
mysql 笔记
0 / 0 / 创建于 5年前 /
 howtouse 的个人博客
howtouse 的个人博客
1.mysql逻辑架构图
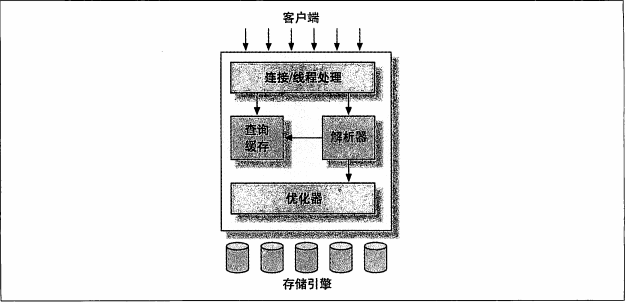
a.第一层:连接处理,授权认证,安全等
b.第二层:核心服务层(服务器层)
- 查询解析、分析、优化、缓存
- 内置函数(日期、时间、数学和加密函数)
- 存储过程、触发器、试图
c.第三层:存储引擎层,负责mysql中数据的存储和提取
2.在事务中使用混合存储引擎
a.mysql的服务器层不管理事务,事务是由下层的存储引擎实现的
b.在同一个事务中,使用多种存储引擎是不可靠的
c.回滚时,非事务型的表上无法撤销,会导致数据库处于不一致的状态,事务的最终结果将无法确定。
3.MVCC
a.实现:通过保存数据在某个时间点的快照实现。
b.不管需要执行多长时间,每个事务看到的数据都是一致的。
c.根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
d.不同存储引擎的MVCC实现是不同的,有乐观(optimistic)和悲观(pessimistic)并发控制。
4.InnoDB的MVCC
a.通过在每行记录后边保存两个隐藏的列来实现。
b.一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。(存储的并不是实际的时间值,而是系统版本号)
c.每开始一个新的事务,系统版本号都会自动递增。
d.MVCC只在REPEATABLE READ(可重复读)和READ COMMITTED(提交读)这两个隔离级别下工作。
5.表的定义
a.在文件系统中,mysql将每个数据库保存为数据目录下的一个子目录。
b.创建表时,mysql会在数据库子目录下创建一个和表同名的.frm文件保存表的定义。
c.表的定义,在mysql的服务层统一处理。
d.innodb会同时创建 .ibd文件。
e.myisam会将表存储在两个文件中:数据文件和索引文件,分别以.MYD和.MYI为扩展名。
6.查询执行路径
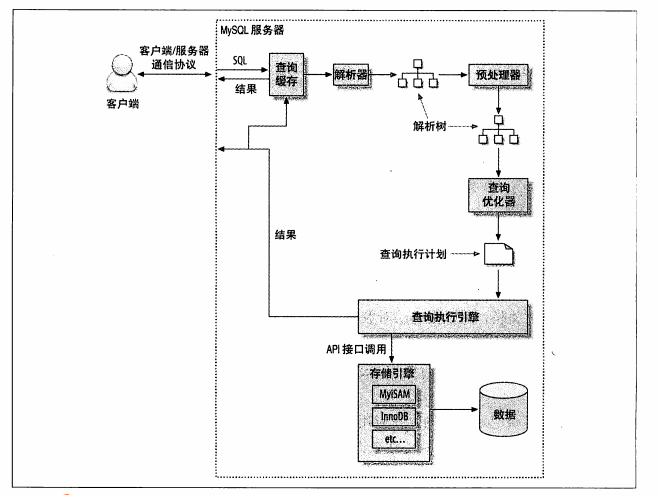
a.客户端发送一条查询给服务器。
b.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
c.服务器端执行SQL解析、预处理,再由优化器生成对应的执行计划。
d.MYSQL根据优化器生成的执行计划,调用存储引擎的api来执行查询。
e.将结果返回给客户端。
7.count()
a.作用:(1)统计某个列值的数量,也可统计行数。统计列值时,要求列值非空。
(2)统计结果集的行数,最简单就是使用count()。(此情况的通配符并不会像我们猜想的那样扩展成所有的列,实际上它会忽略所有的列而直接统计所有的行数)
b.例子:通过一个查询返回各种不同颜色的商品数量:
mysql>select count(color='blue' or null) as blue,count(color='red' or null) as red from items;本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: