
一次[用户在线API]的优化思路和历程
8 / 0 / 创建于 3年前
 雷雷 的个人博客
雷雷 的个人博客
一、产品要求
- 最多展示10个用户,优先展示当前学生自己的头像,顺序是用户在线时间倒排。
- 显示当前在线人数和累计学习人数。
二、技术方案
目前思路是通过两个接口来实现上面逻辑:
- 用户在线状态上报:通过用户学习进度上报接口来更新用户在线状态。主要动作是上线,学习,下线。【由于存在用户直接杀死APP的可能性,故每次上报设置用户在线状态为5分钟】
- 用户在线数据获取:通过APP端30s轮询一次完成拉取在线数据的,后台数据通过Redis读取和计算数据。
2.1、当前Api接口性能
上线之后通过监测发现,当前接口平均耗时在0.11秒左右但是用户访问次数比较,最大耗时可达到2.6秒。
2.2、Redis数据读取分析
目前通过Redis设计了三个key,分别是
- 课程学习人数Key :
course_study_num_key:course_id=%s - 用户当前课程在是否学过Key:
course_user_study_key:course_id=%s:user_id=%s - 课程下用户ID和用户分数Key:
course_user_online_key:course_id=%s
前两个使用string类型,第三个key使用Zset类型(Redis数据接口为跳跃表(Skip List))
| key | 命令 | 场景 | 时间复杂度 |
|---|---|---|---|
| course_study_num_key:course_id=%s | incr decr get |
课节学习人数增减 | O(1) |
| course_user_study_key:course_id=%s:user_id=%s | set get |
用户当前课节在是否学过 | O(1) |
| course_user_online_key:course_id=%s | zadd | 添加/更新成员的分数 | 在跳跃表实现中为 O(log N) |
| course_user_online_key:course_id=%s | zscore | 获取当前用户分数 | O(1) |
| course_user_online_key:course_id=%s | zcount | 获取在线人数 | 跳跃表(Skip List)时间复杂度为 O(log N + M),其中 N 是有序集合的基数(即成员数量),M 是返回的成员数量。 |
| course_user_online_key:course_id=%s | zrevrangebyscore | 获取有序集合中分数最高的10个成员及其分数 | 跳跃表(Skip List)时间复杂度为 O(log N + M),其中 N 是有序集合的基数(即成员数量),M 是返回的成员数量。 |
通过上诉表格我们可以得出以下结论:
- “课程学习人数Key”和“用户当前课程在是否学过Key”的读取时间复杂度为O(1),因此它们的性能较好,不需要进行优化。
- “课程下用户ID和用户分数Key”使用Zset类型数据,而“获取在线人数”和“获取分数最高的10个成员及其分数”的读取时间复杂度为O(log N + M)。N是Zset的基数,基数越大越影响数据性能,因此我们需要优化Zset表中数据的数量,以减少N的值。
2.3、优化思路
- 通过脚本定时清除下线用户数据,减少Zset的基数。
- 获取在线人数增加缓冲机制,避免频繁使用zcount函数。
2.4 、清除下线用户逻辑
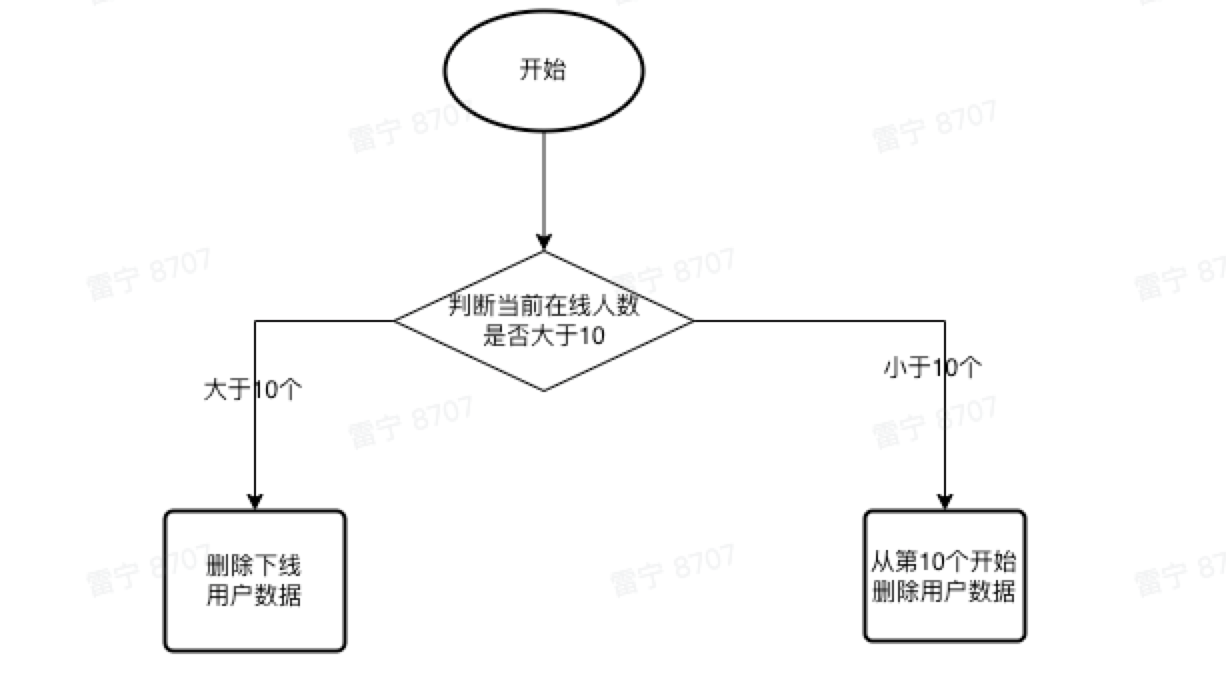
2.4.1、清除下线用户代码
/**
* 获取在线人数
* 大于10
* 删除已下线用户
* 不于10
* 删除10之后用户
*/
$redis_key = sprintf($this->_UserOnlineKey, $courseId);
$online_count = (int)Redis::zcount($redis_key, time(), '+inf');
if ($online_count > 10) {
// 删除已下线用户
return (int)Redis::zremrangebyscore($redis_key, '-inf', '(' . time());
}
return (int)Redis::zremrangebyrank($redis_key, 12, -1);三、总结
总之,我的思路是针对Zset类型的优化思路主要是减少Zset中数据的数量,降低Zset的基数,从而提高“获取在线人数”和“获取分数最高的10个成员及其分数”的读取效率。
大家有什么好的想法也可以一起聊聊。
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: