
 爪哇笔记
爪哇笔记14.Java 的 IO
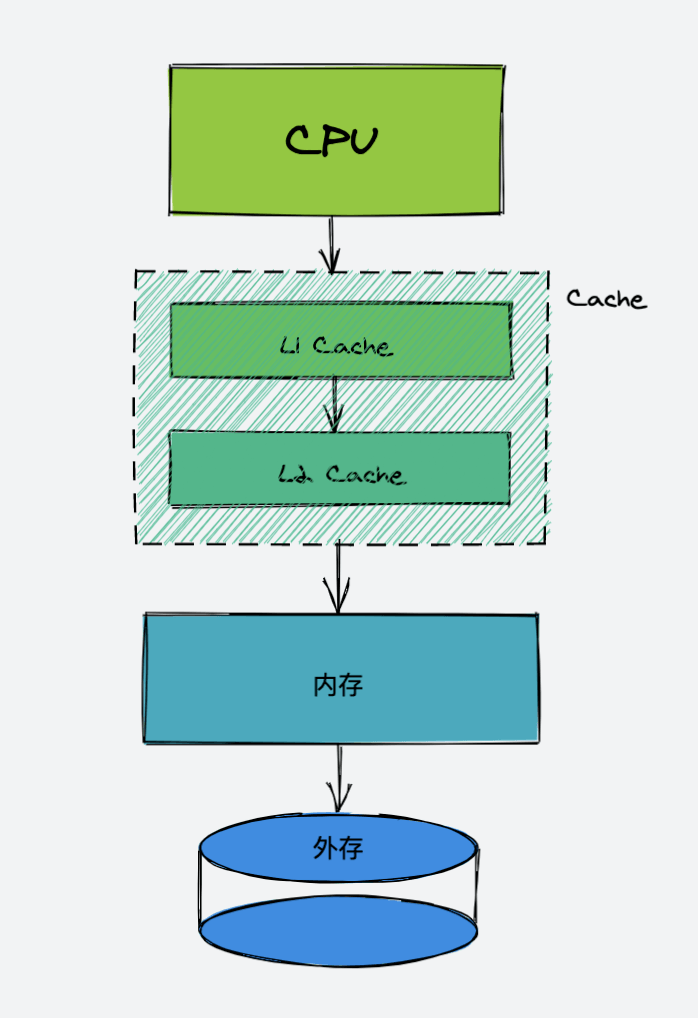
一:计算机的多级存储体系
CPU
CPU 是 Central Processing Unit 的缩写,简称中央处理器。中央处理器的主要功能就是解释计算机指令以及处理计算机软件中的数据,CPU 作为计算机系统的运算和控制核心,是信息处理,程序运行的最终执行单元。
Cache
Cache Memory 即:高速缓冲存储器,它是位于 CPU 与内存之间的临时存储器,可以设置在 CPU 的内部或外部。缓存具有容量比内存小,但是交换速度快的特点。缓存中的数据是内存中的一小部分,但是这一小部分是短时间内 CPU 即将访问的,当 CPU 需要调用大量数据时,就可以避开内存直接从缓存中调用,从而加快 CPU 的读取速度。
Cache 一般是由高速 SRAM 组成,其速度比内存要高 1~2 个数量级,Cache 通常还分为 一级缓存(L1),二级缓存(L2)与三级缓存(L3)。
内存与外存
内存,也被称为主存储器(Main Memory),CPU 与内存会进行直接沟通。它的本质其实就是一组或多组具备数据输入输出和数据存储功能的集成电路,内存的特点为:只用于暂时存放数据,一旦断电,数据就会消失。
外存是指除计算机内存以及 CPU 缓存以外的存储器,包含硬盘(HDD :机械硬盘;SSD 固态硬盘),光盘等。CPU 想要读取外存中的数据,首先需要将数据从外存设备加载到内存中,CPU 再从 内存里读取。外存处理速度比内存慢很多,但是优点是存储量大,并且外存靠磁介质可以对数据进行长久保存,具有断电数据不消失的特点。
CPU 从缓存,内存,外存中读取数据的速度是依次增加的,设计多级存储体系的原因主要还是考虑到性能与价格的平衡。
那么,对于 CPU 来说,这个世界究竟有多慢… 可以参考文章:cizixs.com/2017/01/03/how-slow-is-...
二:文件的本质
文件的本质是什么?
文件的本质实际上就是由 0,1 组成的一段字节流。无论是 mp3 音频,png 图片,还是在你电脑深处某个老师的视频,它们的本质都是字节流。图片可以被图片查看器打开,mp3 可以被音乐播放器播放,只是因为这些程序可以正确地解释这些字节流。
三:输入,输出与 Java 的 IO 详解
Java 的流分为输入流与输出流,通常称之为 IO 流。
输入(Input)指:从外存的文件读取到内存的程序中,输出(Output)指:从内存的程序输出到外存的文件中。
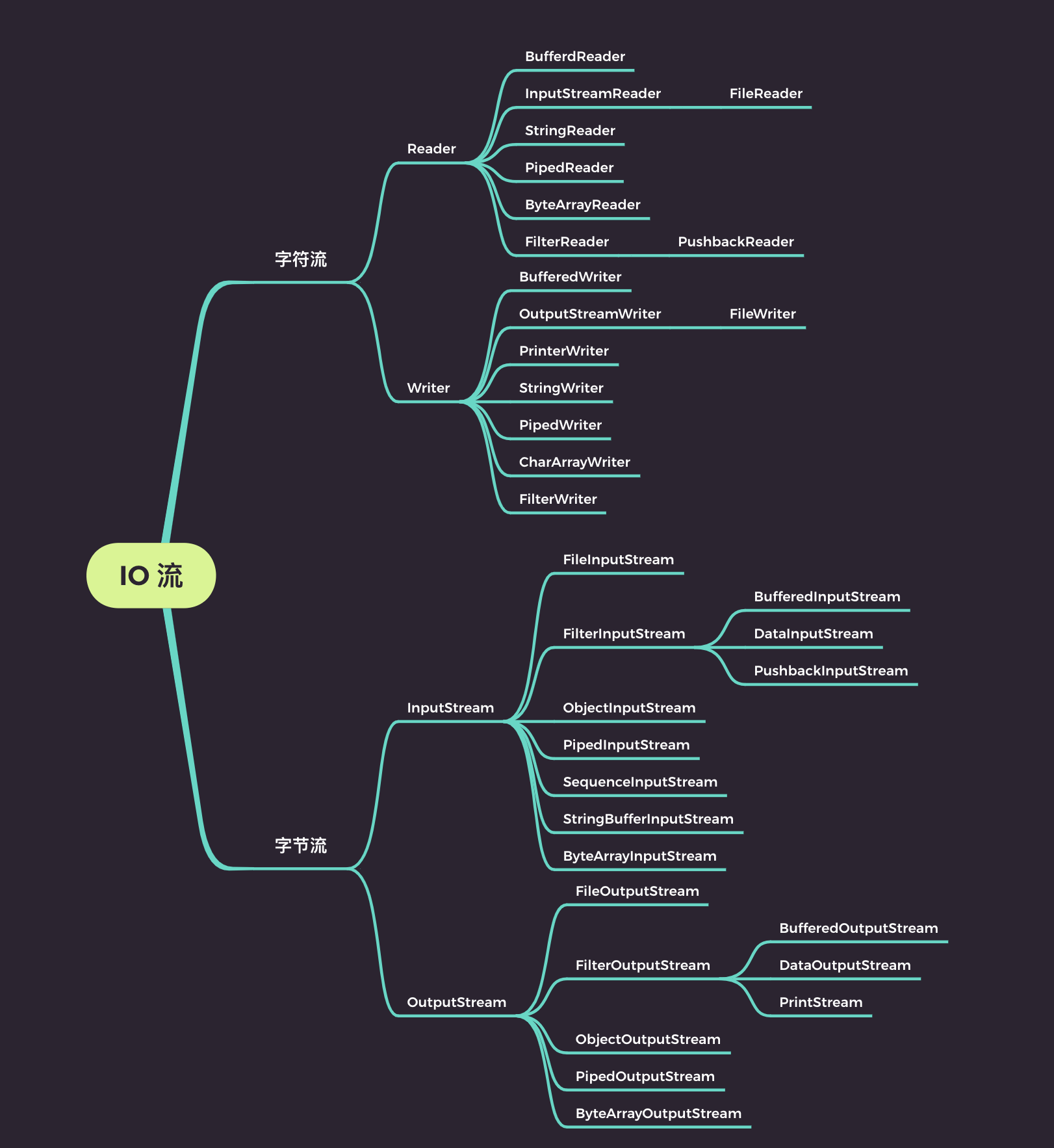
而 IO 流又可以分为字节流与字符流。
所谓的字节流是指针对二进制数据进行处理的流,它可以处理所有类型的文件,例如 png 图片,mp3 音频,avi 视频等文件都可以使用字节流进行传输。
而字符流只能针对字符文件进行读写操作。
Java 中所有流相关的操作类都继承以下四个抽象类:
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | InputStream | OutputStream |
| 字符流 | Reader | Writer |
而具体的继承类如下:
实战:从文件读取字节流
源码地址:github.com/jinrunheng/read-write-f...
1. 使用 InputStream/OutputStream 执行文件字节流读写操作
package com.github.readwritefilesdemo;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class FileAccessor {
public static void main(String[] args) {
File projectDir = new File(System.getProperty("basedir"), System.getProperty("user.dir"));
File testFile = new File(projectDir, "target/test.txt");
List<String> lines = Arrays.asList("AAA", "BBB", "CCC");
writeLinesToFile4(lines, testFile);
System.out.println(readFile4(testFile));
}
public static List<String> readFile4(File file) {
List<java.lang.String> list = new ArrayList<>();
StringBuilder sb = new StringBuilder();
try (InputStream is = new FileInputStream(file)) {
int content;
while ((content = is.read()) != -1) {
// \n ----> 10
if (content == 10) {
list.add(sb.toString());
sb = new StringBuilder();
} else {
sb.append((char) content);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
public static void writeLinesToFile4(List<String> lines, File file) {
try (OutputStream os = new FileOutputStream(file)) {
for (String line : lines) {
os.write(line.getBytes());
os.write("\n".getBytes());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}2. 使用 BufferedReader/BufferedWriter 执行文件字节流读写操作
package com.github.readwritefilesdemo;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class FileAccessor {
public static void main(String[] args) {
File projectDir = new File(System.getProperty("basedir"), System.getProperty("user.dir"));
File testFile = new File(projectDir, "target/test.txt");
List<String> lines = Arrays.asList("AAA", "BBB", "CCC");
writeLinesToFile1(lines, testFile);
System.out.println(readFile1(testFile));
}
public static List<String> readFile1(File file) {
List<String> list = new ArrayList<>();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file)))) {
String line;
while ((line = reader.readLine()) != null) {
list.add(line);
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
public static void writeLinesToFile1(List<String> lines, File file) {
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)))) {
for (String line : lines) {
writer.write(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}3. 使用 Apache Commons IO 执行文件字节流读写操作
package com.github.readwritefilesdemo;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class FileAccessor {
public static void main(String[] args) {
File projectDir = new File(System.getProperty("basedir"), System.getProperty("user.dir"));
File testFile = new File(projectDir, "target/test.txt");
List<String> lines = Arrays.asList("AAA", "BBB", "CCC");
writeLinesToFile2(lines, testFile);
System.out.println(readFile2(testFile));
}
public static List<String> readFile2(File file) {
try {
return IOUtils.readLines(new FileInputStream(file));
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public static void writeLinesToFile2(List<String> lines, File file) {
try {
IOUtils.writeLines(lines, "\n", new FileOutputStream(file));
} catch (IOException e) {
e.printStackTrace();
}
}
}4. 使用 Java NIO 执行文件字节流读写操作
package com.github.readwritefilesdemo;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class FileAccessor {
public static void main(String[] args) {
File projectDir = new File(System.getProperty("basedir"), System.getProperty("user.dir"));
File testFile = new File(projectDir, "target/test.txt");
List<String> lines = Arrays.asList("AAA", "BBB", "CCC");
writeLinesToFile3(lines, testFile);
System.out.println(readFile3(testFile));
}
public static List<String> readFile3(File file) {
try {
return Files.readAllLines(file.toPath());
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* NIO Java 7+
*
* @param lines
* @param file
*/
public static void writeLinesToFile3(List<String> lines, File file) {
try {
Files.write(file.toPath(), lines, Charset.forName("UTF-8"));
} catch (IOException e) {
e.printStackTrace();
}
}
}实战:从网络读取字节流
本实战代码地址:github.com/jinrunheng/simple-crawl...
实战内容:
从 GitHub 的 golang/go 仓库下爬取最新的十个 pull request
golang/go 仓库下 pull requests 地址为:github.com/golang/go/pulls
我们需要爬取的内容有三个:number,author 以及 title
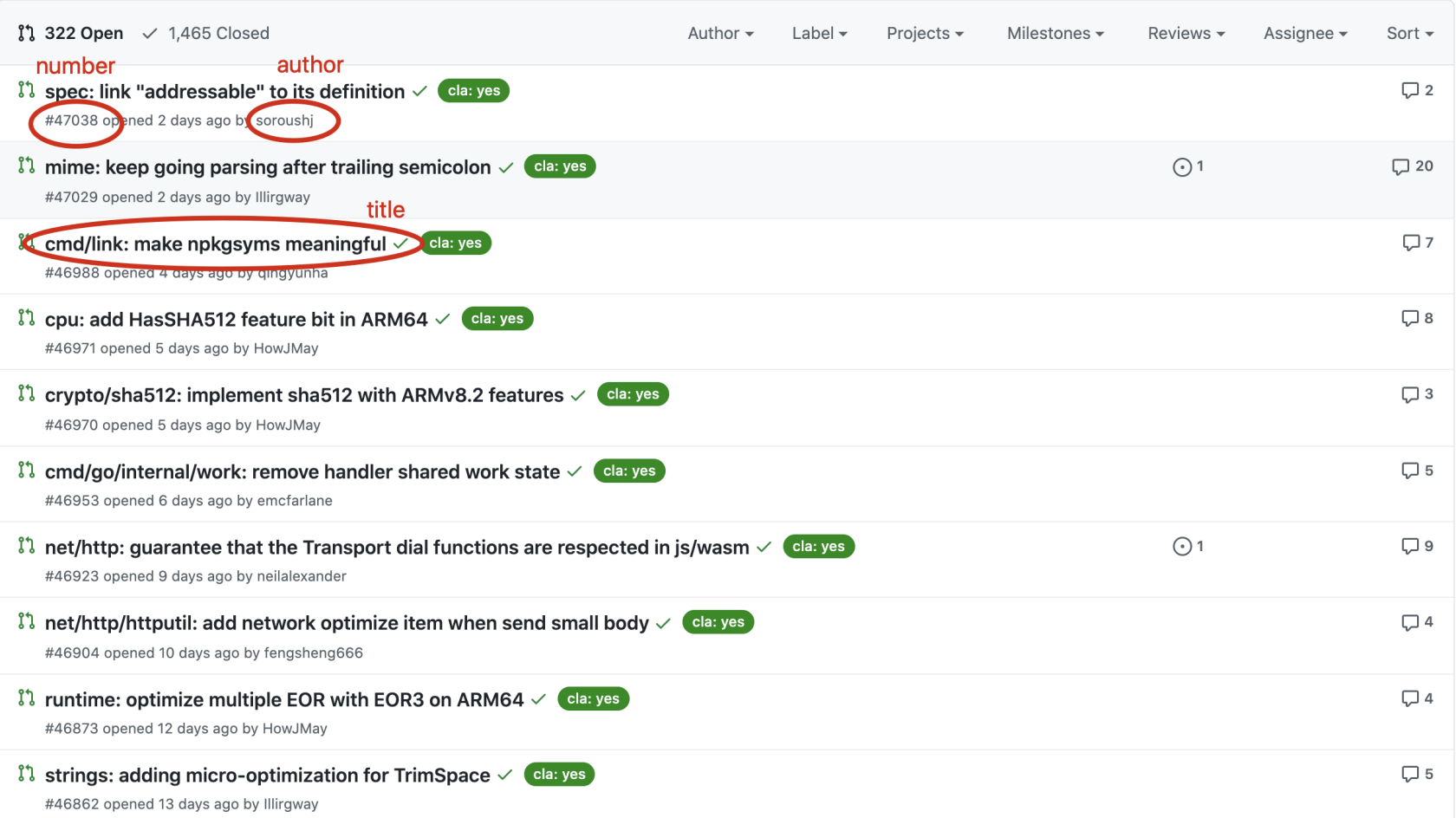
将最新的十条 pull request 的 number,author 以及 title 信息输出到本地文件中,格式如下:
number,author,title
47038,soroushj,spec: link "addressable" to its definition
47029,Illirgway,mime: keep going parsing after trailing semicolon
46988,qingyunha,cmd/link: make npkgsyms meaningful
46971,HowJMay,cpu: add HasSHA512 feature bit in ARM64
46970,HowJMay,crypto/sha512: implement sha512 with ARMv8.2 features
46953,emcfarlane,cmd/go/internal/work: remove handler shared work state
46923,neilalexander,net/http: guarantee that the Transport dial functions are respected in js/wasm
46904,fengsheng666,net/http/httputil: add network optimize item when send small body
46873,HowJMay,runtime: optimize multiple EOR with EOR3 on ARM64
46862,Illirgway,strings: adding micro-optimization for TrimSpace方法一
方法一为使用 OkHttp3 + Jsoup
OkHttp3 是 Android 当前使用认可度较高的一款用于处理网络请求的框架,由移动支付公司 Square 贡献,用于替代 Apache HttpClient。
Jsoup 是一款 Java 的 HTML 解析器,可以直接解析某个 URL 地址,HTML 文本内容。它提供了一套非常省力的 API,可以通过 DOM 以及类似于 jQuery 的操作方法来取出和操作数据。
我们的思路是,首先使用 OkHttp 向网站发送请求,获取页面的字符串文本,然后使用 Jsoup 将获取的字符串文本解析成 Document,通过分析网页的标签与结构,来获取我们想要爬取的数据。
代码如下:
package com.github.savepullrequeststocsv;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Node;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Crawler {
// repo 仓库名,例如 golang/go
// 爬取前 n 个 pull request 数据
// 保存为 csv 文件的格式
public static void savePullRequestsToCSV(String repo, int n, File csvFile) {
OkHttpClient httpClient = new OkHttpClient.Builder().build();
String url = "https://github.com/" + repo + "/pulls";
Request request = new Request.Builder()
.url(url)
.build();
try (FileWriter fileWriter = new FileWriter(csvFile, true)) {
Response response = httpClient.newCall(request).execute();
if (response.isSuccessful() && response.body() != null) {
String htmlString = response.body().string();
Document document = Jsoup.parse(htmlString);
Elements issuesList = document.getElementsByClass("js-navigation-container js-active-navigation-container");
List<Node> nodes = issuesList.get(0).childNodes();
List<Node> issuesNodes = new ArrayList<>();
for (int i = 0; i < nodes.size(); i++) {
if (i % 2 == 0) {
// skip
} else {
issuesNodes.add(nodes.get(i));
}
}
// 保存到 CSV 文件当中
List<String> lines = new ArrayList<>();
fileWriter.write("number,author,title" + "\n");
for (int i = 0; i < n; i++) {
Node node = issuesNodes.get(i).childNodes().get(1).childNodes().get(5);
Node node1 = node.childNodes().get(1);
Node node2 = node.childNodes().get(7).childNodes().get(1).childNodes().get(0);
Node node3 = node2.parentNode().childNodes().get(3).childNodes().get(0);
String number = node2.toString().substring(2, 7);
String author = node3.toString();
String title = node1.childNodes().get(0).toString();
lines.add(number + "," + author + "," + title);
}
for (String line : lines) {
fileWriter.write(line + "\n");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
Crawler.savePullRequestsToCSV("golang/go", 10, new File("/Users/macbook/Desktop/myProject/save-pull-requests-to-csv/test.csv"));
}
}方法二
方法二为直接使用 GitHub 的 API,如果你使用的是 Maven 构建工具,只需要导入依赖:
<dependency>
<groupId>org.kohsuke</groupId>
<artifactId>github-api</artifactId>
<version>1.95</version>
</dependency>代码如下:
package com.github.savepullrequeststocsv;
import org.kohsuke.github.GHIssueState;
import org.kohsuke.github.GHPullRequest;
import org.kohsuke.github.GHRepository;
import org.kohsuke.github.GitHub;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Crawler2 {
public static void savePullRequestsToCSV(String repo, int n, File csvFile) throws IOException {
GitHub gitHub = GitHub.connectAnonymously();
GHRepository repository = gitHub.getRepository(repo);
List<GHPullRequest> pullRequests = repository.getPullRequests(GHIssueState.OPEN);
List<String> list = new ArrayList<>();
list.add("number,author,title");
for (GHPullRequest pullRequest : pullRequests) {
list.add(getLine(pullRequest));
if (list.size() > n) {
break;
}
}
try (FileWriter fileWriter = new FileWriter(csvFile, true)) {
for (String line : list) {
fileWriter.write(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static String getLine(GHPullRequest pullRequest) {
try {
return pullRequest.getNumber() + "," + pullRequest.getUser().getLogin() + "," + pullRequest.getTitle();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws IOException {
Crawler2.savePullRequestsToCSV("golang/go", 10, new File("/Users/macbook/Desktop/myProject/save-pull-requests-to-csv/test.csv"));
}
}四:文件类 File 详解
在 Java 中,File 类是 java.io 包下唯一代表磁盘文件本身的对象,它并不具有从文件读取信息和向文件写入信息的功能,它仅描述文件本身的属性。
绝对路径与相对路径
绝对路径指的是文件在硬盘上的物理路径,它是一个完整的路径,是从树形目录结构顶部的根目录开始到某个目录或文件的路径;而相对路径是指以工作进程的当前目录作为起始点,目标文件的相对位置。
如果你搞不清相对路径的写法,那么请永远使用绝对路径。
递归读取文件夹下的文件
在第十章面向对象之接口与抽象类中,我们介绍过使用 Java NIO 的 Files.walkFileTree() 方法递归遍历文件,现有目录 test ,层级结构如下:
├── a
│ └── c
│ ├── c.txt
│ └── d
│ ├── d.txt
│ └── e
│ └── e.txt
├── b
│ └── f
│ ├── f.txt
│ └── h
│ └── h.txt这个层级结构的示意图是我通过命令 tree 来展现的,如果是 Linux 操作系统的用户,则自带该命令;如果是 macOS 则需要使用 brew 下载(brew install tree)
将 test 目录下所有后缀为 txt 的文件名打印
代码如下:
package com.github.hcsp.io;
import java.io.File;
import java.io.IOException;
import java.nio.file.FileVisitResult;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.SimpleFileVisitor;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.ArrayList;
import java.util.List;
public class WalkFile {
public static List<String> walkFile(String rootPath) throws IOException {
List<String> list = new ArrayList<>();
File file = new File(rootPath);
Files.walkFileTree(file.toPath(), new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
if (file.toString().endsWith("txt")) {
list.add(file.getFileName().toString());
}
return FileVisitResult.CONTINUE;
}
});
return list;
}
public static void main(String[] args) throws IOException {
System.out.println(walkFile("/Users/macbook/Desktop/myProject/hcsp/save-pull-requests-to-csv/src/test"));
}
}程序执行结果:
[c.txt, d.txt, e.txt, h.txt, f.txt]File 类的常用方法
File 类的常用方法:
关于 File 类的常见方法请参见 JDK API,在这里我们只列举一些比较常见的方法名称,就不再赘述方法细节了。
File 类创建与删除
boolean createNewFile();boolean mkdir();boolean mkdirs();boolean delete();
File 类的判断功能
boolean exists();boolean isAbsolute();boolean isDirectory();boolean isFile();boolean isHidden();
File 类的获取与修改
File getAbsoluteFile();String getAbsolutePath();String getParent();String getName();String getPath();long lastModified();long length();boolean renameTo(File dest);String[] list();File[] listFiles();
五:Java 的 NIO
我们知道,IO 操作通常使用在如下两个场景中:
- 网络 IO
- 文件 IO
处理文件 IO 时,IO 与 NIO 的区别实际上并不大。
NIO 的出现是为了解决传统 IO 在网络 IO 的应用中带来的阻塞问题。
传统的 IO 流都是阻塞的。也就是说,当一个线程调用读或写的操作时,该线程会被阻塞,直到有一些数据读取或者写入,该线程在此期间不能执行其他任务。因此,在完成网络通信进行 IO 操作时,由于线程会阻塞,所以服务端必须为每个客户端都提供一个独立的线程进行处理,当服务器需要处理大量的客户端端连接时,性能会急剧下降。
Java 1.4 开始引入了一种全新的异步 IO 模式,即:NIO。
关于 NIO 的翻译,普遍认为有两种,第一种是 New IO ,第二种是 Non-blocking IO (非阻塞 IO)。
所谓的非阻塞 IO 就是,当线程从某个通道(Channel)进行读写数据时,如果没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞 IO 的空闲时间用于其他通道上执行 IO 操作,所以单独的线程可以管理多个输入和输出通道。因此,NIO 可以让服务器端使用一个或有限几个线程来同时处理连接到服务器端到所有客户端。
NIO 主要有三大核心部分:Channel(通道),Buffer(缓冲区),Selector(选择区)。
传统的 IO 基于字节流和字符流进行操作,而 NIO 是基于 Channel 和 Buffer 进行操作的。
关于 NIO 的知识点,大家先暂时了解到这里就可以了。因为 NIO 本身是一个比较抽象难懂的知识点,在后面如果我们涉及到网络编程时再抽出来单独讲解。
Files
Files 是 JDK 1.7 发布,位于 nio 包下的一个提供对 Path 操作的工具类。Path 也是 JDK 1.7 引入的类,相当于 File 类的升级版,但是 JDK 并没有废弃掉 File 类,这是因为 File 类当中还保留了一些好用的操作。并且,Java 提供了简单的 API 用来支持对 File 和 Path 进行相互转换:
File to Path:
Path path = file.toPath();Path to File:
File file = path.toFile();Files 工具类当中有许多好用的操作 IO 的方法:
Files.exists();Files.createFile();Files.createDirectory();Files.delete();Files.copy();Files.move();Files.size();Files.read();Files.write();Files.readAllLines();Files.walkFileTree();Files.createTempFile();… …
每种方法的具体含义就不在这里赘述了,请大家自行查阅 API






 关于 LearnKu
关于 LearnKu



