
 PHP 面试题
PHP 面试题数据结构
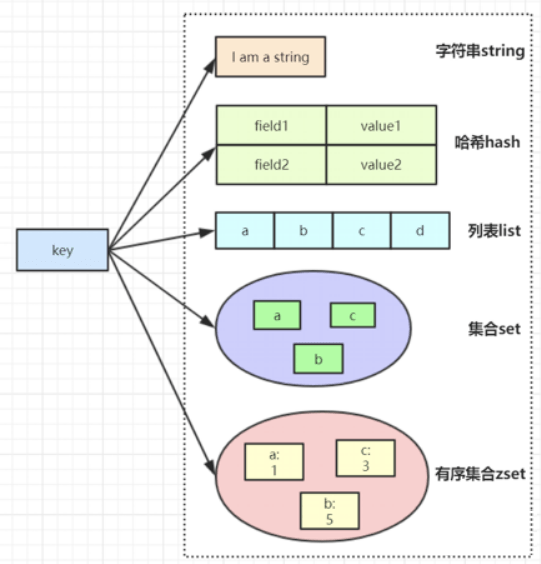
String 字符串
字符串常用操作
SET key value # 存入字符串键值对
MSET key value [key value ...] # 批量存储字符串键值对
SETNX key value # 存入一个不存在的字符串键值对
GET key # 获取一个字符串键值
MGET key [key ...] # 批量获取字符串键值
DEL key [key ...] # 删除一个键
EXPIRE key seconds # 设置一个键的过期时间(秒)原子加减
INCR key # 将key中储存的数字值加1
DECR key # 将key中储存的数字值减1
INCRBY key increment # 将key所储存的值加上increment
DECRBY key decrement # 将key所储存的值减去decrementSDS 结构定义
SDS(Simple Dynamic String 简单动态字符串)是 Redis 里面的一种结构,通过它对字符串的操作进行了很多的优化操作。
struct stdhdr {
int len // 记录 buff 数组中已使用字节的数量
int free // 记录 buff 数组中未使用字节的数量
char buff[] // 字节数组,用于保存字符串
}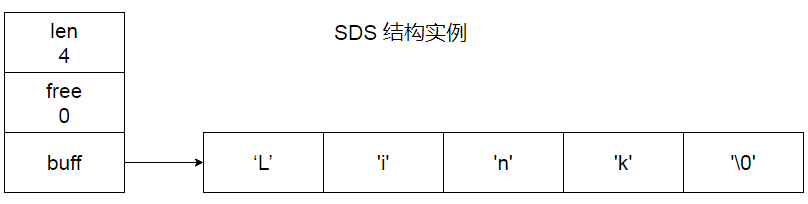
- len:值为4, 表示这个 SDS 保存一个四字节长的字符串。
- free:值为0,表示这个 SDS 没有分配任何未使用空间。
- buff:值为一个 char 类型数组,分别保存
'L' 'i' 'n' 'k'4个字符,最后一个字节保存'\0'。
SDS 与 C 字符串的区别
- 因为 C 字符串并没有记录字符串的长度信息,所以在获取 C 字符串长度的时候必须遍历整个 C 字符串(代表字符串结尾的空字符’\0’不计算进去),时间复杂度就是O(N);SDS 有 len 属性记录了长度,所以获取长度的时间复杂度仅为O(1)。
- C 字符串容易缓冲区溢出,而 SDS 的空间分配策略则不会。当需要操作字符串时,会先检测空间大小,如果不满足,则需要对空间做扩展。
- C 在对字符串做修改时,因为没有记录长度信息,所以需要频繁对内存做分配,而 SDS 通过 free 属性来记录未使用的空间,实现空间预分配和惰性空间释放。
- SDS 是二进制安全的,除了可以储存字符串以外还可以储存二进制文件(如图片、音频,视频等文件的二进制数据);而 C 字符串是以空字符串作为结束符,一些图片中含有结束符,因此不是二进制安全的。
空间预分配
空间预分配用于优化 SDS 的字符串增长操作,当对 SDS 字符做修改时,不仅会分配所需要的空间,还会为 SDS 分配额外的未使用空间。
分配未使用空间策略:当修改字符串后的长度 len 小于 1MB,就会预分配和 len 一样长度的空间;若是 len 大于 1MB,free 分配的空间大小就为 1MB
惰性空间释放
惰性空间释放用于优于 SDS 的字符串缩短操作,当缩短 SDS 字符串时,程序不立即使用内存重分配回收多出来的字节,而是用 free 属性记录,下次要用时,查看 free 的大小,避免重复分配了。
List 列表
Redis中的列表在3.2之前的版本是使用 ziplist 和 linkedlist 进行实现的。在3.2之后的版本就是引入了 quicklist。
linkedlist 和 quicklist 的底层实现是采用链表进行实现,Redis实现了自己的链表结构。
List 常用操作
LPUSH key value [value ...] # 将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value ...] # 将一个或多个值value插入到key列表的表尾(最右边)
LPOP key # 移除并返回key列表的头元素
RPOP key # 移除并返回key列表的尾元素
LRANGE key start stop # 返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout # 从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒。如果timeout=0阻塞等待
BRPOP key [key ...] timeout # 从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒。如果timeout=0阻塞等待使用 List 构造数据结构
- Stack(栈) = LPUSH + LPOP 左进左出
- Queue(队列) = LPUSH + RPOP 左进右出
- Blocking MQ(阻塞队列)= LPUSH + BRPOP 左进右出(阻塞)
Hash 哈希表
Hash 对象的实现方式有两种分别是 ziplist、hashtable。
Redis 的数据库使用字典作为底层实现的,通过 key 和 value 的键值对形式,代表了数据库中全部数据。而且,所有对数据库的增删查改的命令都是建立在对字典的操作上。
Hash 常用操作
HSET key field value # 存储一个哈希表key的键值
HSETNX key field value # 存储一个不存在的哈希表key的键值
HMSET key field value [field value ...] # 在一个哈希表key中存储多个键值对
HGET key field # 获取哈希表key对应的field键值
HMGET key field [field ...] # 批量获取哈希表key中多个field键值
HDEL key field [field ...] # 删除哈希表key中的field键值
HLEN key # 返回哈希表key中field的数量
HGETALL key # 返回哈希表key中所有的键值
HINCRBY key field increment # 为哈希表key中field键的值加上增量increment字典结构
字典类型的底层就是 hashtable 实现的,明白了字典的底层实现原理也就是明白了 hashtable 的实现原理。hashtable 在新增时会通过 key 计算出数组下标:hashtable 中计算出 hash 值后,还要通过 sizemask 属性和哈希值再次得到数组下标。
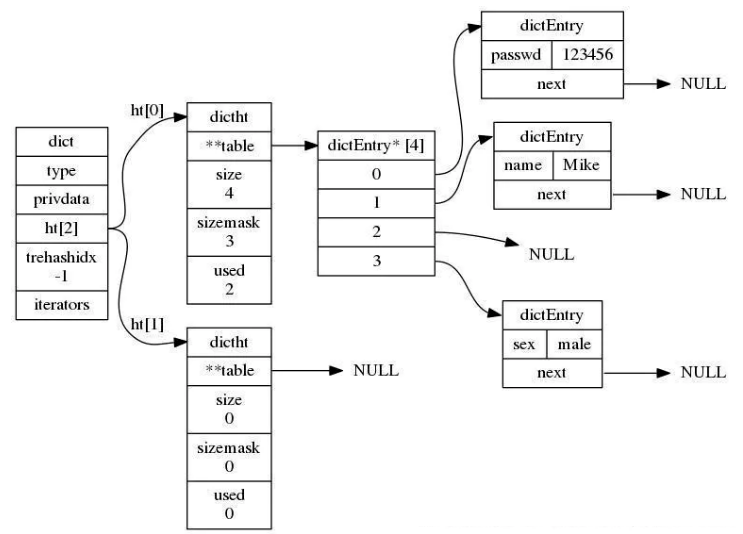
- dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁,这时候两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
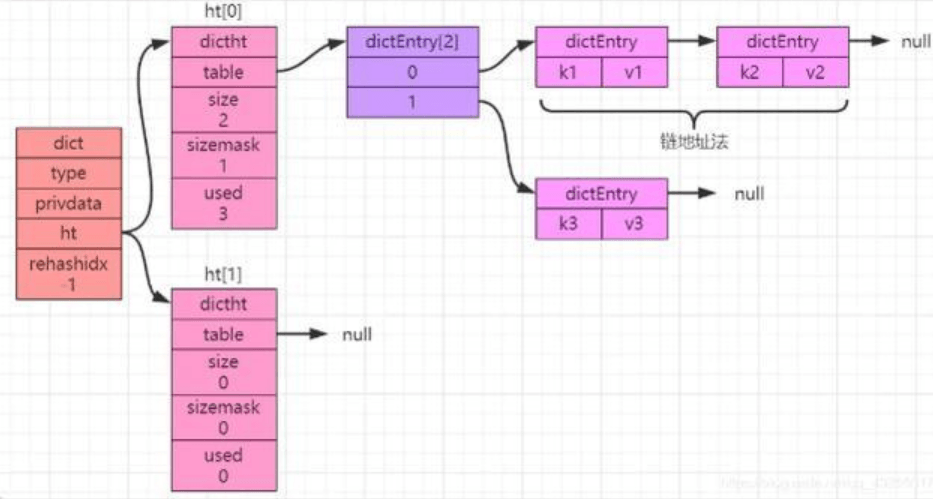
hash 冲突
假如 hashtable 中不同的 key 通过计算得到同一个 index,就会形成单向链表(链地址法),如下图所示:
rehash
在字典的底层实现中,value 对象(ht[0] 用来最开始存储数据的 和 ht[1])以每一个dictEntry的对象进行存储,当 hash 表中的存放的键值对不断的增加或者减少时,需要对 hash表进行一个扩展或者收缩。
- 扩展操作:ht[1] 扩展的大小是比当前 ht[0].used 值的二倍大的第一个 2 的整数幂;
- 收缩操作:ht[0].used 的第一个大于等于的 2 的整数幂。
ht[0] 是存放数据的 table,作为非扩容时容器。ht[1] 只有正在进行扩容时才会使用,它也是存放数据的 table,长度为ht[0]的两倍。当 ht[0] 上的所有的键值对都 rehash 到 ht[1] 中,会重新计算所有的数组下标值,当数据迁移完后ht[0]就会被释放,然后将ht[1]改为ht[0],并新创建 ht[1],为下一次的扩展和收缩做准备。
渐进式 rehash
如果 hash 结构很大,一次完整 rehash 的过程就会耗时很长。采用了渐进式 rehash ,它会同时保留两个新旧 hash 结构,在后续的定时任务以及 hash 结构的读写指令中将旧结构的元素逐渐迁移到新的结构中。这样就可以避免因扩容导致的线程卡顿现象。如果这时有其他线程进行读操作,会先去 ht[0] 中找,找不到再去 ht[1] 中找。如果进行写操作,会直接写在 ht[1] 中。
Set 集合
Redis 中列表和集合都可以用来存储字符串,但是 Set 是不可重复的集合,而 List 列表可以存储相同的字符串。Set 的底层实现是 HashTable 和 intset。
Set 常用操作
SADD key member [member ...] # 往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member ...] # 从集合key中删除元素
SMEMBERS key # 获取集合key中所有元素
SISMEMBER key member # 判断member元素是否存在于集合key中
SRANDMEMBER key [count] # 从集合key中选出count个元素 元素不从key中删除
SPOP key [count] # 从集合key中选出count个元素 元素从key中删除Set 运算操作
SINTER key [key ...] # 交集运算
SINTERSTORE destination key [key ...] # 将交集结果存入新集合destination中
SUNION key [key ...] # 并集运算
SUNION destination key [key ...] # 将并集结果存入新集合destination中
SDIFF key [key ...] # 差集运算
SDIFFSTORE destination key [key ...] # 将差集结果存入新集合destinationZSet 有序集合
ZSet 常用操作
ZADD key score member [[score member] ...] # 往有序集合key中加入带分值元素
ZREM key member [member ...] # 从有序集合key中删除元素
ZScore key member # 返回有序集合key中元素member的分值
ZINCRBY key increment member # 为有序集合key中元素member的分值加上increment
ZCARD key # 返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] # 正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE start stop [WITHSCORES] # 倒序获取有序集合key从start下标到stop下标的元素ZSet 运算操作
ZUNIONSTORE destkey numkeys key [key ...] # 并集计算 destkey: 新生成集合 numkeys:后面所有key的集合数量
ZINTERSTORE destkey numkeys key [key ...] # 交集计算编码选择
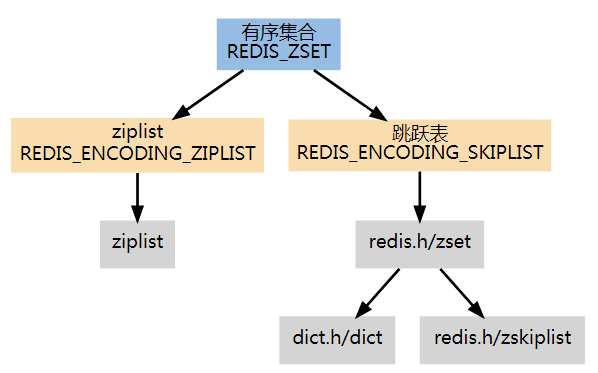
在通过 ZADD 命令添加第一个元素时, 通过检查输入的第一个元素来决定该创建什么编码的有序集。如果第一个元素符合以下条件的话, 就创建一个 REDIS_ENCODING_ZIPLIST 编码的有序集:
- 服务器属性
server.zset_max_ziplist_entries的值大于0(默认为128)。 - 元素的
member长度小于服务器属性server.zset_max_ziplist_value的值(默认为64)。
否则,程序就创建一个 REDIS_ENCODING_SKIPLIST 编码的有序集。
ziplist
ziplist(压缩列表)是一组连续内存块组成的顺序的数据结构,能够节省空间(所以称为压缩列表)。压缩列表中使用多个节点来存储数据。结构图如下:
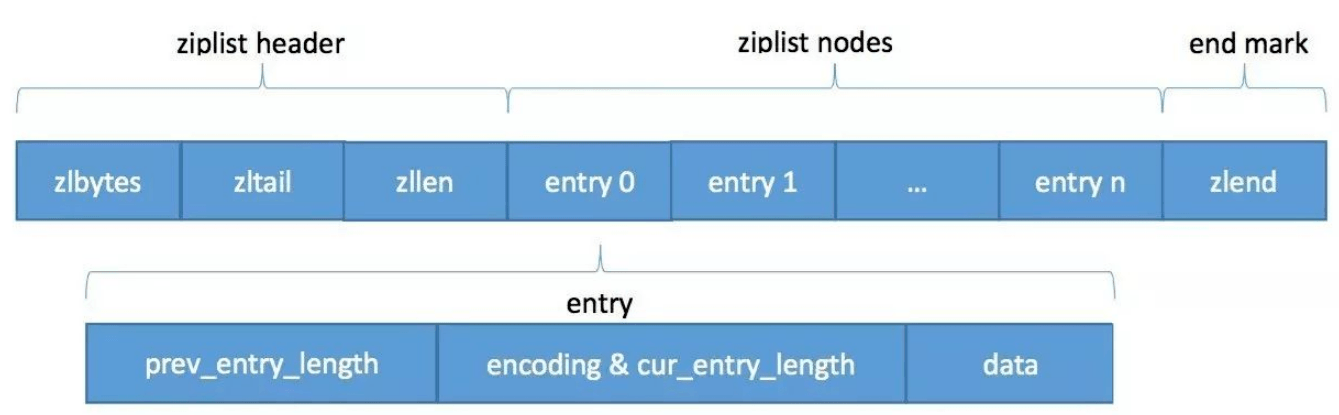
- zlbytes: 四个字节。用于存储压缩列表所占用的字节。当重新分配内存的时候使用,不需要遍历整个列表来计算内存大小。
- zltail: 四个字节。表示 ziplist 表中最后一个 entry 在 ziplist 中的偏移字节数。不用遍历整个 ziplist 也可以很方便地找到最后一个 entry ,从而可以在 ziplist 尾端快速地执行 push 或 pop 操作。
- zllen: 两个字节。表示 ziplist 中数据项 entry 的个数。
- entry:表示真正存放数据的数据项,长度不定。一个数据项 entry 也有它自己的内部结构。
- zlend, ziplist 最后1个字节,值固定等于 255,是一个结束标记。
- previous length(pre_entry_length): 表示前一个数据节点占用的总字节数,这个字段的用处是为了让 ziplist 能够从后向前遍历。
- encoding(encoding&cur_entry_length):表示当前数据节点 content 的内容类型以及长度。
- content(data):表示当前节点存储的数据。
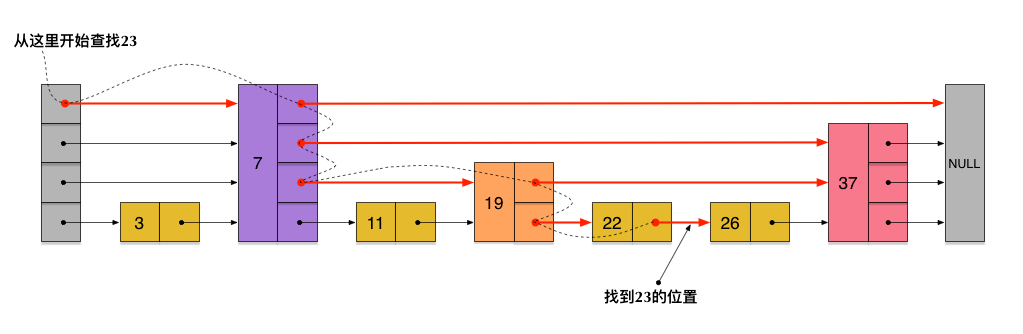
skiplist
skiplist也叫做跳跃表,跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。跳跃列表保存一个有序排列的链表,通过采用多层存储且保持每一层链表是其上一层链表的自己,从最稀疏的层开始搜索,从而达到比链表O(N)更优的查找和插入性能O(log(N))。
(1)查找路径:
(2)插入操作:
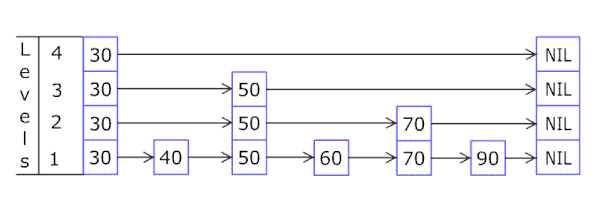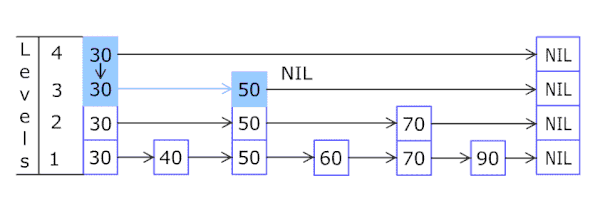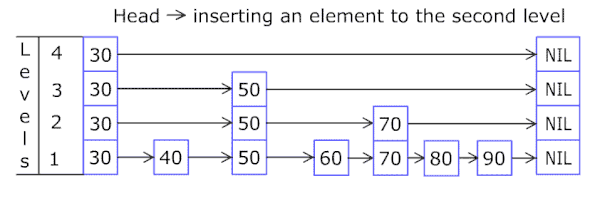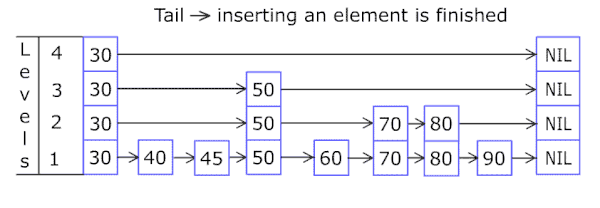
- 新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
- 把索引插入到原链表。O(1)
- 利用抛硬币(coin flip)的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
总体上,跳跃表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,即空间复杂度是 O(N)。
(3)删除操作
- 自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
- 删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
总体上,跳跃表删除操作的时间复杂度是O(logN)。






 关于 LearnKu
关于 LearnKu




推荐文章: