
求优化排列组合算法(付红包)
需求:
我手里有个菜品库,分类有主食、肉类、汤类、蔬菜类。
每个菜有各自的每1克的能量、碳水化合物、脂肪、蛋白质含量。
要求:
1、早餐对这4个分类的菜进行组合,每个分类的菜只能选择一个
2、选取4个分类的菜后,进行能量、碳水化合物、脂肪、蛋白质含量的分配
3、要求4个菜的能量、碳水化合物、脂肪、蛋白质含量各自的和相加,不超过各自的最小值和最大值。
这里注意,最小和最大的增长有一个步长。比如鸡蛋,不可能只吃1g。min(5)~max(20),step可能是5。5、10、15、20这样,食物要有完整性
我的方案:
1、写一个while循环
2、rand随机根据分类取一条菜品,将4个菜先放到数组里
3、然后循环这4个菜品,在随机给他们分配克重
4、对4个菜品进行能量、碳水化合物、脂肪、蛋白质含量的累加,然后对比各自的最小值和最大值。
5、如果4个菜的能量、碳脂蛋在范围内,则结束while循环。
缺点:
1、循环次数过大,需要无限次的匹配才能找到
2、菜品库的数据量不够多的时候,很有可能匹配不出来
希望:
有没有大哥有其他什么方案的,能够快速找到:
1、优化算法,或者借助其他什么工具、组建
2、能不能提前知道库中的的所有菜品的组合是否可以配出合适的菜品
奖励
如果有最佳答案,我会附上200元红包。
提供方案要求
1、写出文字步骤
2、更详细的代码可以飞书文档或者learnku写一个博文@我
3、数据可以自行模拟
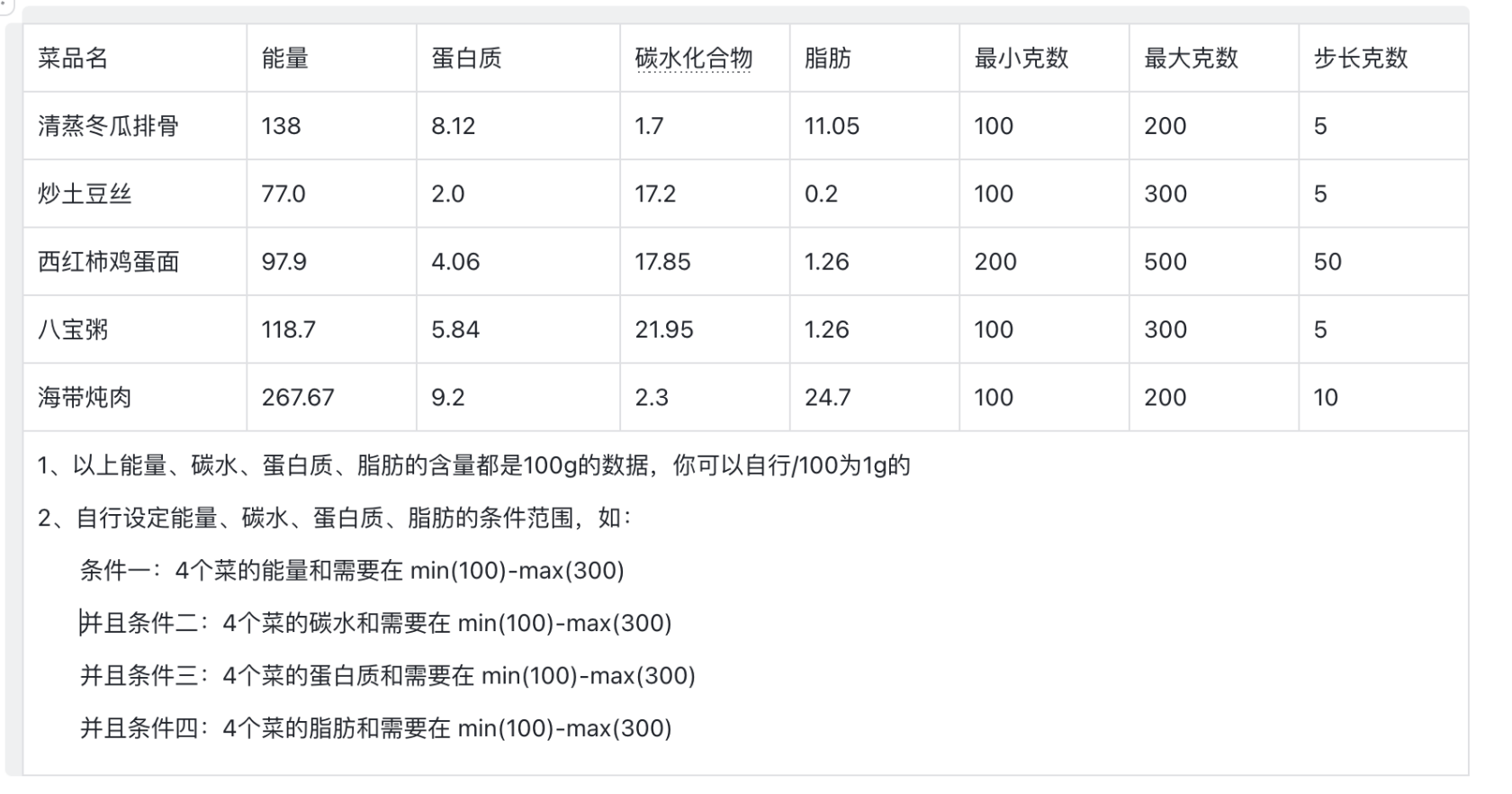
示例数据






















 关于 LearnKu
关于 LearnKu




推荐文章: