
 Go面试系列
Go面试系列2. 延迟语句
2.1 延迟语句是什么
编程的时候,经常会需要申请一些资源,比如数据库连接、文件、锁等,这些资源需要再使用后释放掉,否则会造成内存泄露。但是编程人员经常容易忘记释放这些资源,从而造成一些事故。 Go 语言直接在语言层面提供 defer 关键字,在申请资源语句的下一行,可以直接用 defer 语句来注册函数结束后执行释放资源的操作。因为这样一颗小小的语法糖,忘关闭资源语句的情况就打打地减少了。
defer 是 Go 语言提供的一种用于注册延迟调用的机制:让函数或语句可以在当前函数执行完毕后(包括通过 return 正常结束或者 panic 导致的异常结束)执行。在需要释放资源的场景非常有用,可以很方便在函数结束前做一些清理操作。在打开资源语句的下一行,直接使用 defer 就可以在函数返回前释放资源,可谓相当的高效。
defer 通常用于一些成对操作的场景:打开连接/关闭连接、加锁/释放锁、打开文件/关闭文件等。使用非常简单:
f, err := os.Open(filename)
if err != nil {
panic(err)
}
if f != nil {
defer f.Close()
}
在打开文件的语句附近,用 defer 语句关闭文件。这样,在函数结束之前,会自动执行 defer 后面的语句来关闭文件。注意,要先判断 f 是否为空,如果 f 不为空,在调用 f.Close() 函数,避免出现异常情况。
当然, defer 会有短暂延迟,对时间要求特别高的程序,可以避免使用它,其他情况一般可以忽略它带来的延迟。特别是 Go 1.14 又对 defer 做了很大幅度的优化,效率提升不少。
下面是一个反面例子:
r.mu.Lock()
rand.Intn(param)
r.mu.Unlock()上面只有三行代码,看起来这里不用 defer 执行 Unlock 并没有什么问题。其实并不是这样,中间这行代码 rand.Intn(param) 其实是有可能发生 panic 的,更严重的情况是,这段代码很有可能被其他人修改,增加更多的逻辑,而这完全不可控。也就是说,在 Lock 和 Unlock 之间的代码一旦出现异常情况导致 panic ,就会形成死锁。因此这里的逻辑是,即使看起来非常简单的代码,使用 defer 也是有必要的,因为需求总是在变化,代码也总会被修改。
2.2 延迟语句的执行顺序是什么
先看下官方文档对 defer 的解释:
Each time a “defer” statement executes, the function value and parameters to the call are evaluated as usual and saved anew but the actual function is not invoked. Instead, deferred functions are invoked immediately before the surrounding function returns, in the reverse order they were deferred. If a deferred function value evaluates to nil, execution panics when the function is invoked, not when the “defer” statement is executed.(每次
defer语句执行的时候,会把函数“压栈”,函数参数会被复制下来; 当外层函数(注意不是代码块,如一个for循环块并不是外层函数)退出时,defer函数按照定义 的顺序逆序执行;如果defer执行的函数为nil,那么会在最终调用函数的时候产生panic。)
defer 语句并不会马上执行,而是会进入一个栈,函数 return 前,会按照先进后出的顺序执行。也就是一说,最先被定义的 defer 语句最后执行。先进后出的原因是后面定义的函数可能会依赖前面的资源,自然要先执行;否则,如果前面先执行了,那后面函数的依赖就没有了,因而可能会出错。
在 defer 函数定义时,对外部变量的引用有两种方式:函数参数、闭包引用。前者再 defer 定义时就把值传递给 defer,并被 cache 起来;后者则会在 defer 函数真正调用时根据整个上下文确定参数当前的值。
defer 后面的函数在执行的时候,函数调用的参数会被保存起来,也就是复制一份。真正执行的时候,实际上用到的是这个复制的变量,因此如果此变量是一个”值“,那么就和定义的是一直的。如果此变量是一个”引用“,那就可能和定义的不一致。
举个例子:
func main() {
var v [3]struct{}
for i := range v {
defer func() {
fmt.Println(i)
} ()
}
}
执行结果:
2
2
2defer 后面跟的是一个闭包,i 是”引用“类型的变量, for 循环结束后 i 的值为 2,因此最后打印了 3 个 2。
再看一个例子:
type num int
func (n num) print() {fmt.Println(n)}
func (n *num) pprint() {fmt.Println(*n)}
func main() {
var n num
defer n.print()
defer n.pprint()
defer func() {n.print()} ()
defer func() {n.pprint()} ()
n = 3
}执行结果为:
3
3
3
0注意,
defer语句的执行顺序和定义顺序相反。
第四个 defer 语句是闭包,引用外部函数的 n ,最终结果为 3;第三个 defer 语句同上;第二个 defer 语句,n 是引用,最终求值是 3;第一个 defer 语句,对 n 直接求值,开始的时候是 0,所以最后是 0。
再看一个延伸例子:
func main() {
defer func() {
fmt.Println("before return")
}()
if true {
fmt.Println("during return")
return
}
defer func() {
fmt.Println("after return")
}()
}
运行结果如下:
during return
before return解析:return 之后的 defer 函数不能被注册,因此不能打印出 after return。
延伸示例则可以视为对 defer 的原理的利用。某些情况下,会故意用到 defer 的”先求值,在延迟调用“的性质。想象这样一个场景:在一个函数里,需要打开两个文件进行合并操作,合并完成后,在函数结束前关闭打开的文件句柄:
func mergeFile() error {
// 打开文件一
f, _ := os.Open("file1.txt")
if f != nil {
defer func(f io.Closer) {
if err := f.Close(); err !=nil {
fmt.Printf("defer close file1.txt err %v\n", err)
}
}(f)
}
// 打开文件二
f, _ := os.Open("file2.txt")
if f != nil {
defer func(f io.Closer) {
if err := f.Close(); err !=nil {
fmt.Printf("defer close file2.txt err %v\n", err)
}
}(f)
}
// ......
return nil
}上面的代码中就用到了 defer 的原理,defer 函数定义的时候,参数就已经复制进去了,之后,真正执行 close() 函数的时候就刚好关闭的是正确的”文件“了,很巧妙,如果不这样,将 f 当成函数参数传递进去的话,最后两个语句关闭的就是同一个文件:都是最后打开的文件。
在调用 close() 函数的时候,要注意一点:先判断调用主题是否为空,否则可能会解引用一个空指针,进而 panic。
2.3 如何拆解延迟语句
如果 defer 像前面介绍的那样简单,这个世界就完美了。但事情总是没那么简单,defer 用得不好,会陷入泥潭。
避免陷入泥潭的关键是必须深刻理解下面这条语句:
return xxx上面这条语句经过编译之后,实际上生成了三条指令:
- 返回值 = xxx。
- 调用
defer函数。 - 空的
return。
第一步和第三步是 return 语句生成的指令,也就是说 return 并不是一条原子指令;第二步是 defer 定义的语句,这里可能会操作返回值,从而影响最终的结果。
看两个例子,试着将 return 语句和 defer 语句拆解到正确的顺序。
第一个例子:
func f()(r int) {
t := 5
defer func() {
t = t + 5
}()
return t
}
拆解后:
func f() (r int) {
t := 5
// 1. 赋值指令
r = t
// 2. defer 被插入到赋值与返回之间执行,这个例子中返回值 r 没被修改过
func() {
t = t + 5
}
// 3. 空的 return 指令
return
}
这里第二步实际上并没有操作返回值 r,因此,main 函数中调用 f() 得到5。
第二个例子:
func f()(r int) {
defer func(r int) {
r = r + 5
}(r)
return 1
}
拆解后:
func f()(r int) {
// 1. 赋值
r = 1
// 2. 这里改的 r 是之前传进去的r,不会改变要返回的那个 r 值
defer func(r int) {
r = r + 5
}(r)
// 3. 空的 return
return 1
}
第二步,改变的是传值进去的 r,是形参的一个复制值,不会影响实参 r。因此,main 函数中需要调用 f() 得到1。
2.4 如何确定延迟语句的参数
defer 语句表达式的值在定义时就已经确定了。下面可以通过三个不同的函数来理解:
func f1() {
var err error
defer fmt.Println(err)
err = errors.New("defer1 error")
return
}
func f2() {
var err error
defer func() {
fmt.Println(err)
}()
err = errors.New("defer2 error")
return
}
func f3() {
var err error
defer func(err error) {
fmt.Println(err)
}(err)
err = errors.New("defer3 error")
return
}
func main() {
f1()
f2()
f3()
}运行结果:
<nil>
defer2 error
<nil>第一和第三个函数中,因为作为参数,err 在函数定义的时候就会求值,并且定义的时候 err 的值都是 nil,所以最后打印的结果都是 nil;第二个函数的参数其实也会在定义的时候求值,但是第二个例子中是一个闭包,它引用的变量 err 在执行的时候值最终变成 defer2 error 了。
现实中第三个函数比较容易犯错误,在生产环境中,很容易写出这样的错误代码,导致最后 defer 语句没有起到作用,造成一些线上事故,要特别注意。
2.5 闭包是什么
闭包是由函数及其相关引用环境组合而成的实体,即:闭包=函数+引用环境。
一般的函数都有函数名,而匿名函数没有。匿名函数不能独立存在,但可以直接调用或者赋值于某个变量。匿名函数也被称为闭包,一个闭包继承了函数声明时的作用域。在 Go 语言中,所有的匿名函数都是闭包。
有个不太恰当的例子:可以把闭包看成是一个类,一个闭包函数调用就是实例化一个类。闭包在运行时可以有多个实例,它会将同一个作用域里的变量和常量捕获下来,无论闭包在什么地方被调用(实例化)时,都可以使用这些变量和常量。而且,闭包捕获的变量和常量是引用传递,不是值传递。
举个例子:
func main() {
var a = Accumulator()
fmt.Printf("%d\n", a(1))
fmt.Printf("%d\n", a(10))
fmt.Printf("%d\n", a(100))
fmt.Println("------------------------")
var b = Accumulator()
fmt.Printf("%d\n", b(1))
fmt.Printf("%d\n", b(10))
fmt.Printf("%d\n", b(100))
}
func Accumulator() func(int) int {
var x int
return func(delta int) int {
fmt.Printf("(%+v, %+v) - ", &x, x)
x += delta
return x
}
}执行结果是:
(0xc420014070, 0) - 1
(0xc420014070, 1) - 11
(0xc420014070, 11) - 111
------------------------
(0xc4200140b8, 0) - 1
(0xc4200140b8, 1) - 11
(0xc4200140b8, 11) – 111闭包引用了 x 变量,a,b 可看作 2 个不同的实例,实例之间互不影响。实例内部,x 变量是同一个地址,因此具有“累加效应”。
2.6 延迟语句如何配合恢复语句
Go 语言被诟病多次的就是它的 error,实际项目里经常出现各种 error 满天飞,正常的代码逻辑里有很多 error 处理的代码块。函数总是会返回一个 error,留给调用者处理;而如果是致命的错误,比如程序执行初始化的时候出问题,最好直接 panic 掉,避免上线运行后出更大的问题。
有些时候,需要从异常中恢复。比如服务器程序遇到严重问题,产生了 panic,这时至少可以在程序崩溃前做一些“扫尾工作”,比如关闭客户端的连接,防止客户端一直等待等;并且单个请求导致的 panic,也不应该影响整个服务器程序的运行。
panic 会停掉当前正在执行的程序,而不只是当前线程。在这之前,它会有序地执行完当前线程 defer 列表里的语句,其他协程里定义的 defer 语句不作保证。所以在 defer 里定义一个 recover 语句,防止程序直接挂掉,就可以起到类似 Java 里 try...catch 的效果。
注意,recover() 函数只在 defer 的函数中直接调用才有效。例如:
func main() {
defer fmt.Println("defer main")
var user = os.Getenv("USER_")
go func() {
defer func() {
fmt.Println("defer caller")
if err := recover(); err != nil {
fmt.Println("recover success, err: ", err)
}
}()
func() {
defer func() {
fmt.Println("defer here")
}()
if user == "" {
panic("should set user env")
}
fmt.Println("after panic")
}()
}()
time.Sleep(100)
fmt.Println("end of main function")
}
执行结果:
defer here
defer caller
recover success. err: should set user env.
end of main function
defer main代码中的 panic 最终会被 recover 捕获到。这样的处理方式在一个 http server 的主流程常常会被用到。一次偶然的请求可能会触发某个 bug,这时用 recover 捕获 panic,稳住主流程,不影响其他请求。
再看几个延伸的示例。这些例子都与 recover() 函数的调用位置有关。
考虑一下写法,程序是否能正确 recover 吗?如果不能,原因是什么:
第一个例子:
func main() {
defer f()
panic(404)
}
func f() {
if e := recover(); err != nil {
fmt.Println("recover")
return
}
}
能,在 defer 函数中调用,生效。
第二个例子:
func main() {
recover()
panic(404)
}
不能。直接调用 recover,返回 nil。
第三个例子:
func main() {
defer recover()
panic(404)
}不能。要在 defer 函数中调用 recover。
第四个例子:
func main() {
defer func() {
if e := recover(); e != nil {
fmt.Println(err)
}
}()
panic(404)
}
能,在 defer 函数中调用,生效。
第五个例子:
func main() {
defer func() {
defer func() {
recover()
}()
}()
panic()
}
不能,多重 defer 嵌套。
2.7 defer 链如果被遍历执行
为了在退出函数前执行一些资源清理的操作,例如关闭文件、释放连接、释放锁资源等,会在函数里写上多个 defer 语句,被 defered 的函数,以“先进后出”的顺序,在 RET 指令前得以执行。
在一条函数调用链中,多个函数中会出现多个 defer 语句。例如:a()→b()→c() 中,每个函数里都有 defer 语句,而这些 defer 语句会创建对应个数的 _defer 结构体,这些结构体以链表的形式“挂”在 G 结构体下。看起来像这样,如图所示:
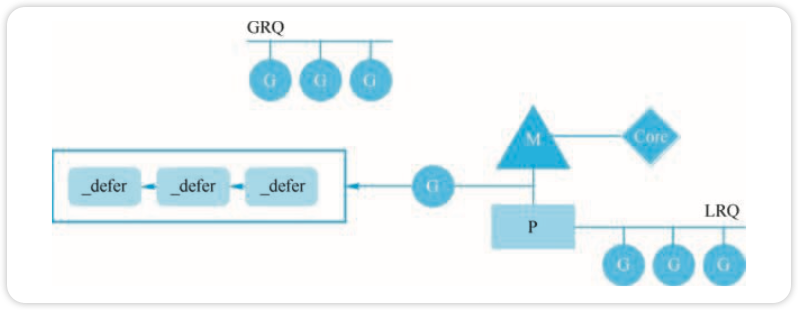
多个 _defer 结构体形成一个链表,G 结构体中某个字段指向此链表。
在编译器的“加持下”,defer 语句会先调用 deferporc 函数,new 一个 _defer 结构体,挂到 G 上。当然,调用 new 之前会优先从当前 G 所绑定的 P 的 defer pool 里取,没取到则会去全局的 defer pool 里取,实在没有的话才新建一个。这是 Go runtime 里非常常见的操作,即设置多级缓存,提升运行效率。
在执行 RET 指令之前(注意不是 return 之前),调用 deferreturn 函数完成 _defer 链表的遍历,执行完这条链上所有被 defered 的函数(如关闭文件、释放连接、释放锁资源等)。在 deferreturn 函数的最后,会使用 jmpdefer 跳转到之前被 defered 的函数,这时控制权从 runtime 转移到了用户自定义的函数。这只是执行了一个被 defered 的函数,那这条链上其他的被 defered 的 函数,该如何得到执行?
答案就是控制权会再次交给 runtime,并再次执行 deferreturn 函数,完成 defer 链表的遍历。
2.8 为什么无法从父 goroutine 恢复子 goroutine 的 panic
对于这个问题,其实更普遍的问题是:为什么无法 recover 其他 goroutine 里产生的 panic?
可能会好奇为什么会有人希望从父 goroutine 中恢复子 goroutine 内产生的 panic。这是因为,如果以下的情况发生在应用程序内,那么整个进程必然退出:
go func() {
panic("die die die")
}()当然,上面的代码是显式的 panic,实际情况下,如果不注意编码规范,极有可能触发一些本可以避免的恐慌错误,例如访问越界:
go func() {
a := make([]int, 1)
println(a[1])
}()发生这种恐慌错误对于服务端开发而言几乎是致命的,因为开发者将无法预测服务的可用性,只能在错误发生时发现该错误,但这时服务不可用的损失已经产生了。
那么,为什么不能从父 goroutine 中恢复子 goroutine 的 panic?或者一般地说,为什么某个 goroutine 不能捕获其他goroutine 内产生的 panic?
其实这个问题从 Go 诞生以来就一直被长久地讨论,而答案可以简单地认为是设计使然:因为 goroutine 被设计为一个独立的代码执行单元,拥有自己的执行栈,不与其他 goroutine 共享任何数据。这意味着,无法让 goroutine 拥有返回值、也无法让 goroutine 拥有自身的 ID 编号等。若需要与其他 goroutine 产生交互,要么可以使用 channel 的方式与其他 goroutine 进行通信,要么通过共享内存同步方式对共享的内存添加读写锁。
那一点办法也没有了吗?方法自然有,但并不是完美的方法,这里提供一种思路。例如,如果希望有一个全局的恐慌捕获中心,那么可以通过创建一个恐慌通知 channel,并在产生恐慌时,通过 recover 字段将其恢复,并将发生的错误通过 channel 通知给这个全局的恐慌通知器:
package main
import (
"fmt"
"time"
)
var notifier chan interface{}
func startGlobalPanicCapturing() {
notifier = make(chan interface{})
go func() {
for {
select {
case r := <- notifier:
fmt.Println(r)
}
}
}()
}
func main() {
startGlobalPanicCapturing()
// 产生恐慌,但该恐慌会被捕获
Go(func() {
a := make([]int, 1)
println(a[1])
})
}
// Go 是一个恐慌安全的 goroutine
func Go(f func()) {
go func() {
defer func() {
if r := recover(); r != nil {
notifer <- i
}
}()
}()
}上面的 func Go(f func()) 本质上是对 go 关键字进行了一层封装,确保在执行并发单元前插入一个 defer,从而能够保证恢复一些可恢复的错误。
之所以说这个方案并不完美,原因是如果函数 f 内部不再使用 Go 函数来创建 goroutine,而且含有继续产生必然恐慌的代码,那么仍然会出现不可恢复的情况。
go func() {panic("die die die")}()有人可能也许会想到,强制某个项目内均使用 Go 函数不就好了? 事情也并没有这么简单。因为除了可恢复的错误外,还有一些不可恢复的运行时恐慌(例如并发读写 map),如果这类恐慌一旦发生,那么任何补救都是徒劳的。解决这类问题的根本途径是提高程序员自身对语言的认识,多进行代码测试,以及多通过运维技术来增强容灾机制。






 关于 LearnKu
关于 LearnKu



