
mysql 的 子查询
0 / 13 / 创建于 2年前 /
 凌晨三点半的卢本伟 的个人博客
凌晨三点半的卢本伟 的个人博客
最近在学子查询,发现有一个题目如下
要求查询出两门及两门以上不及格者的平均成绩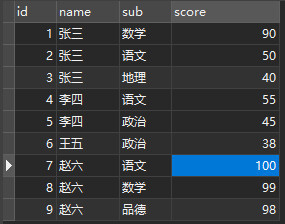
第一想法就是
先查询出 成绩 小于60 的所有人 再进行子查询
SELECT `name`,avg(score) FROM score WHERE `name` IN ( SELECT `name` FROM score WHERE score < 60 GROUP BY `name` HAVING COUNT(name) >= 2 ) GROUP BY name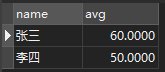
再想想,好像有点复杂了。
2.第二次,想能不能把不及格的成绩统计起来,再进行筛选
SELECT `name`,AVG(score)avg,SUM(IF(score<60,1,0)) c FROM score GROUP BY `name` HAVING c >= 2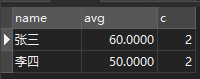
看了答案跟我的第二种是一样的
SELECT `name`,AVG(score) avg,SUM(score<60) c FROM score GROUP BY `name` HAVING c >= 2提问:有没有更简单 或者更复杂的sql提供参考。或者大佬们提供相关的sql子查询题讨论讨论,谢谢。
#############################分割线###################################
更新 2023-8-21 晚10点30分
学习到新的知识 关于FROM,EXISTS,SELF JOIN 子查询
1.FROM 型子查询,其中这么说,可以把查询出来的数据集当成一个临时表,把列看成变量
SELECT `name`,avg FROM
( SELECT `name`,AVG(score) avg,SUM(score<60) s FROM score GROUP BY `name` ) tmp
WHERE s >= 22.EXISTS 型 子查询 ,其实不太理解,为什么EXISTS里面的 可以用 * 来查所有数据
SELECT name,AVG( score ) FROM `score` s1
WHERE EXISTS
( SELECT * FROM score s2 WHERE s1.name = s2.name GROUP BY `name` HAVING SUM( score<60 ) >=2 ) GROUP BY `name`2.SELF JOIN 自连接
SELECT s1.name,AVG(s1.score) FROM score s1
LEFT JOIN score s2 ON s1.`id` = s2.`id`
GROUP BY s1.`name`
HAVING SUM( s2.score < 60 ) >= 2新表 user 数据如下 ,查询出数据用户,及用户上级用户信息(再关联其他表),按以前做法就是查询出所有数据再递归循环,现在一条sql就解决了。
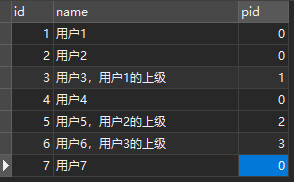
SELECT u1.*,u2.name u2_name,u2.pid u2_pid FROM `user` u1
LEFT JOIN `user` u2 ON u1.id = u2.pid查询过后的结果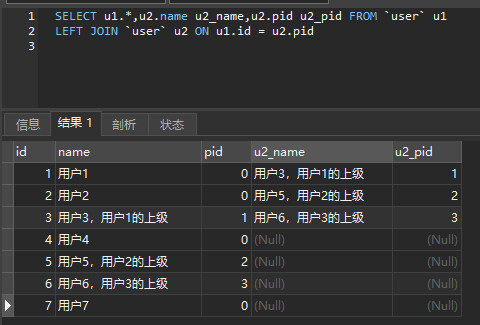
本作品采用《CC 协议》,转载必须注明作者和本文链接






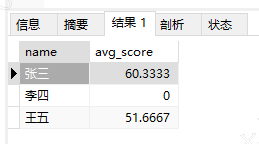


 这是gpt给的答案,没测试过
这是gpt给的答案,没测试过




 关于 LearnKu
关于 LearnKu




推荐文章: