
 PHP 面试题
PHP 面试题索引
索引
什么是索引
索引(Index)是帮助Mysql高效获取数据的数据结构。
索引结构
B树
B树也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
一颗m阶的B树定义(结构)如下:
- 根节点至少一个元素:1 <= k <= m-1
- 非根节点元素范围:ceil(m/2) <= k <= m-1
- 每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子结点都位于同一层。
例子:
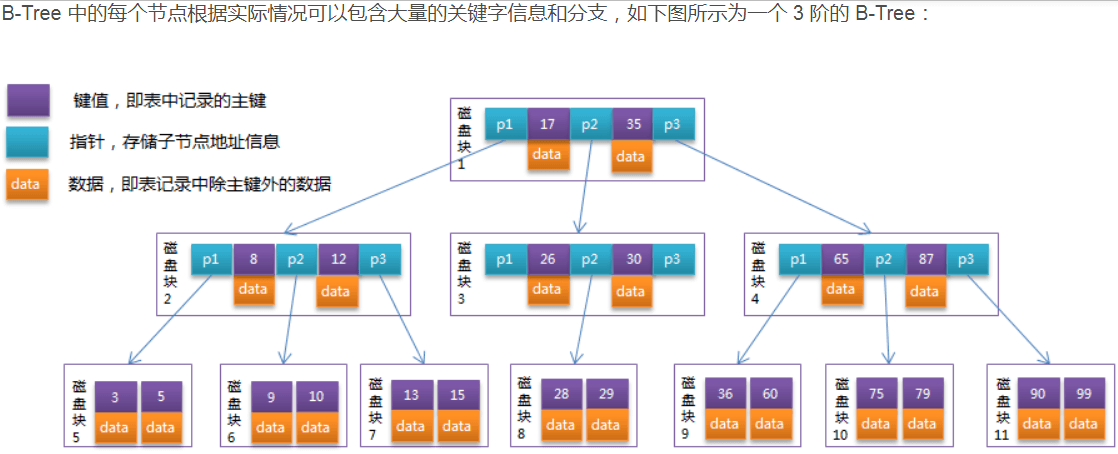
- 每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的 key 和三个指向子树根节点的 point ,point 存储的是子节点所在磁盘块的地址。两个 key 划分成的三个范围域,对应三个 point 指向的子树的数据的范围域。
- 以根节点为例,key 为 17 和 35 ,P1 指针指向的子树的数据范围为小于 17 ,P2 指针指向的子树的数据范围为 [17~35] ,P3 指针指向的子树的数据范围为大于 35 。
模拟查找 key 为 29 的过程:
- 根据根节点找到磁盘块 1 ,读入内存。【磁盘I/O操作第1次】
- 比较 key 29 在区间(17,35),找到磁盘块 1 的指针 P2 。
- 根据 P2 指针找到磁盘块 3 ,读入内存。【磁盘I/O操作第2次】。
- 比较 key 29 在区间(26,30),找到磁盘块3的指针P2。
- 根据 P2 指针找到磁盘块 8 ,读入内存。【磁盘I/O操作第3次】
- 在磁盘块 8 中的 key 列表中找到 eky 29 。
分析上面过程,发现需要 3 次磁盘 I/O 操作,和 3 次内存查找操作。由于内存中的 key 是一个有序表结构,可以利用二分法查找提高效率。而 3 次磁盘 I/O 操作是影响整个 B-Tree 查找效率的决定因素。B-Tree 相对于 AVLTree 缩减了节点个数,使每次磁盘 I/O 取到内存的数据都发挥了作用,从而提高了查询效率。
B+树
InnoDB 底层数据结构是B+树,所谓的索引其实就是一颗B+树,一个表有多少个索引就会有多少颗B+树,mysql 中的数据都是按顺序保存在B+树上的。
m 为阶数,即非叶子节点有 m 棵子树。k 为关键字(元素),即数据。比如5阶B+树的节点最少2个元素,最多4个元素。
一颗m阶的B+树定义如下:
- 根节点至少一个元素:1 <= k <= m-1
- 非根节点元素范围:m/2 <= k <= m-1
- B+树有两种类型的节点:内部结点(也称索引结点、非叶子节点)和叶子结点。内部节点只存储索引,叶子节点只存储数据。
- 内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
- 每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
- 父节点存有右孩子的第一个元素的索引。
例子:
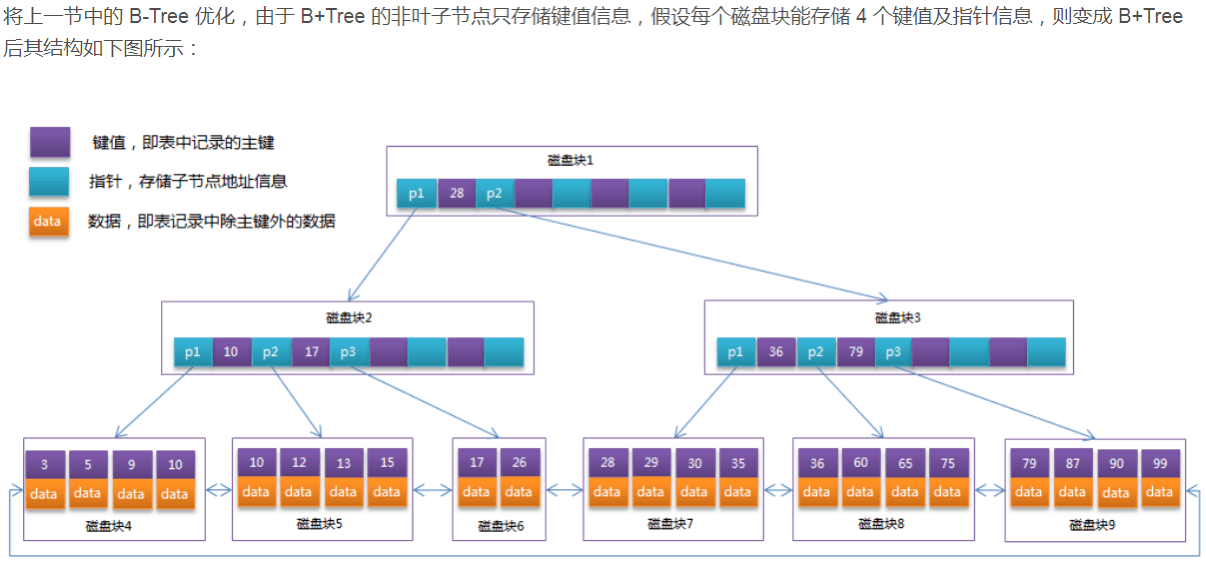
- 通常在 B+Tree 上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
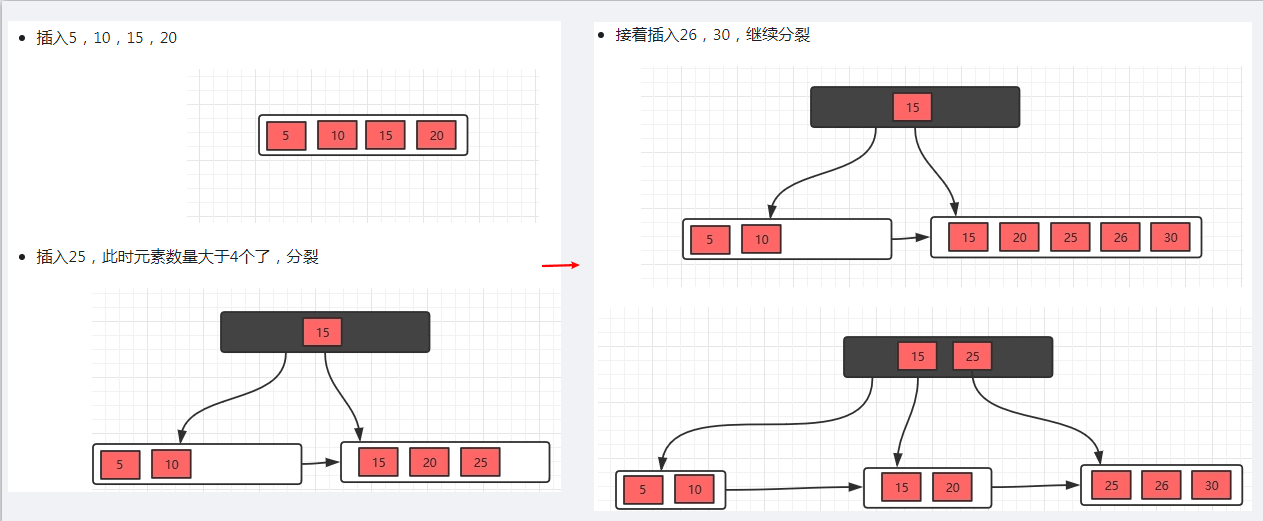
B+树插入操作
当节点元素数量大于m-1的时候,按中间元素分裂成左右两部分,中间元素分裂到父节点当做索引存储,但是,本身中间元素还是分裂右边这一部分的。
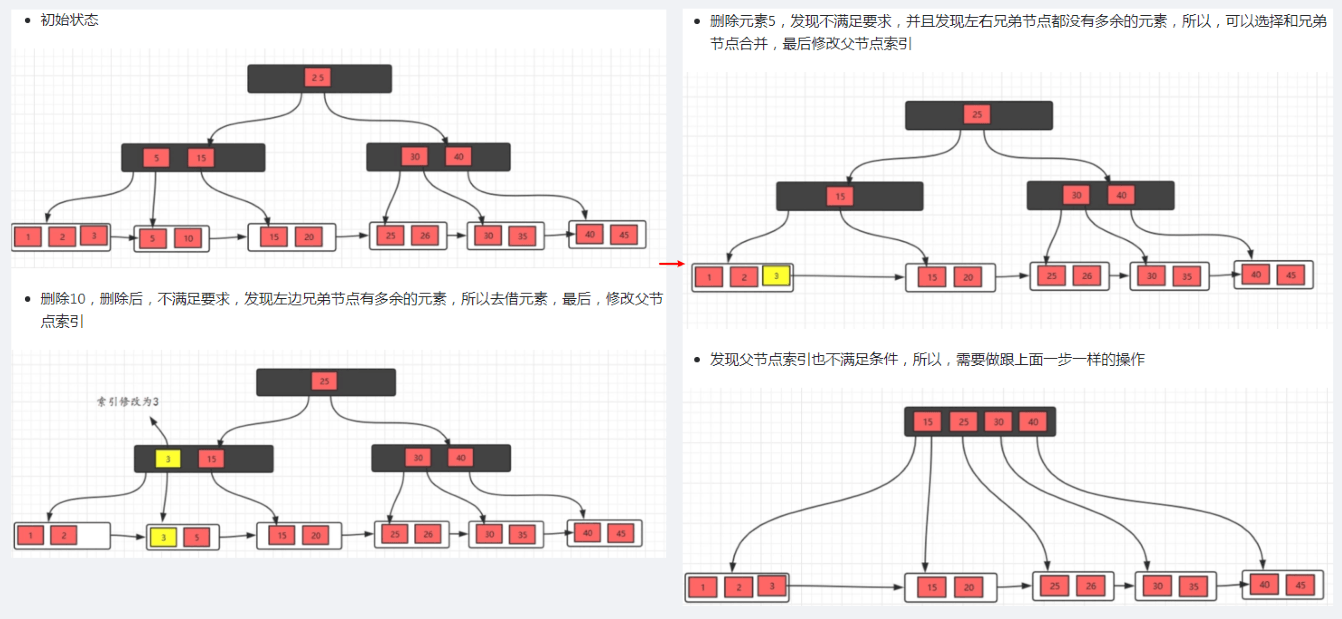
B+树删除操作
因为叶子节点有指针的存在,向兄弟节点借元素时,不需要通过父节点,而是可以直接通过兄弟节移动即可(前提是兄弟节点的元素大于m/2),然后更新父节点的索引;如果兄弟节点的元素不大于m/2(兄弟节点也没有多余的元素),则将当前节点和兄弟节点合并,并且删除父节点中的key。
B+树有哪些索引类型
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引:叶子节点存的数据是整行数据( 即具体数据 )。在 InnoDB 里,主键索引也被称为聚集索引(clustered index)。
- 非主键索引:叶子节点存的数据是整行数据的主键,键值是索引。在 InnoDB 里,非主键索引也被称为辅助索引(secondary index)。
辅助索引与聚集索引的区别在于辅助索引的叶子节点存储的是相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,需要进过两步:
- 首先,InnoDB 存储引擎会遍历辅助索引找到主键。
- 然后,再通过主键在聚集索引中找到完整的行记录数据。
为什么 Mysql 使用 B+ 树
B-Tree 每个节点中不仅包含数据的 key 值,还有 data 值,而每一个页的存储空间是有限的,如果 data 数据较大时将会导致页存储 key 的数量减少、 B-Tree 的深度变大,增大了查询时的磁盘 I/O 次数,进而影响查询效率。在 B+Tree 中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储 key 值信息,这样可以大大加大页存储的 key 值数量,降低 B+Tree 的高度。
为什么主键一般都要自增
答:因为使用自增 id 可以避免页分裂。
mysql 在底层是以数据页为单位来存储数据的,一个数据页大小默认为 16k,也就是说如果一个数据页存满了,mysql 就会去申请一个新的数据页来存储数据。如果主键为自增 id 的话,mysql 在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。如果主键是非自增 id,为了确保索引有序,mysql 就需要将每次插入的数据都放到合适的位置上。
当往一个快满或已满的数据页中插入数据时,新插入的数据会将数据页写满,mysql 就需要申请新的数据页,并且把上个数据页中的部分数据挪到新的数据页上。这就造成了页分裂,这个大量移动数据的过程是会严重影响插入效率的。
其实对主键 id 还有一个小小的要求,在满足业务需求的情况下,尽量使用占空间更小的主键 id,因为普通索引的叶子节点上保存的是主键 id 的值,如果主键 id 占空间较大的话,那将会成倍增加 mysql 空间占用大小。
索引的类型
普通索引:最基本的索引,没有任何约束。
唯一索引:与普通索引类似,但具有唯一性约束。
主键索引:特殊的唯一索引,不允许有空值。
复合索引:将多个列组合在一起创建索引,可以覆盖多个列。
外键索引:只有 InnoDB 类型的表才可以使用外键索引,保证数据的一致性、完整性和实现级联操作。
全文索引:Mysql 自带的全文索引只能用于 InnoDB、MyISAM ,并且只能对英文进行全文检索,一般使用全文索引引擎。
常用的全文索引引擎的解决方案有 Elasticsearch、Solr 等等。最为常用的是 Elasticsearch 。
索引的优缺点
优点:
- 提高数据的检索速度,降低数据库IO成本:使用索引的意义就是通过缩小表中需要查询的记录的数目从而加快搜索的速度。
- 降低数据排序的成本,降低CPU消耗:索引之所以查的快,是因为先将数据排好序,若该字段正好需要排序,则正好降低了排序的成本
缺点:
- 占用存储空间:索引实际上也是一张表,记录了主键与索引字段,一般以索引文件的形式存储在磁盘上。
- 降低更新表的速度:表的数据发生了变化,对应的索引也需要一起变更,从而减低的更新速度。否则索引指向的物理数据可能不对,这也是索引失效的原因之一。
索引的创建原则
最适合索引的列是出现在 WHERE 子句或连接子句中的列,而不是出现在 SELECT 后的列。
索引列的基数越大,索引效果越好。
索引基数:索引中不重复的索引值的数量
根据情况创建复合索引,复合索引可以提高查询效率。
因为复合索引的基数会更大。
避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率。
主键尽可能选择较短的数据类型,可以有效减少索引的磁盘占用,提高查询效率。
对字符串进行索引,应该定制一个前缀长度,可以节省大量的索引空间。
索引使用场景
where、order by、join、索引覆盖
InnoDB 索引
(1)表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?
答:InnoDB 存储引擎的最小储存单元:页(Page),一个页的大小是16K(16384字节)。假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。
- InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,在B+树中叶子节点存放数据,非叶子节点存放键值+指针。
- 索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据;
(2)InnoDB 的一棵B+树可以存放多少行数据?
答:约2千万。
MyISAM 索引
MyISAM 索引的实现,和 InnoDB 索引的实现是一样使用 B+Tree ,差别在于 MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
聚簇索引&非聚簇索引
聚簇索引 (clustered index):主键索引的叶子节点存的是整行数据。
非聚簇索引(secondary index ):非主键索引的叶子节点内容是主键的值。
针对各查询语句:
- 如果语句是 select * from T where ID=500 ,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5 ,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID的值为 500 ,再到 ID 索引树搜索一次。这个过程称为回表。也就是说,innodb基于非主键索引的查询需要多扫描一棵索引树。
联合索引:指对表上的多个列进行索引。联合索引也是一颗B+树,不同的是联合索引的键值数量不是1,而是大于等于2。
覆盖索引:如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。覆盖索引是一种索引优化,只需扫描索引而无须回表
InnoDB 主键使用的是聚簇索引,innodb 普通索引叶子保存的是记录的主键。MyISAM 不管是主键索引,还是二级索引使用的都是非聚簇索引,索引叶子保存的是记录的位置 / 偏移量。
索引的最左匹配特性
当 B+Tree 的数据项是复合的数据结构,比如索引 (name, age, sex) 的时候,B+Tree 是按照从左到右的顺序来建立搜索树的。
- 比如当
(张三, 20, F)这样的数据来检索的时候,B+Tree 会优先比较 name 来确定下一步的所搜方向,如果 name 相同再依次比较 age 和 sex ,最后得到检索的数据。 - 但当
(20, F)这样的没有 name 的数据来的时候,B+Tree 就不知道下一步该查哪个节点,因为建立搜索树的时候 name 就是第一个比较因子,必须要先根据 name 来搜索才能知道下一步去哪里查询。 - 比如当
(张三, F)这样的数据来检索时,B+Tree 可以用 name 来指定搜索方向,但下一个字段 age 的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是 F 的数据了。






 关于 LearnKu
关于 LearnKu



