
机器学习基础(二)
4 / 0 / 创建于 5年前 /
 calong 的个人博客
calong 的个人博客
标准方程法
求解代价函数的方式不止梯度下降法一种,而且梯度下降法需要选择合适的学习率,需要迭代很多个周期,只能找到最优解的近似值,而标准方程法不需要迭代,不需要选择学习率,可以得到全局最优解,但有一点,标准方程法的样本数量必须大于数据特征数量。
特征缩放法
- 数据归一化:当样本的多个数据特征之间数量级相差较大时,可以把数据归一化(将取值范围处理为0-1或者-1-1之间)
- 均值标准化:


交叉验证法
将数据等分成n份,分别编号为0…n,第一次训练取0…(n-1)为训练集,n为测试集;第二次训练取0…(n-2)和n为训练集,n-1为测试集,依次迭代训练。
设有m个训练样本,每个样本有n个数据特征
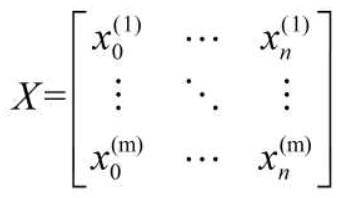
设Y为样本输出值

设拟合函数为: h(x) = θ0 * x0 + θ1 * x1 …. + θn * xn ( 其中x0 = 1)
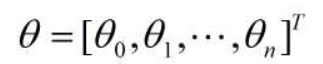
采用均方误差定好代价函数
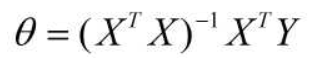
证明过程
- 化简过程
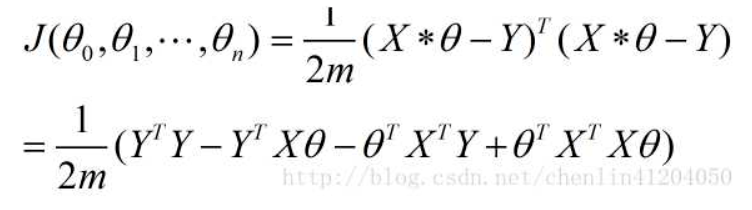
- 求导
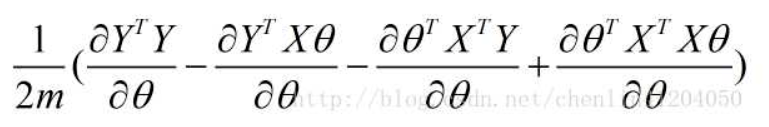
- 第一项:
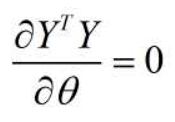
- 第二项:
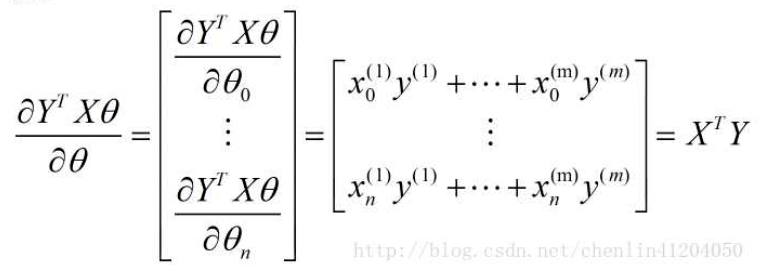
- 第三项:
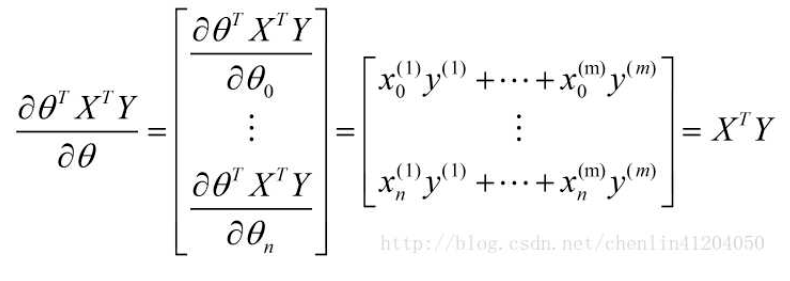
- 第四项:
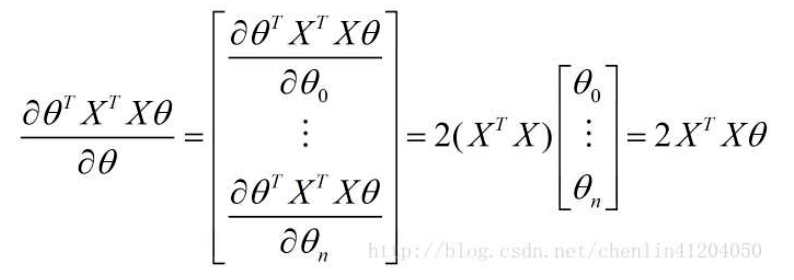
- 结果:

过拟合和正则化
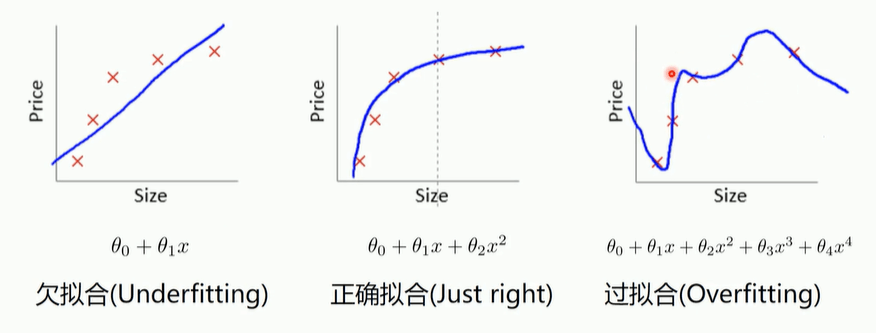
避免过拟合的方法:
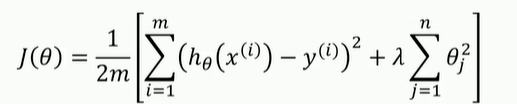
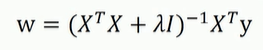
import numpy as np
import matplotlib.pyplot as plt
from numpy import genfromtxt
from sklearn import linear_model
# 读取数据
data = genfromtxt(r'E:/project/python/data/csv/longley.csv', delimiter=',')
x_data = data[1:, 2:]
y_data = data[1:, 1]
alphas_to_test = np.linspace(0.001, 1)
model = linear_model.RidgeCV(alphas=alphas_to_test, store_cv_values=True)
model.fit(x_data, y_data)
# 岭系数
print(model.alpha_)
# 画图
plt.plot(alphas_to_test, model.cv_values_.mean(axis=0))
plt.plot(model.alpha_, min(model.cv_values_.mean(axis=0)), 'ro')
plt.show()
# 打印结果
0.40875510204081633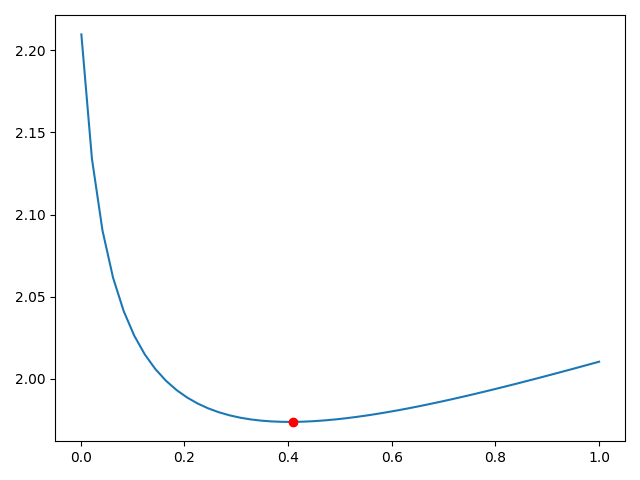
LASSO函数
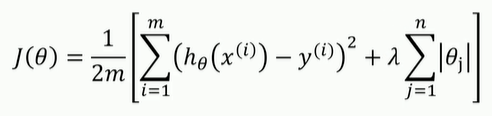
from numpy import genfromtxt
from sklearn import linear_model
# 读取数据
data = genfromtxt(r'E:/project/python/data/csv/longley.csv', delimiter=',')
x_data = data[1:, 2:]
y_data = data[1:, 1]
model = linear_model.LassoCV()
model.fit(x_data, y_data)
# LASSO系数
print(model.alpha_)
# 相关系数
print(model.coef_)
# 打印结果
14.134043936116361
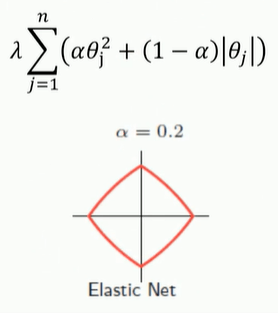
[0.10093575 0.00586331 0.00599214 0. 0. 0. ]弹性网:结合岭回归和LASSO函数
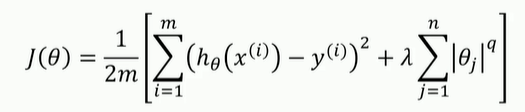
修改的正则部分:
from numpy import genfromtxt
from sklearn import linear_model
# 读取数据
data = genfromtxt(r'E:/project/python/data/csv/longley.csv', delimiter=',')
x_data = data[1:, 2:]
y_data = data[1:, 1]
model = linear_model.ElasticNetCV()
model.fit(x_data, y_data)
# LASSO系数
print(model.alpha_)
# 相关系数
print(model.coef_)
# 打印结果
30.31094405430269
[0.1006612 0.00589596 0.00593021 0. 0. 0. ]多项式回归
无论是一元线性回归还是多元线性回归,他们都只能拟合近似直线或单一平面的数据,而多项式回归可以拟合更加复杂的函数变化
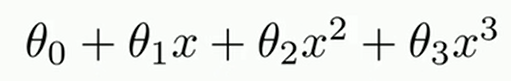
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
data = np.genfromtxt(r'E:/project/python/data/csv/job.csv', delimiter=',')
x_data = data[1:, 1, np.newaxis]
y_data = data[1:, 2, np.newaxis]
# 定义多项式回归
ploy_reg = PolynomialFeatures(degree=5)
# 特征处理
x_ploy = ploy_reg.fit_transform(x_data)
lin_reg = LinearRegression()
lin_reg.fit(x_ploy, y_data)
# 画图
plt.plot(x_data, y_data, 'b.')
plt.plot(x_data, lin_reg.predict(ploy_reg.transform(x_data)), c='r')
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()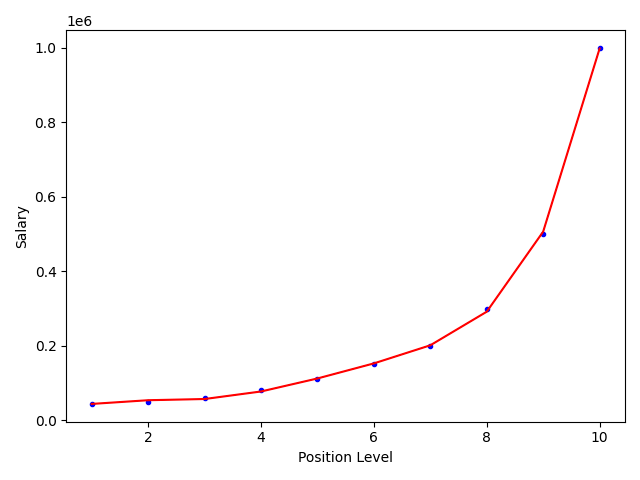
degree的理解:degree为公式中x的系数,模型通过改变x的值来确定最适合的θ,当函数关系比较复杂时,一次幂函数无论如何都无法进行最适合的拟合,所以通过改变x的系数来创建更加复杂的高次幂函数
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: