
 PHP 面试题
PHP 面试题缓存
Redis 缓存三大问题
缓存穿透
缓存穿透是指查询一条数据库和缓存都没有的一条数据,就会一直查询数据库,对数据库的访问压力就会增大。
缓存穿透的解决方案:缓存空对象(代码维护较简单,但是效果不好)、布隆过滤器(代码维护复杂,效果很好)。
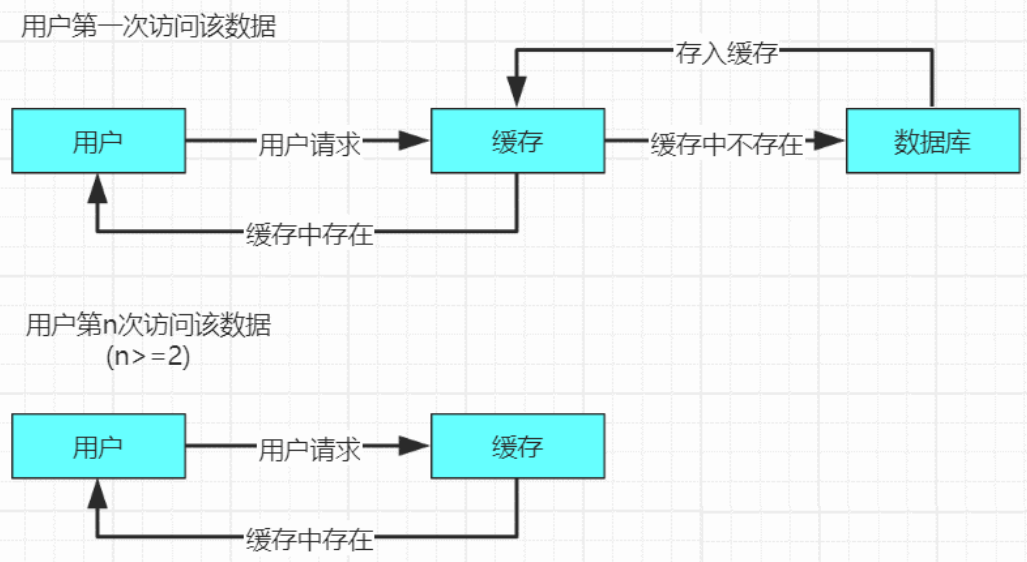
(1)缓存空对象
缓存空对象是指当一个请求过来缓存中和数据库中都不存在该请求的数据,第一次请求就会跳过缓存进行数据库的访问,并且访问数据库后返回为空,此时也将该空对象进行缓存。若是再次进行访问该空对象的时候,就会直接击中缓存,而不是再次访问数据库。
缓存空对象实现的原理图如下:
(2)布隆过滤器
布隆过滤器是一种基于概率的数据结构,主要用来判断某个元素是否在集合内。它具有运行速度快,占用内存小的优点,但是有一定的误识别率和删除困难的问题。它只能告诉你某个元素一定不在集合内或可能在集合内。
布隆过滤器的特点如下:
一个非常大的二进制位数组 (数组里只有0和1)
若干个哈希函数
空间效率和查询效率高
不存在漏报(False Negative):某个元素在某个集合中,肯定能报出来。
可能存在误报(False Positive):某个元素不在某个集合中,可能也被爆出来。
不提供删除方法,代码维护困难。
位数组初始化都为 0,它不存元素的具体值,当元素经过哈希函数哈希后的值(也就是数组下标)对应的数组位置值改为1。
布隆过滤器实现的原理如下:
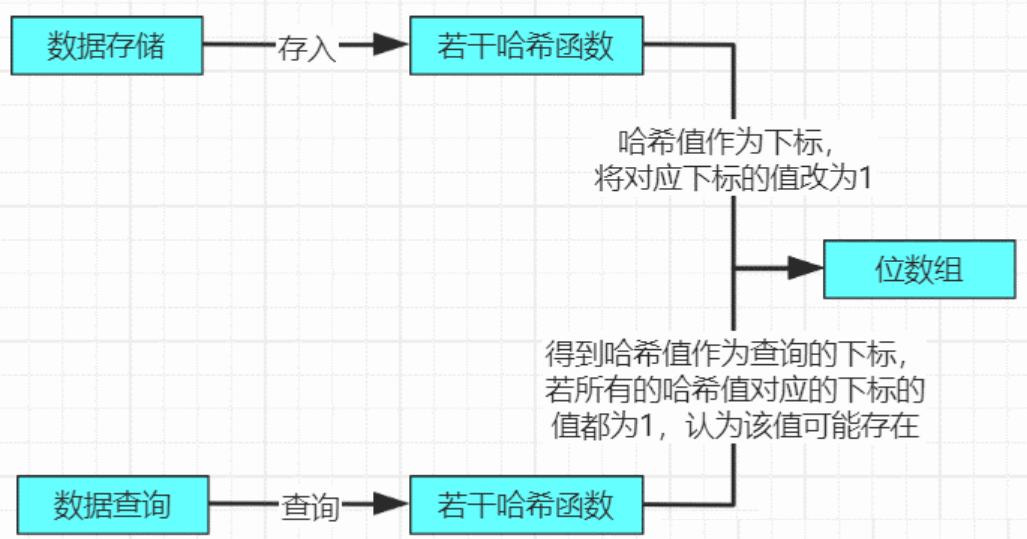
插入流程:将要添加的元素给 m 个哈希函数(布隆过滤器中有多少个哈希函数就会计算出多少个下标),得到对应于位数组上的 m 个位置,将这 m 个位置设为 1。
误判率:即它可能会把不属于这个集合的元素认为可能属于这个集合,但是不会把属于这个集合的认为不属于这个集合。
假如元素 a 经过两个哈希函数计算得出下标
2 和 13。但是2 和 13实际上是 元素 x、y 的下标。该布隆过滤器中实际不存在 a,但布隆过滤器误判改值可能存在,所以存在误判率。为什么不能删除元素呢?
答:因为删除元素后,将对应元素的下标设置为零,可能别的元素的下标也引用该下标,这样别的元素的判断就会受到影响。
缓存击穿
缓存击穿是指大并发集中对这一个 key 进行访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,瞬间对数据库的访问压力增大。
缓存击穿这里强调的是并发,造成缓存击穿的原因有以下两个:
- 该数据没有人查询过 ,第一次就大并发的访问。(冷门数据)
- 添加到了缓存,reids 有设置数据失效的时间,这条数据刚好失效,大并发访问(热点数据)
对于缓存击穿的解决方案就是加锁,具体实现的原理图如下:
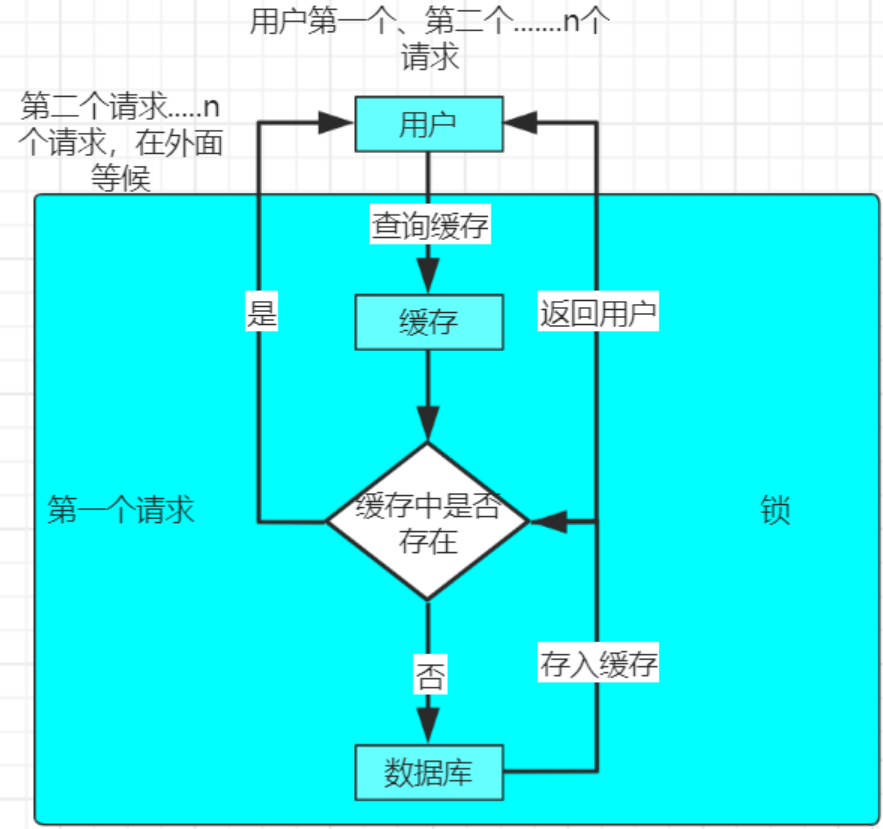
普遍做法是根据 key 获取 value 值为空时锁上,从数据库中 load 数据后再释放锁。若其它线程获取锁失败,则等待一段时间后重试。
缓存雪崩
缓存雪崩是指在某一个时间段,缓存集中过期失效。此刻无数的请求直接绕开缓存,直接请求数据库。
造成缓存雪崩的原因,有两种:reids 宕机、大部分数据失效
Redis 数据淘汰策略
voltile-lru在设置了过期时间的数据中, 淘汰最近最少使用的数据voltile-ttl淘汰将设置了过期时间的数据, ttl大的优先淘汰 (即最接近过期的)voltile-random随机淘汰设置了过期时间的数据allkeys-lru淘汰最近最少使用的数据allkeys-random任意选择淘汰no-eviction禁止淘汰, 当内存不足时写入数据, 会返回错误(系统默认)
Redis key 的过期策略
- 定时过期: 每个设置了过期时间的 key 都创建一个定时器, 到期自动清除。(内存友好, CPU 不友好)
- 惰性过期: 只有在访问一个 key 时, 才判断 key 是否已经过期。(CPU 友好, 内存不友好)
- 定期过期: 每隔一定时间, 扫描一定数量的设置了过期时间的数据集, 然后清除






 关于 LearnKu
关于 LearnKu




推荐文章: