
 爪哇笔记
爪哇笔记4.链表
一:什么是链表
链表(Linked List)是一种真正的动态数据结构。它由一个个节点(Node)组成,节点中存储着数据以及指向下一个节点的指针(引用)。
最适合用来比喻链表的模型就是火车了:

节点(Node)就好比是火车的一节车厢,一节节“车厢”串联在一起组成了链表(Linked List)。
链表和动态数组一样,都是一种线性的数据结构。不过,链表是真正的动态数据结构,它的优点是并不需要处理固定容量的问题;它的缺点是丧失了数组这种随机访问的能力。
对于数组这种数据结构而言,我们声明一个数组都需要指定数组的大小,其目的是在内存中开辟一个大小固定,并且连续的空间。因为开辟的内存空间是连续的,所以数组拥有随机访问数据的能力。而链表则不同,链表的每一个节点在内存上的分布并不是连续的,我们只能通过指针(引用)来找到下一个节点。
| 数组 | 链表 | |
|---|---|---|
| 优点 | 支持快速查询 | 动态 |
| 缺点 | 需要在内存中开辟固定大小的空间、非动态 | 真正的动态 |
二:实现链表
在链表中添加元素
我们的链表会引入一个虚拟头节点(dummyHead)放置在链表的最前头,其目的是方便处理我们向链表中添加元素的逻辑。如果没有引入虚拟头节点,那么向链表插入一个元素就需要分成向链表头部插入一个元素与向链表其他位置插入一个元素这两种情况来考虑。
现有链表结构如下:
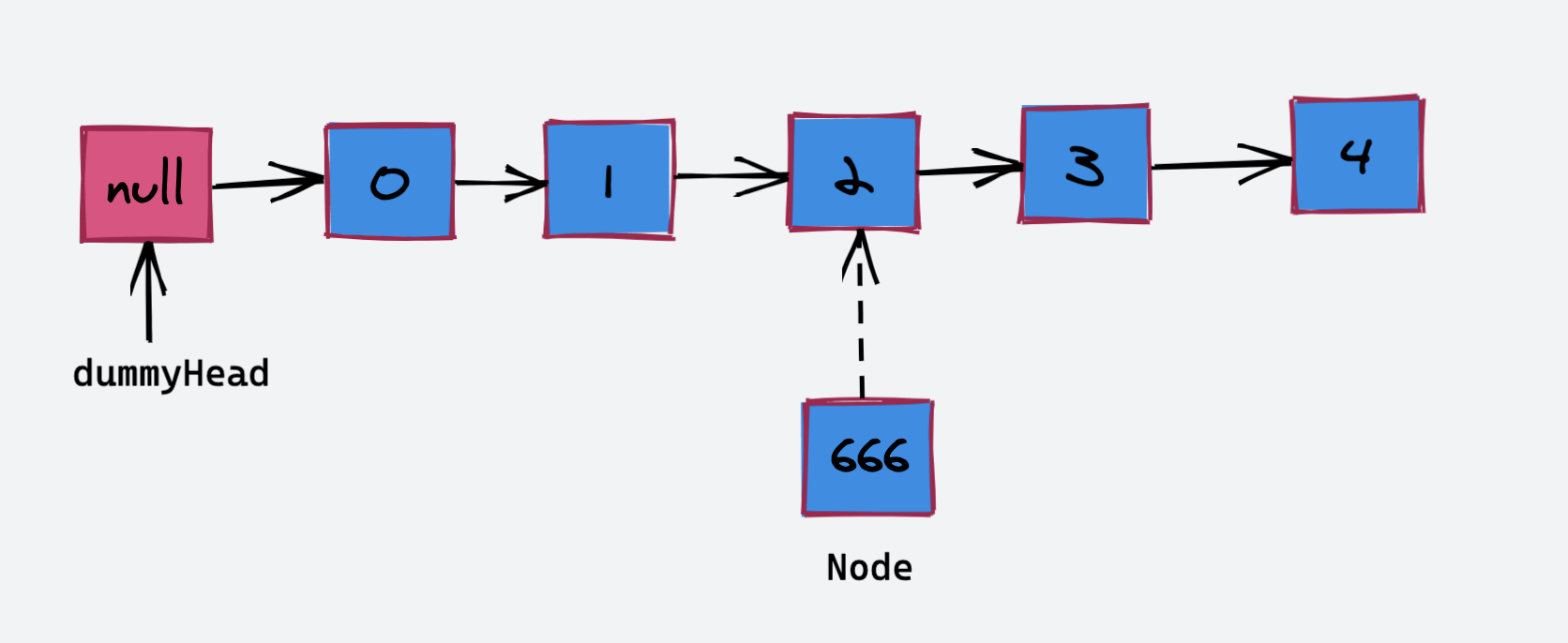
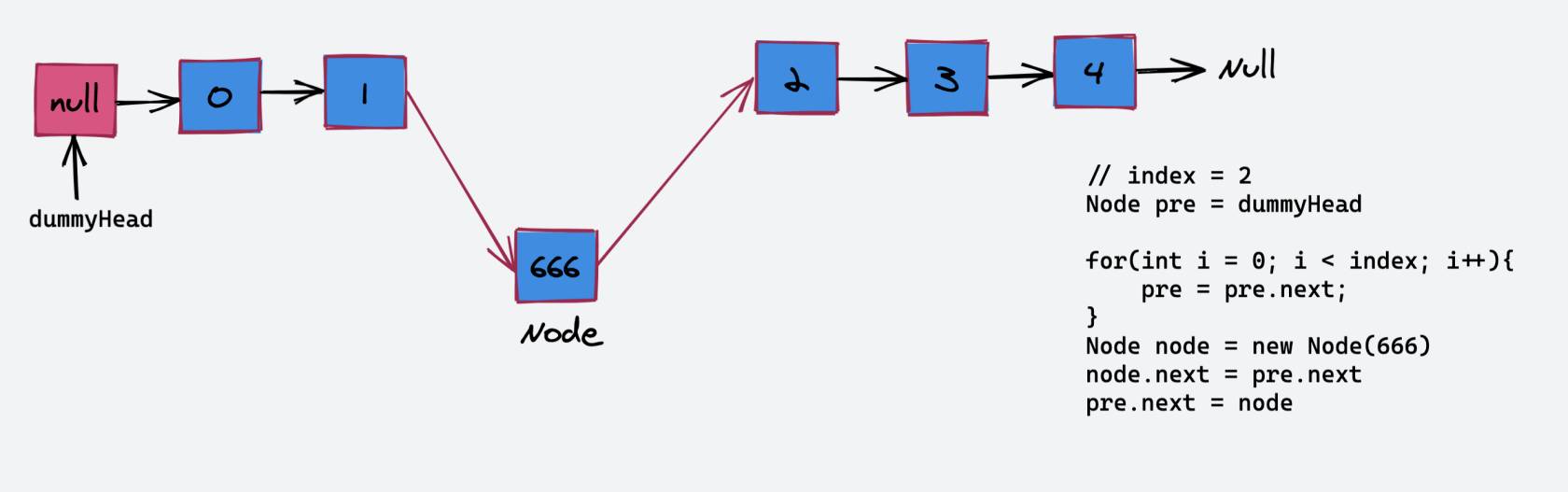
如果我们要向 “index = 2” 的位置插入一个节点 “666”,具体的操作流程如下:
在链表中删除元素
现有链表结构如下:
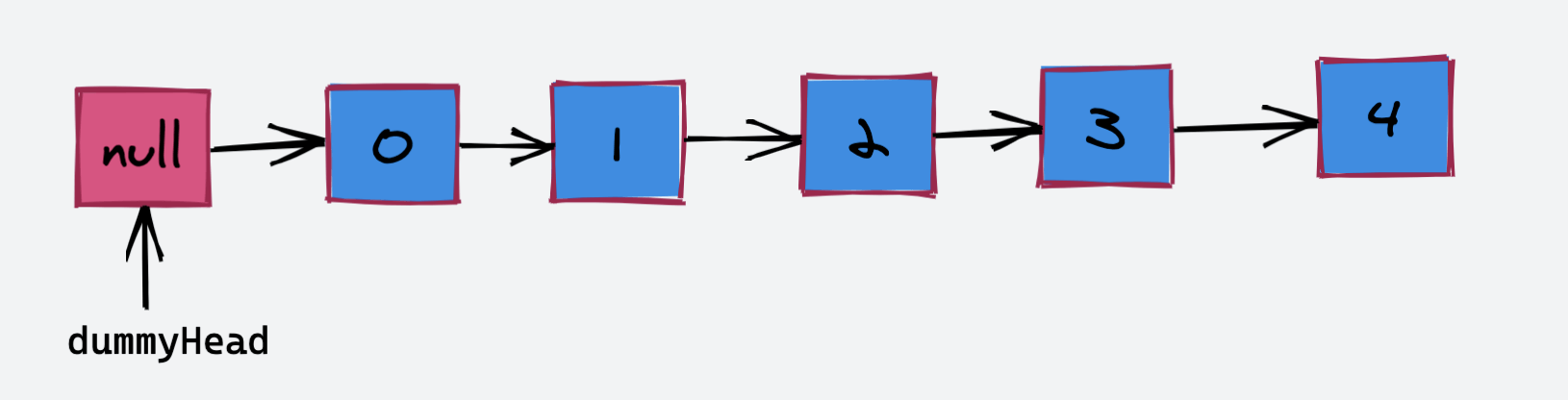
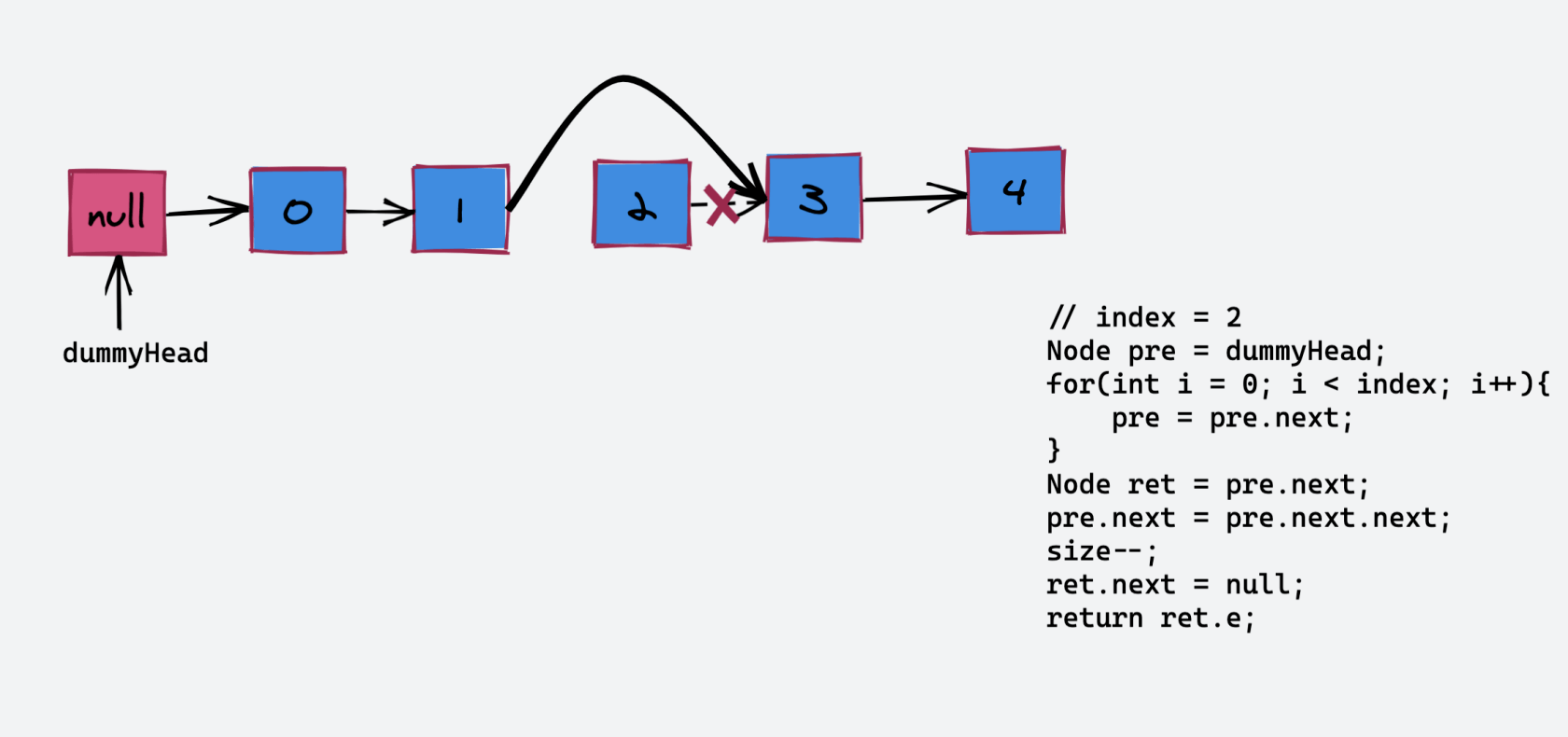
如果我们要将 “index = 2” 位置的节点删除,具体的操作流程如下:
链表的时间复杂度分析
| 方法 | 时间复杂度 |
|---|---|
| addLast(e) | O(N) |
| addFirst(e) | O(1) |
| add(e,index) | O(N) |
| removeLast() | O(N) |
| removeFirst() | O(1) |
| remove(e,index) | O(N) |
| set(index) | O(N) |
| get(index) | O(N) |
| contains(e) | O(N) |
三:使用链表实现栈与队列
使用链表实现栈
我们使用链表作为底层,实现栈这种数据结构。因为链表对头部操作的时间复杂度为 O(1),所以我们使用链表头部作为栈顶,链表尾部作为栈底。
性能测试:
package com.github.datastructureandalgorithm.datastructure.Stack;
import org.junit.jupiter.api.Test;
import java.util.Random;
public class StackPerformanceTest {
private static double testStack(Stack<Integer> stack, int opCount) {
long startTime = System.nanoTime();
Random random = new Random();
for (int i = 0; i < opCount; i++) {
stack.push(random.nextInt(Integer.MAX_VALUE));
}
for (int i = 0; i < opCount; i++) {
stack.pop();
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
@Test
void test() {
int opCount = 1000000;
ArrayStack<Integer> arrayStack = new ArrayStack<>();
double time1 = testStack(arrayStack, opCount);
System.out.println("ArrayStack,time: " + time1 + " s");
LinkedListStack<Integer> linkedListStack = new LinkedListStack<>();
double time2 = testStack(linkedListStack, opCount);
System.out.println("LinkedListStack,time: " + time2 + " s");
}
}运行测试代码,程序输出结果如下:
ArrayStack,time: 0.065205394 s
LinkedListStack,time: 0.065400511 s在我的电脑上,对于一百万级数据,二者性能上的差异并没有相差太多。ArrayStack 底层实现为动态数组,耗时的操作主要为扩容;而对于 LinkedListStack 而言,它的底层实现为链表,比 ArrayStack 包含了更多的 new 操作。不过整体上,二者的性能是相近的。
使用链表实现队列
我们使用链表实现了栈这种数据结构,使用链表头部作为栈顶,链表尾部作为栈底,使得入栈与出栈时间复杂度为 O(1)。如果我们要用链表作为底层实现队列这种数据结构,我们就会发现,对于队列这种从一端进另一端出的数据结构,我们的链表总会导致 enqueue 与 dequeue 其中一个操作变为 O(N) 的时间复杂度。
改进如下:
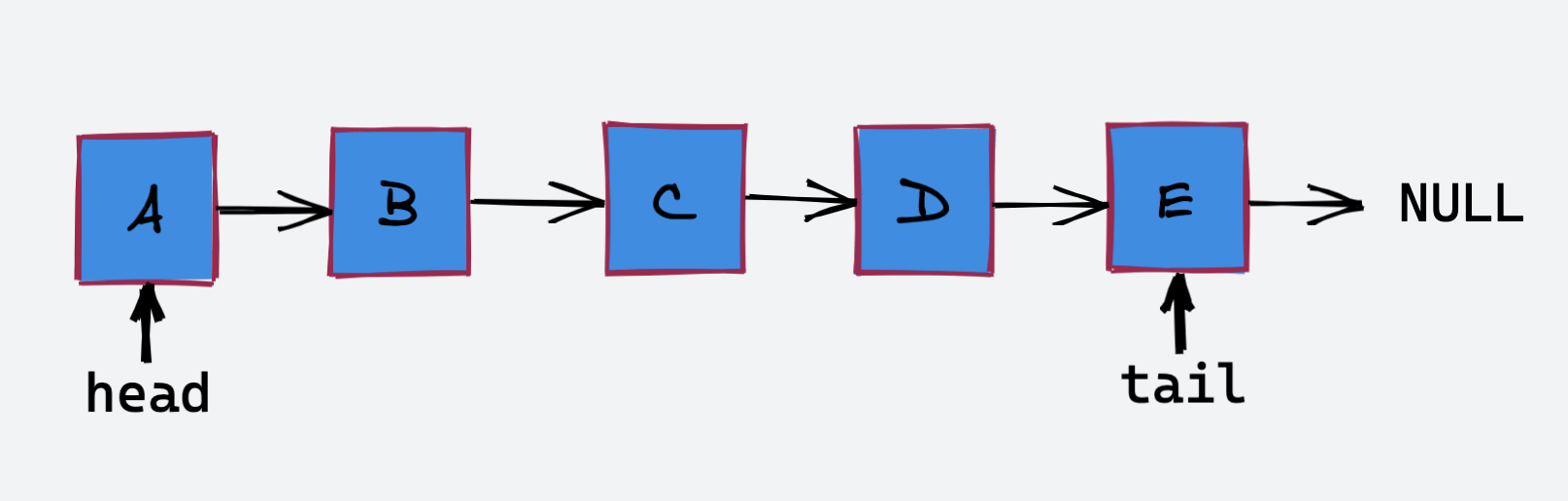
使用头指针 head 与尾指针 tail 标记链表的头节点和尾节点。如果我们使用链表作为队列的底层实现,那么就要考虑队列的出队操作对应链表删除一个节点,删除节点就需要知道前一个节点。
所以将 head 作为队首,将 tail 作为队尾的话,队列的入队和出队就都是时间复杂度为 O(1) 的操作了。
性能测试:
package com.github.datastructureandalgorithm.datastructure.Queue;
import org.junit.jupiter.api.Test;
import java.util.Random;
public class QueuePerformanceTest {
/**
* @param queue 测试的队列
* @param opCount 测试数据的数量级
* @return 运行 testQueue 方法所需要的时间
*/
private static double testQueue(Queue<Integer> queue, int opCount) {
long startTime = System.nanoTime();
Random random = new Random();
for (int i = 0; i < opCount; i++) {
queue.enqueue(random.nextInt(Integer.MAX_VALUE));
}
for (int i = 0; i < opCount; i++) {
queue.dequeue();
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
@Test
void performanceTest() {
int opCount = 100000;
ArrayQueue<Integer> arrayQueue = new ArrayQueue<>();
LoopQueue<Integer> loopQueue = new LoopQueue<>();
LinkedListQueue<Integer> linkedListQueue = new LinkedListQueue<>();
double time1 = testQueue(arrayQueue, opCount);
System.out.println("ArrayQueue time : " + time1 + " s");
double time2 = testQueue(loopQueue, opCount);
System.out.println("LoopQueue time : " + time2 + " s");
double time3 = testQueue(linkedListQueue, opCount);
System.out.println("LinkedListQueue time : " + time3 + " s");
}
}运行测试代码,程序输出结果如下:
ArrayQueue time : 3.080281543 s
LoopQueue time : 0.010349569 s
LinkedListQueue time : 0.006150894 s我们看到,LinkedListQueue 与 LoopQueue 的性能上是比较接近的,二者的性能都要远远优于 ArrayQueue。
四:链表与递归
接下来,我们从一道 LeetCode 题目来探究下链表与递归的关系
本题的第一种解题思路是遍历链表,找到值为 val 的节点,然后删除;我们需要考虑当链表的第一个节点即为要删除的节点这种情况,且这种情况要进行特殊处理。
我们可以使用设置虚拟头节点 dummyHead 的思想,让所有的情况都归一化处理,代码逻辑比较简单,这里就不再赘述了:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode dummyHead = new ListNode(-1);
dummyHead.next = head;
ListNode pre = dummyHead;
while(pre.next != null){
if(pre.next.val == val){
ListNode delNode = pre.next;
pre.next = delNode.next;
delNode.next = null;
}else {
pre = pre.next;
}
}
return dummyHead.next;
}
}第二种解题思路就是递归。
什么是递归?
递归的本质就是将原来的问题,转化为更小的同一问题。
递归算法确定两点:
- 确认返回条件。这里面的返回条件也就是我们说的 base case,即递归触底的返回值。如果遗忘了 base case,就会造成 StackOverflowError
- 确定递推算法。递推算法就是,我们需要明确如何将一个大问题划分成规模更小的同一子问题
我们可以将原问题细分成更小的子问题:
原链表如下

对于解决了“一个更短的链表” 这个子问题后,我们共有两种可返回的情况:
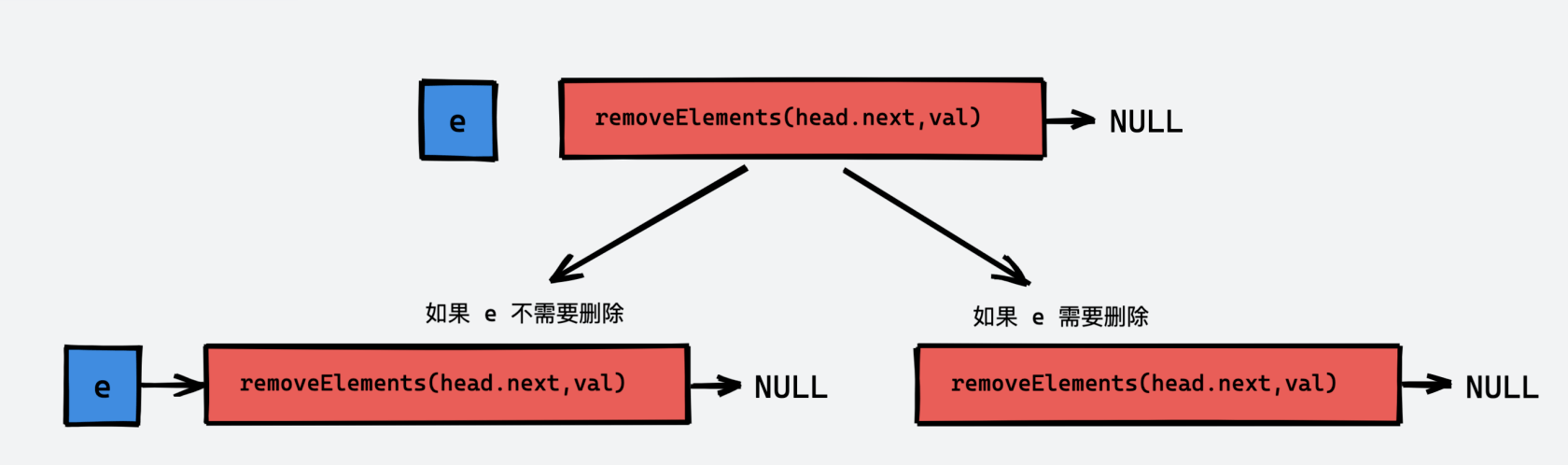
这样我们的递推算法就已经确定了。
我们在上面提到过,一定不要忘记递归算法的 base case:当 “一个更短的链表” 成为一个空链表时,返回空。
代码如下:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
if(head == null){
return null;
}
if(head.val == val){
return removeElements(head.next,val);
}else {
head.next = removeElements(head.next,val);
return head;
}
}
}





 关于 LearnKu
关于 LearnKu



