寄存器 SP,达到切换栈的目的,下面这一条指令执行之前,
// CPU 还是使用的调用此函数的 g 的栈,执行之后 CPU 就开始使用 g0 的栈了
MOVQ (g_sched+gobuf_sp)(BX), SP
// 准备参数
PUSHQ DX // ctxt argument
// 不返回
CALL runtime·newstack(SB)
MOVQ $0, 0x1003 // crash if newstack returns
POPQ DX // keep balance check happy
RET主要做的工作就是将当前 goroutine,也就是 main goroutine 的和调度相关的信息保存到 g.sched 中,以便在调度到它执行时,可以恢复。
最后,将 g0 的地址保存到 tls 本地存储,并且切到 g0 栈执行之后的代码。继续调用 newstack 函数:
func newstack(ctxt unsafe.Pointer) {
// thisg = g0
thisg := getg()
// ……………………
// gp = main goroutine
gp := thisg.m.curg
// Write ctxt to gp.sched. We do this here instead of in
// morestack so it has the necessary write barrier.
gp.sched.ctxt = ctxt
// ……………………
morebuf := thisg.m.morebuf
thisg.m.morebuf.pc = 0
thisg.m.morebuf.lr = 0
thisg.m.morebuf.sp = 0
thisg.m.morebuf.g = 0
// 检查 g.stackguard0 是否被设置成抢占标志
preempt := atomic.Loaduintptr(&gp.stackguard0) == stackPreempt
if preempt {
if thisg.m.locks != 0 || thisg.m.mallocing != 0 || thisg.m.preemptoff != "" || thisg.m.p.ptr().status != _Prunning {
// 还原 stackguard0 为正常值,表示我们已经处理过抢占请求了
gp.stackguard0 = gp.stack.lo + _StackGuard
// 不抢占,调用 gogo 继续运行当前这个 g,不需要调用 schedule 函数去挑选另一个 goroutine
gogo(&gp.sched) // never return
}
}
// ……………………
if preempt {
if gp == thisg.m.g0 {
throw("runtime: preempt g0")
}
if thisg.m.p == 0 && thisg.m.locks == 0 {
throw("runtime: g is running but p is not")
}
// Synchronize with scang.
casgstatus(gp, _Grunning, _Gwaiting)
// ……………………
// Act like goroutine called runtime.Gosched.
// 修改为 running,调度起来运行
casgstatus(gp, _Gwaiting, _Grunning)
// 调用 gopreempt_m 把 gp 切换出去
gopreempt_m(gp) // never return
}
// ……………………
}去掉了很多暂时还看不懂的地方,留到后面再研究。只关注有关抢占相关的。第一次判断 preempt 标志是 true 时,检查了 g 的状态,发现不能抢占,例如它所绑定的 P 的状态不是 _Prunning,那就恢复它的 stackguard0 字段,下次就不会走这一套流程了。然后,调用 gogo(&gp.sched) 继续执行当前的 goroutine。
中间又处理了很多判断流程,再次判断 preempt 标志是 true 时,调用 gopreempt_m(gp) 将 gp 切换出去。
func gopreempt_m(gp *g) {
if trace.enabled {
traceGoPreempt()
}
goschedImpl(gp)
}最终调用 goschedImpl 函数:
func goschedImpl(gp *g) {
status := readgstatus(gp)
if status&^_Gscan != _Grunning {
dumpgstatus(gp)
throw("bad g status")
}
// 更改 gp 的状态
casgstatus(gp, _Grunning, _Grunnable)
// 解除 m 和 g 的关系
dropg()
lock(&sched.lock)
// 将 gp 放入全局可运行队列
globrunqput(gp)
unlock(&sched.lock)
// 进入新一轮的调度循环
schedule()
}将 gp 的状态改为 _Grunnable,放入全局可运行队列,等待下次有 m 来全局队列找工作时才能继续运行,毕竟你已经运行这么长时间了,给别人一点机会嘛。
最后,调用 schedule() 函数进入新一轮的调度循环,会找出一个 goroutine 来运行,永不返回。
这样,关于 sysmon 线程在关于调度这块到底做了啥,我们已经回答完了。总结一下:
- 抢占处于系统调用的
P,让其他m接管它,以运行其他的goroutine。 - 将运行时间过长的
goroutine调度出去,给其他goroutine运行的机会。
8.15 一个调度相关的陷阱
注:这个陷阱已经在 Go 1.14 中基于信号实现了强制抢占而解决。
由于 Go 语言是协作式的调度,不会像线程那样,在时间片用完后,由 CPU 中断任务强行将其调度走。对于 Go 语言中运行时间过长的 goroutine,Go scheduler 有一个后台线程在持续监控,一旦发现 goroutine 运行超过 10 ms,会设置 goroutine 的“抢占标志位”,之后调度器会处理。但是设置标志位的时机只有在函数“序言”部分,对于没有函数调用的就没有办法了。
Golang implements a co-operative partially preemptive scheduler.
所以在某些极端情况下,会掉进一些陷阱。下面这个例子来自参考资料【scheduler 的陷阱】。
func main() {
var x int
threads := runtime.GOMAXPROCS(0)
for i := 0; i < threads; i++ {
go func() {
for { x++ }
}()
}
time.Sleep(time.Second)
fmt.Println("x =", x)
}运行结果是:在死循环里出不来,不会输出最后的那条打印语句。
为什么?上面的例子会启动和机器的 CPU 核心数相等的 goroutine,每个 goroutine 都会执行一个无限循环。
创建完这些 goroutines 后,main 函数里执行一条 time.Sleep(time.Second) 语句。Go scheduler 看到这条语句后,简直高兴坏了,要来活了。这是调度的好时机啊,于是主 goroutine 被调度走。先前创建的 threads 个 goroutines,刚好“一个萝卜一个坑”,把 M 和 P 都占满了。
在这些 goroutine 内部,又没有调用一些诸如 channel,time.sleep 这些会引发调度器工作的事情。麻烦了,只能任由这些无限循环执行下去了。
解决的办法也有,把 threads 减小 1:
func main() {
var x int
threads := runtime.GOMAXPROCS(0) - 1
for i := 0; i < threads; i++ {
go func() {
for { x++ }
}()
}
time.Sleep(time.Second)
fmt.Println("x =", x)
}运行结果:
x = 0不难理解了吧,主 goroutine 休眠一秒后,被 go schduler 重新唤醒,调度到 M 上继续执行,打印一行语句后,退出。主 goroutine 退出后,其他所有的 goroutine 都必须跟着退出。所谓“覆巢之下 焉有完卵”,一损俱损。
至于为什么最后打印出的 x 为 0,之前的文章《曹大谈内存重排》里有讲到过,这里不再深究了。
还有一种解决办法是在 for 循环里加一句:
go func() {
time.Sleep(time.Second)
for { x++ }
}()同样可以让 main goroutine 有机会调度执行。






 关于 LearnKu
关于 LearnKu




推荐文章: