

075. Eloquent 模型多表模糊搜索——nicolaslopezj/searchable
Eloquent 模型多表模糊搜索—— nicolaslopezj/searchable
搜索一直是非常重要的功能,我们会通过各种方法来处理数据的查询,前面的课程中介绍过一个关于搜索的扩展包——007. Eloquent 条件查询——tucker-eric/eloque... 用于处理多条件查询,今天介绍的这个扩展包 nicolaslopezj/searchable,可以帮助我们处理模糊搜索,它非常的简单,只提供了一个 Trait,通过定义一些模型属性就可以快速完成多个表之间的模糊搜索。
还是以 Larabbs 为例,项目结构很简单,有话题 Topic ,分类 Category,用户 User 等,例如现在增加了一个搜索的功能,传入一个查询参数,模糊搜索话题的标题、内容、分类名称、用户名称、用户邮箱等条件,只要上述条件有一个匹配,就把对应的话题查询出来。
不使用扩展包
我们可以先来试试不使用扩展包的情况下,该如何实现。
之前有一个对应的接口 api/topics,显示话题类表,尝试增加一个 keyword 参数,模糊匹配一些数据。
app/Http/Controllers/Api/TopicsController.php
.
.
.
public function index(Request $request, Topic $topic)
{
$topics = $topic->where(function($query) use ($request) {
$query->where('title', 'like', '%'.$request->keyword.'%')
->orWhere('body', 'like', '%'.$request->keyword.'%')
->orWhereHas('user', function($query) use ($request){
$query->where('name', 'like', '%'.$request->keyword.'%');
});
})->paginate(20);
return $this->response->paginator($topics, new TopicTransformer());
}
.
.
.上面实现了三个搜索,话题的标题,内容,以及发帖用户姓名,上述代码有些问题:
- 随着条件的增加,代码会越来越多,越来越复杂;
- 都是模糊搜索,需要根据情况确定是包含这个词,还是匹配开头,或者匹配结尾。
- 搜索到的结果没有权重关系,无法调整某些数据排在前面。
接着试试今天这个扩展包,看看它是否解决了上面这些问题。
安装
$ composer require nicolaslopezj/searchable
使用
扩展包提供了一个 Trait,所以使用起来非常简单,给需要的 Eloquent 模型增加 Trait 就行。
app/Models/Topic.php
.
.
.
use Nicolaslopezj\Searchable\SearchableTrait;
.
.
.
use SearchableTrait;
protected $searchable = [
'columns' => [
'topics.title' => 10,
'topics.body' => 0,
]
];
.
.
.需要定义一个属性 $searchable,columns 就是需要搜索的字段,先定义两个字段,标题和内容,字段的值标识权重,数字越大,匹配到后排在越前面,先定义标题的权重是 10,话题内容的权重是 0。
app/Http/Controllers/Api/TopicsController.php
.
.
.
$topics = $topic
->search($request->keyword)
->filter($request->all())
->paginate(20);
.
.
.修改代码,直接使用 search 方法就行了,省去了很多代码,传入提交过来的 keyword,先来看看效果。
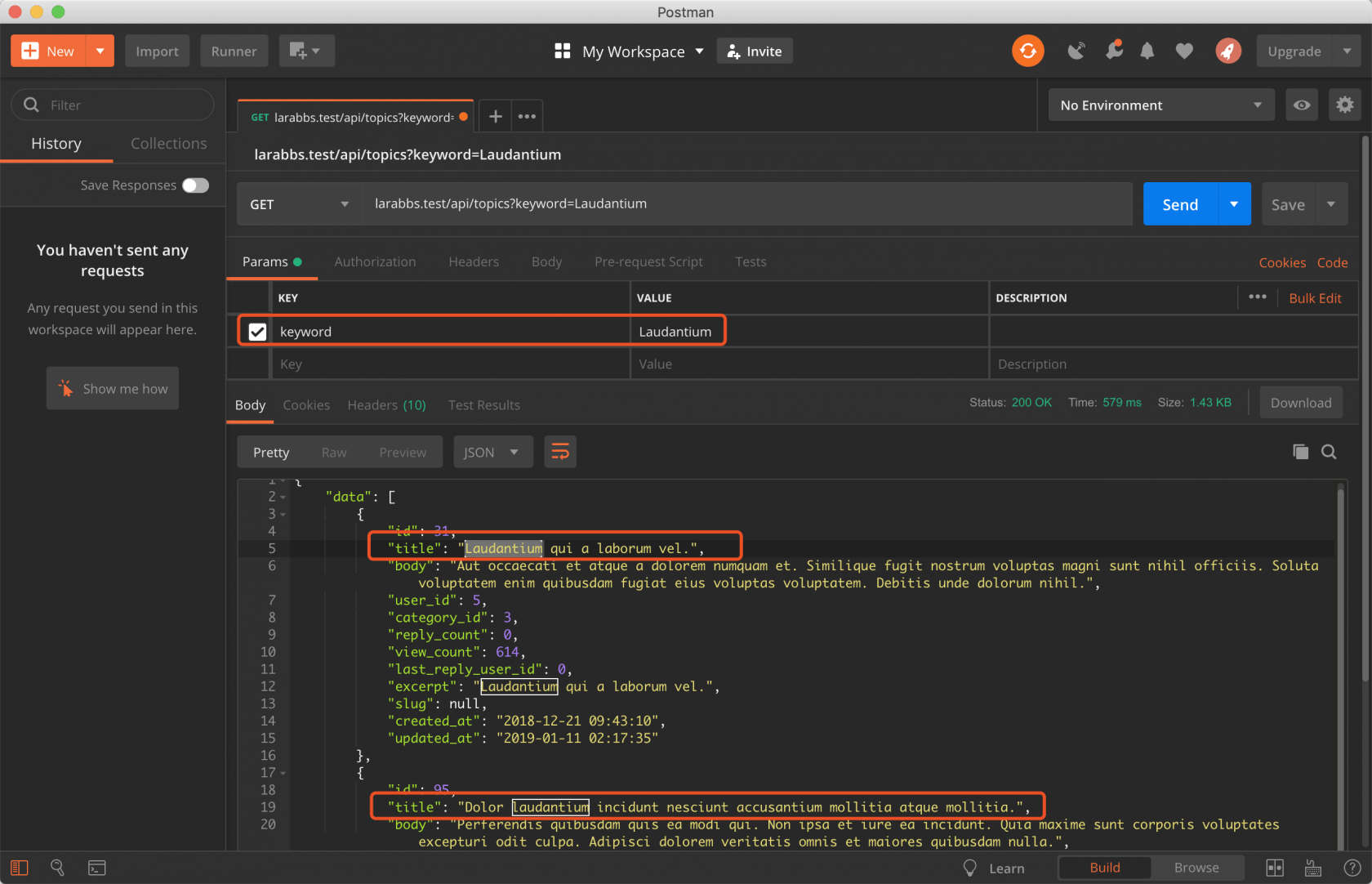
查询出来了正确的数据,查看一下执行的 sql 语句,因为我们安装了 overtrue/laravel-query-logger 扩展包,所以 sql 会打印在日志文件中,可以用一些工具格式化 sql,看的更加清楚,例如 codebeautify.org/sqlformatter 。
select
*
from
(
select
`topics`.*,
max(
(
case when LOWER(`topics`.`title`) LIKE 'laudantium' then 150 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE 'laudantium%' then 50 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE '%laudantium%' then 10 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'laudantium' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'laudantium%' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE '%laudantium%' then 0 else 0 end
)
) as relevance
from
`topics`
where
`topics`.`deleted_at` is null
group by
`topics`.`id`
having
relevance >= 5.00
order by
`relevance` desc
) as `topics`
order by
`updated_at` desc
limit
20 offset 0处理逻辑
扩展包利用了 case when 来对匹配的数据进行打分,我们设置的 topics.title 权重是 10,搜索的关键词是 laudantium,那么:
- 如果标题是 laudantium 增加 150 (15*10);
- 如果标题中以 laudantium 开头那么增加 50 (5*10);
- 如果标题中某个单词包含了 laudantium 那么增加 10 (1*10);
不同的匹配会有不同的得分,注意我们搜索出来的两条结果,第一个满足 2 和 3 ,所有最终是 60 分,第二条满足 3 所以是 10 分。对 body 的评分逻辑一样,一起加起来,就是每条匹配结果的得分,按评分排序且这个评分大于等于 5 也就是所有权重的平均值 (10 + 0)/ 2。
最终得分大于等于平均值的才会显示,如果你想自定义这个得分,可以传入第二个参数
app/Http/Controllers/Api/TopicsController.php
.
.
.
$topics = $topic
->search($request->keyword, 11)
->filter($request->all())
->paginate(20);
.
.
.这样就只会匹配出第一提交记录了,因为第二条的评分只有 10 分。如果传入 0 则所有记录都会显示。
多个单词
下面再来试试多个词组,例如 Laudantium qui 另个词。
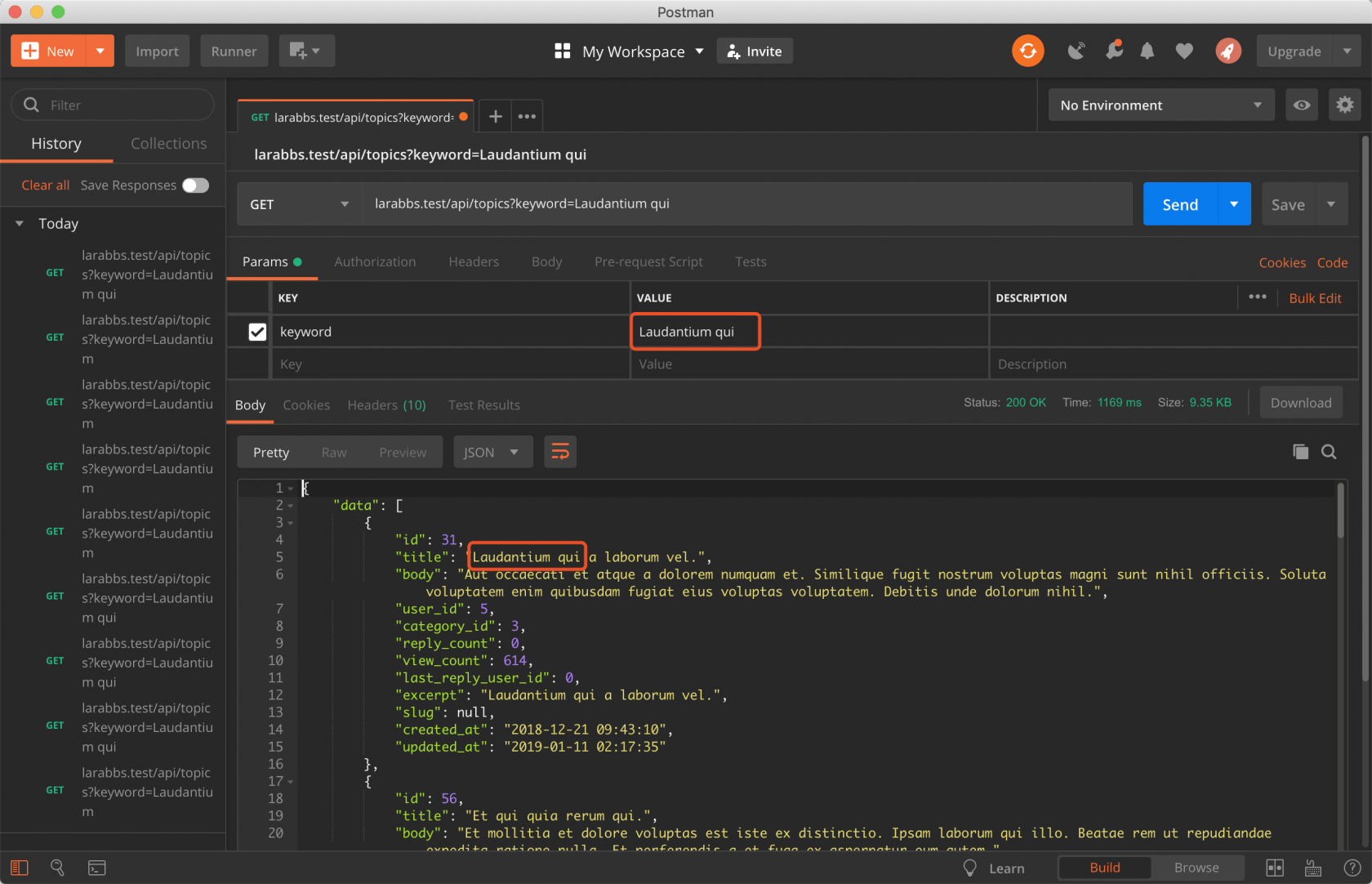
处理逻辑是将词组分开,分别去计算 Laudantium 和 qui 两个词的匹配得分然后加起来,查看一下 sql 语句。
select
*
from
(
select
`topics`.*,
max(
(
case when LOWER(`topics`.`title`) LIKE 'laudantium' then 150 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE 'qui' then 150 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE 'laudantium%' then 50 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE 'qui%' then 50 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE '%laudantium%' then 10 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE '%qui%' then 10 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'laudantium' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'qui' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'laudantium%' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'qui%' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE '%laudantium%' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE '%qui%' then 0 else 0 end
)
) as relevance
from
`topics`
where
`topics`.`deleted_at` is null
group by
`topics`.`id`
having
relevance >= 0.00
order by
`relevance` desc
) as `topics`
order by
`updated_at` desc
limit
20 offset 0但是这样会有一个问题,搜索的两个词是分开后分别查询的,应该是两个词连在一起的时候分数更高,这个时候可以给 search 方法添加第三个参数,第二个参数可以设置为 null, 依然使用权重平均值:
app/Http/Controllers/Api/TopicsController.php
.
.
.
$topics = $topic
->search($request->keyword, null, true)
->filter($request->all())
->paginate(20);
.
.
.这个时候匹配规则就会增加两条:
- 如果标题是
Laudantium qui增加 500 (50*10); - 如果标题中包含
Laudantium qui增加 300 (30*10)。
这样就会将 Laudantium qui 匹配的结果排在前面。
不拆分关键字
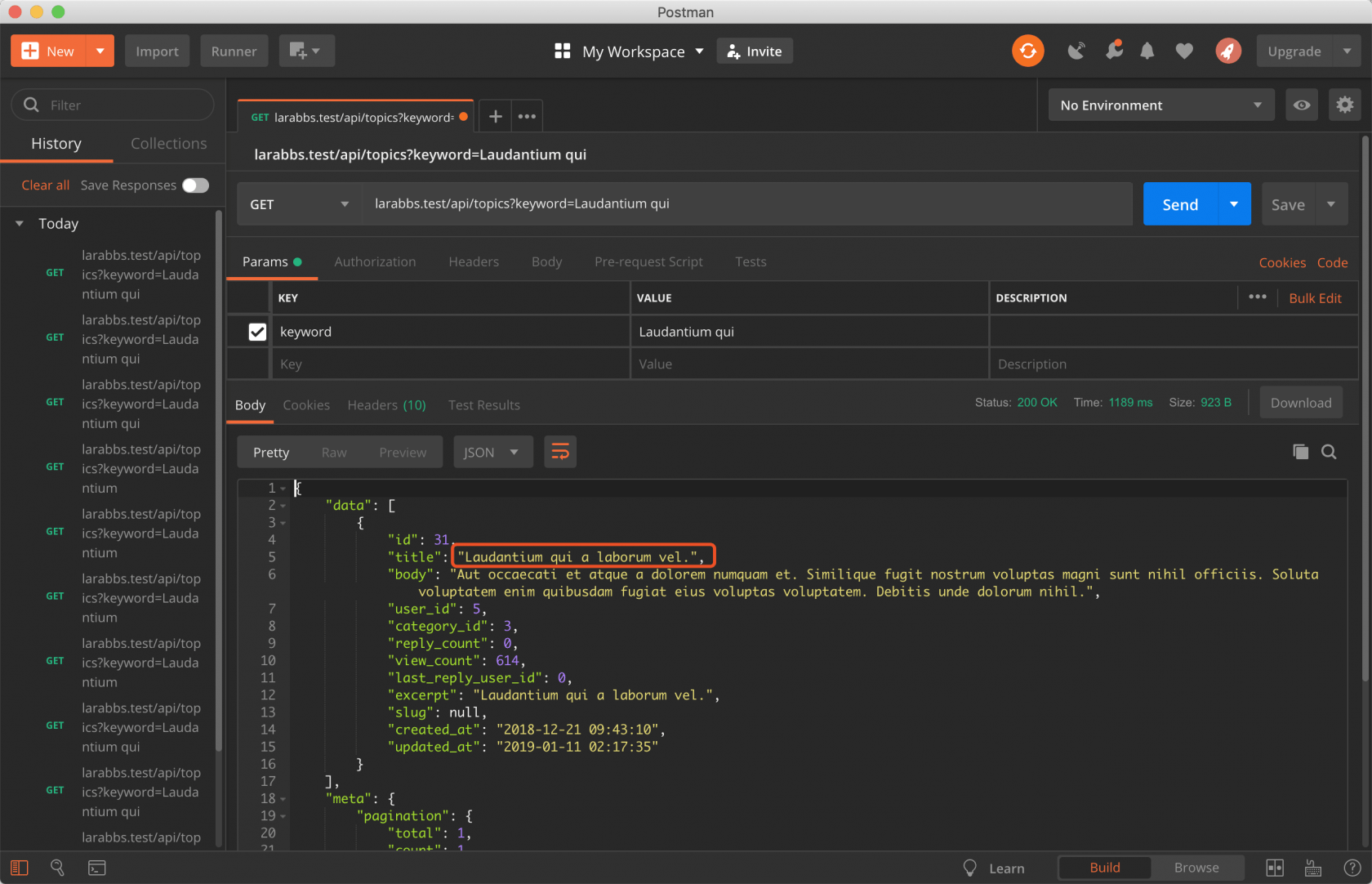
如果只想匹配 Laudantium qui 的结果,不拆分单词进行单独匹配,可以增加第四个参数。
app/Http/Controllers/Api/TopicsController.php
.
.
.
$topics = $topic
->search($request->keyword, null, true, true)
->filter($request->all())
->paginate(20);
.
.
.
补充所有逻辑
上面这些逻辑明白了就可以完成剩下的逻辑了。
app/Models/Topic.php
.
.
.
protected $searchable = [
'columns' => [
'topics.title' => 10,
'topics.body' => 5,
'users.name' => 2,
'users.email' => 2,
'category_translations.name' => 10,
],
'joins' => [
'users' => ['users.id','topics.user_id'],
'categories' => ['categories.id','topics.category_id'],
'category_translations' => ['categories.id','category_translations.category_id'],
],
];
.
.
.注意我调整了每个查询字段的权重。如果要同时查询其他表中的数据,需要自行处理多表之间的 join 关系,需要定义 joins 数组。
由于之前的课程 037. 另一个数据库的多语言翻译方案 ——dimsav... 中将分类的名称放在了另一张表表中,方便进行翻译处理,有兴趣的同学可以回顾一下之前的课程,所以这里需要自行关联 categories 相关的表。
select
*
from
(
select
`topics`.*,
max(
(
case when LOWER(`topics`.`title`) LIKE 'laudantium qui' then 500 else 0 end
) + (
case when LOWER(`topics`.`title`) LIKE '%laudantium qui%' then 300 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE 'laudantium qui' then 0 else 0 end
) + (
case when LOWER(`topics`.`body`) LIKE '%laudantium qui%' then 0 else 0 end
) + (
case when LOWER(`users`.`name`) LIKE 'laudantium qui' then 100 else 0 end
) + (
case when LOWER(`users`.`name`) LIKE '%laudantium qui%' then 60 else 0 end
) + (
case when LOWER(`users`.`email`) LIKE 'laudantium qui' then 50 else 0 end
) + (
case when LOWER(`users`.`email`) LIKE '%laudantium qui%' then 30 else 0 end
) + (
case when LOWER(`category_translations`.`name`) LIKE 'laudantium qui' then 500 else 0 end
) + (
case when LOWER(`category_translations`.`name`) LIKE '%laudantium qui%' then 300 else 0 end
)
) as relevance
from
`topics`
left join `users` on `users`.`id` = `topics`.`user_id`
left join `categories` on `categories`.`id` = `topics`.`category_id`
left join `category_translations` on `categories`.`id` = `category_translations`.`category_id`
where
`topics`.`deleted_at` is null
group by
`topics`.`id`,
`users`.`name`,
`users`.`email`,
`category_translations`.`name`
having
relevance >= 4.60
order by
`relevance` desc
) as `topics`
order by
`updated_at` desc
limit
20 offset 0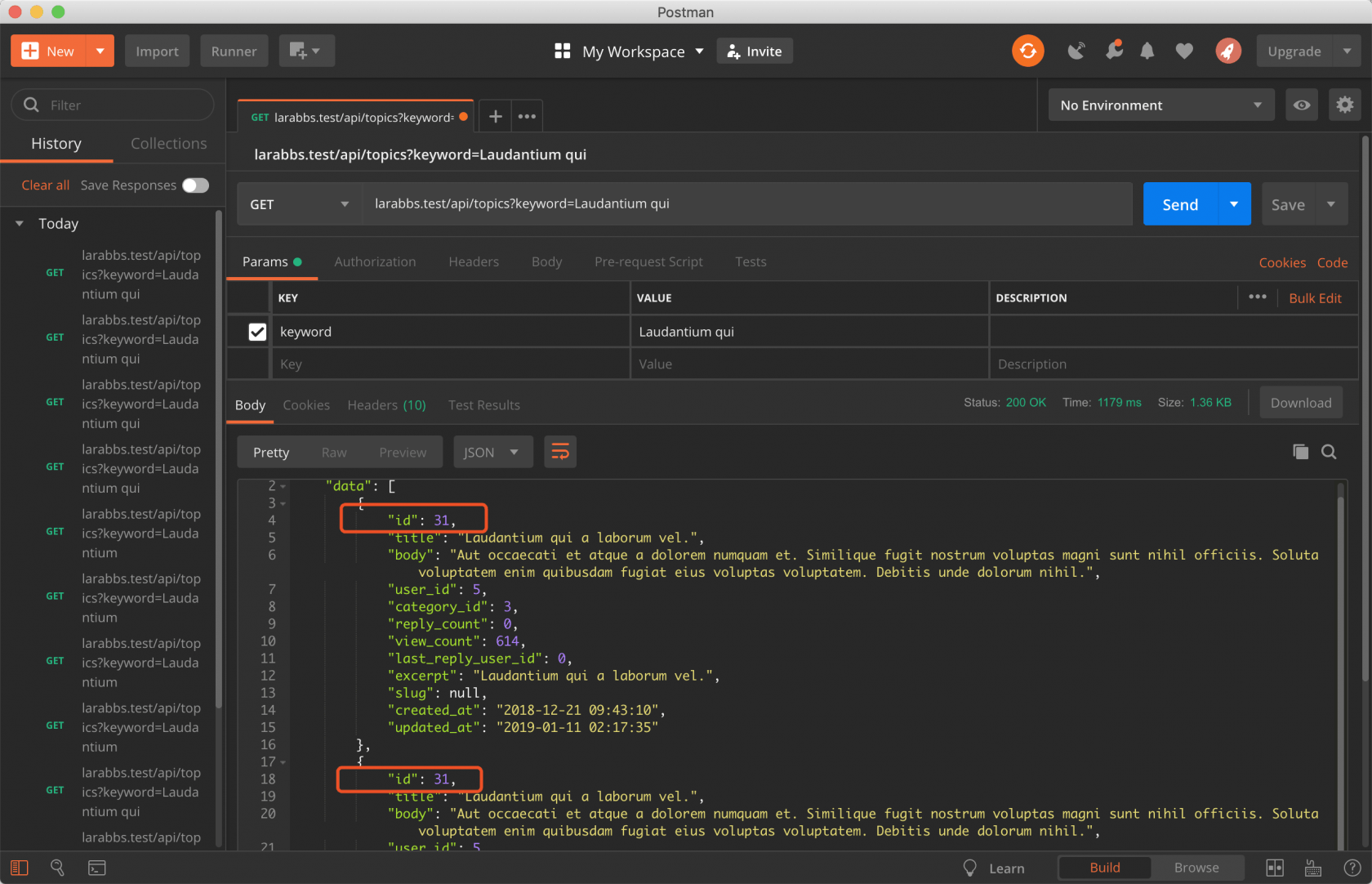
查看一下结果你会发现数据重复了,查看最终执行的 sql ,你会发现最终会根据查询的字段对数据进行 group by,大多数情况下是不会出现问题的,但是我们这里因为 category_translations 中多条记录会对应一个 category 分类,因为会对名称进行多语言的翻译,这就导致 group by 的时候出现的重复。
扩展包已经考虑到了这些问题,默认情况下是根据查询字段进行 group by,但是我们可以手动修改。
app/Models/Topic.php
.
.
.
protected $searchable = [
'columns' => [
'topics.title' => 10,
'topics.body' => 5,
'users.name' => 2,
'users.email' => 2,
'category_translations.name' => 10,
],
'joins' => [
'users' => ['users.id','topics.user_id'],
'categories' => ['categories.id','topics.category_id'],
'category_translations' => ['categories.id','category_translations.category_id'],
],
'groupBy' => [
'topics.id'
]
];
.
.
.定义 groupBy,指定自己的group by 参数,这里可以只指定话题的 id,这样查询就没有问题了。
总结 search 方法参数
- 需要匹配的关键词;
- 评分最低门槛,默认情况下是权重平均值,可自定义,传入 0 会列出所有结果,默认是 null;
- 是否对关键词进行全文匹配, true / false,默认是 false;
- 是否只查询完整的关键词,不进行关键词拆分,true / false,默认是 false。
代码版本控制
$ git add -A
$ git commit -m 'nicolaslopezj/searchable'




 关于 LearnKu
关于 LearnKu



