
 从0开始学AI
从0开始学AIk近邻算法
kNN-k近邻算法(K-Nearest Neighbors)
思想极度简单
应用数学知识少(近乎为零)
效果好
可以解释机器学习算法使用过程中的很多细节问题
更完整的刻画机器学习应用的流程
k-近邻(KNN)算法步骤
计算已知类别数据集中的点与当前点之间的距离(
KNN算法中使用的是欧式距离);按照距离递增次序排序;
选取与当前点距离最小的k个点;
确定前k个点所在类别的出现频率;
返回前k个点所出现频率最高的类别作为当前点的预测分类
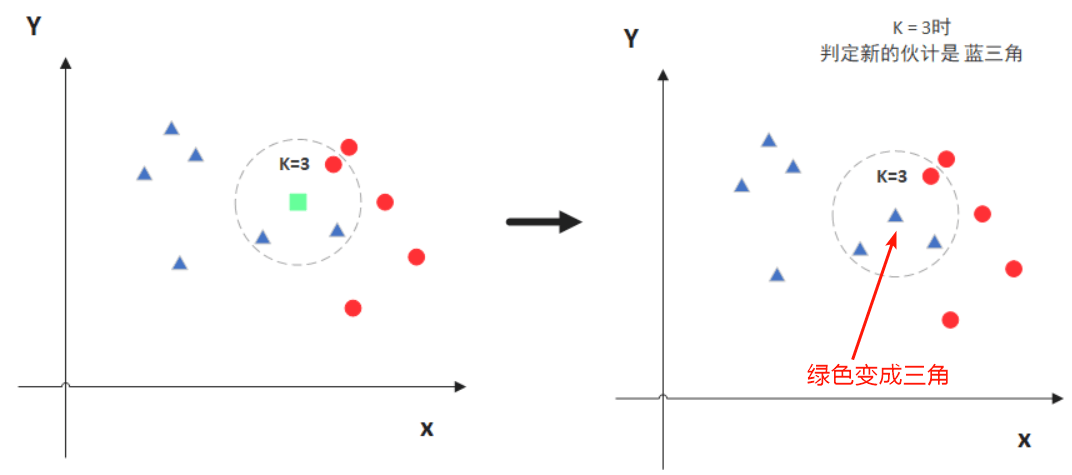
简单来说,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别
KNN算法优点
简单易用,相比其他算法,KNN算是比较简洁明了的算法。
模型训练时间快,KNN是一种非参的,惰性的算法模型。。
预测效果好。
对异常值不敏感
KNN算法缺点
对内存要求较高,因为该算法存储了所有训练数据
预测阶段可能很慢
对不相关的功能和数据规模敏感。
当需要使用分类算法,且数据比较大的时候就可以尝试使用KNN算法进行分类了。
sklearn实现

from sklearn.neighbors import KNeighborsClassifier
import numpy as np
data_x=[[3.393533211,2.3312733811],
[3.110073483,1.7815396381],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.6965228751],
[5.745051997,3.533989803],
[9.172168622,2.5111010451],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
data_y=[0,0,0,0,0,1,1,1,1,1]
x=np.array(data_x)
y=np.array(data_y)
knn=KNeighborsClassifier(n_neighbors=6)
knn.fit(x,y)
new_x=np.array([1.093607318,3.3657315141])
x_predict=new_x.reshape(1,-1)
knn.predict(x_predict)





 关于 LearnKu
关于 LearnKu



