
mysql数据库其中一列为null,他会有什么坑
1 / 1 / 创建于 3年前
 my38778570 的个人博客
my38778570 的个人博客
1. count 数据丢失
当某列存在 NULL 值时,再使用 count 查询该列,就会出现数据“丢失”问题,如下 SQL 所示:
select count(*),count(name) from person;查询执行结果如下:
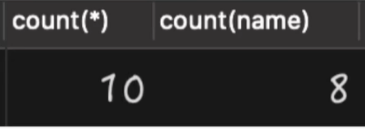
从上述结果可以看出,当使用的是 count(name) 查询时,就丢失了两条值为 NULL 的数据丢失
解决方案
如果某列存在 NULL 值时,就是用 count(*)或者 count(id) 进行数据统计。
2.distinct 数据丢失
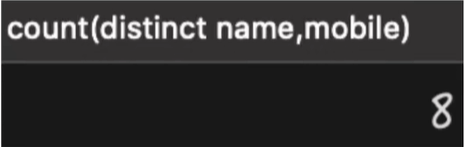
当使用 count(distinct co11,co2) 查询时,如果其中一列为 NULL,那么即使另一列有不同的值,那么查询的结果也会将数据丢失,如下 SQL 所示:
select count(distinct name ,mobile) from person;查询执行结果如下:
3.select 数据丢失
如果某列存在 ULL 值时,如果执行非等于查询 (<>/!=)会导致为 NULL 值的结果丢失
select * from person where name<>'php' order by id;
--或
select * from person where name!='php' order by id;4.导致空指针异常
如果某列存在 NULL 值时,可能会导致 sum(column)的返回结果为 NULL 而非0,如果 sum 查询的结果为NULL 就可以能会导致程序执行时空指针异常
接下来我们使用 sum 查询,执行以下SQL
select sum(num) from goods where id>4;解决空指针异常
可以使用以下方式来避免空指针异常
select ifnull(sum(num),0) from goods where id>4;5. 增加了查询难度
当某列值中有 NULL 值时,在进 NULL 值或者非 NULL 值的查询难度就增加了
所谓的查询难度增加指的是当进行 ULL 值查询时,必须使用 NULL 值匹配的查询方法,比如 S NULL 或者SNOT NULL 又或者是 IFNULL(cloumn) 这样的表达式进行查询,而传统的 =、!=<>..等这些表达式就不能使用了,这就增加了查询的难度,尤其是对小白程序员来说
错误用法 1:
select * from person where name<>null;错误用法 2:
select * from person where name!=null;正确用法 1:
select * from person where name is not null;正确用法2:
select * from person where !isnull(name);推荐用法
阿里巴巴《Java开发手册》推荐我们使用 ISNULL(cloumn)来判断 NULL 值,原因是在 SOL 语句中,如果在null 前换行,影响可读性;而 ISNULL(column)是一个整体,简洁易懂。从性能数据上分析 ISNULL(column)执行效率也更快一些。
扩展知识: NULL不会影响索引
本作品采用《CC 协议》,转载必须注明作者和本文链接












 关于 LearnKu
关于 LearnKu




推荐文章: