
 Go Blog 中文翻译
Go Blog 中文翻译Go 程序代码分析(Profiling)
Russ Cox, 2011 年 7 月; Shenghou Ma, 更新于 2013 年 5 月
2011 年6 月 24 日
在 2011 年的 Scala Days 上, Robert Hundt 提交了一篇题为 Loop Recognition in C++/Java/Go/Scala. 的论文, 该论文实现了特定的循环查找算法, 例如你可能在 C++, Go, Java, Scala 等编译器的流程分析过程中使用的代码, 然后使用这些程序得出关于这些语言中典型性能问题的结论. 该论文中介绍的 Go 程序运行速度非常慢, 这是一个极好的机会, 可以演示如何使用 Go 的性能分析工具来使缓慢的程序更快.
通过使用 Go 的分析工具来识别并纠正特定的瓶颈, 我们使 Go 循环查找程序的运行提高了一个数量级, 并且使用的内存减少了 6 倍. (更新: 由于最近对 c++ 中 libstdc++ 的优化, 现在的内存减少为 3.7 倍.)
Hundt 的论文没有指定他使用的 C++, Go, Java 和 Scala 工具的版本. 在此博客文章中, 我们将使用 6g Go 编译器的最新每周快照以及 Ubuntu Natty 发行版随附的 g++ 版本. (我们不会使用 Java 或 Scala, 因为我们不怎么熟练使用这两种语言编写高效的程序, 因此进行比较会不太公平. 由于 C++ 是本文中最快的语言, 因此与 C++ 比较就足够了.) (更新: 在此更新帖子中, 我们将使用 amd64 上的 Go 编译器的最新开发快照以及 2013 年 3 月发布的最新版本的 g++ -- 4.8.0.)
$ go version
go version devel +08d20469cc20 Tue Mar 26 08:27:18 2013 +0100 linux/amd64
$ g++ --version
g++ (GCC) 4.8.0
Copyright (C) 2013 Free Software Foundation, Inc.
...
$这些程序运行在 Gentoo Linux 3.8.4-gentoo 内核, 该计算机配置为 3.4GHz Core i7-2600 CPU 和 16 GB 内存. 通过以下方式禁止机器的 CPU 频率缩放运行
$ sudo bash
# for i in /sys/devices/system/cpu/cpu[0-7]
do
echo performance > $i/cpufreq/scaling_governor
done
#我们已经在 C++ 和 Go 中采用了 Hundt的基准测试程序, 将它们合并为一个源文件, 并删除了除第一行以外的所有输出. 我们将使用 Linux 的 time 实用程序对程序进行计时, 其格式可以显示用户时间, 系统时间, 实时和最大内存使用量:
$ cat xtime
#!/bin/sh
/usr/bin/time -f '%Uu %Ss %er %MkB %C' "$@"
$
$ make havlak1cc
g++ -O3 -o havlak1cc havlak1.cc
$ ./xtime ./havlak1cc
# of loops: 76002 (total 3800100)
loop-0, nest: 0, depth: 0
17.70u 0.05s 17.80r 715472kB ./havlak1cc
$
$ make havlak1
go build havlak1.go
$ ./xtime ./havlak1
# of loops: 76000 (including 1 artificial root node)
25.05u 0.11s 25.20r 1334032kB ./havlak1
$C++ 程序运行了 17.80, 并使用 700MB 内存. Go 程序运行了 25.20 秒, 并使用 1302MB 内存. (这些度量很难与论文中的度量调和, 但是本文的重点是探讨如何使用 go tool pprof, 而不是从论文中复制结果.)
要开始调试 Go 程序, 我们必须启用性能分析. 如果代码使用了 Go 测试包 的基准测试支持, 则我们可以使用 gotest 的标准标志 -cpuprofile 和 -memprofile. 在像这样的独立程序中, 我们必须导入 runtime/pprof 并添加几行代码:
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
flag.Parse()
if *cpuprofile != "" {
f, err := os.Create(*cpuprofile)
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
}
...新代码定义了一个名为 cpuprofile 的标志, 调用 Go 标志库 来解析命令行标志, 然后, 如果 cpuprofile 标志已在命令行上设置, 启动CPU性能分析 将重定向到该文件. 探查器最后需要调用 StopCPUProfile 以在程序退出之前刷新对文件的所有未完成的写操作; 我们使用 defer 来确保在 main 返回时发生这种情况.
添加该代码后, 我们可以使用新的 -cpuprofile 标志运行该程序, 并运行 go tool pprof 来解释该配置文件.
$ make havlak1.prof
./havlak1 -cpuprofile=havlak1.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak1 havlak1.prof
Welcome to pprof! For help, type 'help'.
(pprof)go tool pprof 程序是 Google 的 pprof C++ 分析器 的 Go 变种. 最重要的命令是 topN, 它显示配置文件中的前 N 个样本.
(pprof) top10
Total: 2525 samples
298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64
268 10.6% 22.4% 2124 84.1% main.FindLoops
251 9.9% 32.4% 451 17.9% scanblock
178 7.0% 39.4% 351 13.9% hash_insert
131 5.2% 44.6% 158 6.3% sweepspan
119 4.7% 49.3% 350 13.9% main.DFS
96 3.8% 53.1% 98 3.9% flushptrbuf
95 3.8% 56.9% 95 3.8% runtime.aeshash64
95 3.8% 60.6% 101 4.0% runtime.settype_flush
88 3.5% 64.1% 988 39.1% runtime.mallocgc启用 CPU 性能分析后, Go 程序每秒停止约 100 次, 并在当前正在执行的协程堆栈上记录一个由程序计数器组成的样本. 该配置文件有 2525 个样本, 因此运行了 25 秒多一点. 在 go tool pprof 的输出中, 样本中出现的每个函数都有一行. 前两列以原始计数和占总样本的百分比的形式显示了函数在其中运行的样本数 (而不是等待调用的函数返回).runtime.mapaccess1_fast64 函数正在 298个 样本中运行, 即11.8%. top10 输出按此样本计数排序. 第三列显示列表中的运行总计: 前三行占样本的 32.4%. 第四和第五列显示了函数出现 (运行或等待被调用函数返回) 的样本数.main.FindLoops 函数在 10.6% 的示例中运行, 但在84.1%的示例中的调用堆栈上(它调用的函数或函数正在运行).
要按第四和第五列排序, 可以用 -cum (用于累积) 标志:
(pprof) top5 -cum
Total: 2525 samples
0 0.0% 0.0% 2144 84.9% gosched0
0 0.0% 0.0% 2144 84.9% main.main
0 0.0% 0.0% 2144 84.9% runtime.main
0 0.0% 0.0% 2124 84.1% main.FindHavlakLoops
268 10.6% 10.6% 2124 84.1% main.FindLoops
(pprof) top5 -cum实际上, main.FindLoops 和 main.main 的总数应为 100%, 但每个堆栈样本仅包括底部的100 个堆栈帧; 在大约四分之一的样本中, 递归 main.DFS 函数比 main.main 深度深 100 帧以上, 因此完整的跟踪被截断了.
堆栈跟踪样本包含的相关函数调用关系的有趣数据比文本列表所显示的要多得多. web 命令以 SVG 格式写入配置文件数据的图形, 然后在网页浏览器中将其打开. (还有一个 gv 命令可编写PostScript 并在 Ghostview 中打开. 对于任一命令, 都需要安装 graphviz.)
(pprof) web全图 的一小段看起来如下:
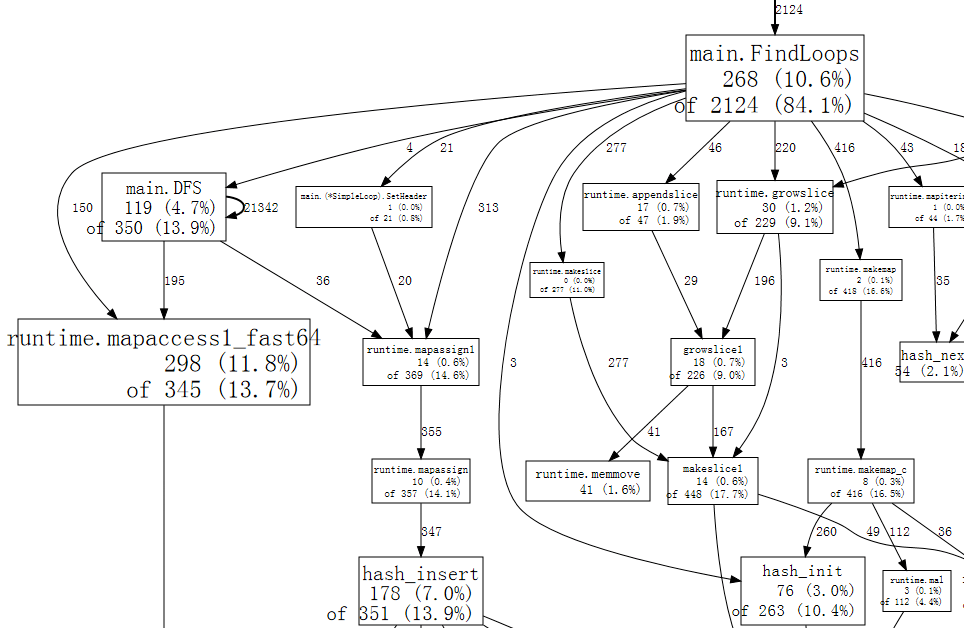
图表中的每个方框都对应一个函数, 方框的大小根据运行该函数的样本数确定. 从框 X 到框 Y 的边表示 X 调用 Y; 边缘的数字是呼叫在样本中出现的次数. 如果一次调用在单个样本中多次出现(例如在递归函数调用期间), 则每次出现都会计入边缘权重. 这也就解释了 21342 在从 main.DFS 到自身的边缘上.
乍一看, 我们可以看到该程序将大量时间花费在哈希运算上, 这与 Go 的 map 值的使用相对应. 我们可以告诉 web 仅使用包含特定功能的示例, 例如 runtime.mapaccess1_fast64, 该示例清除了图中的一些噪声:
(pprof) web mapaccess1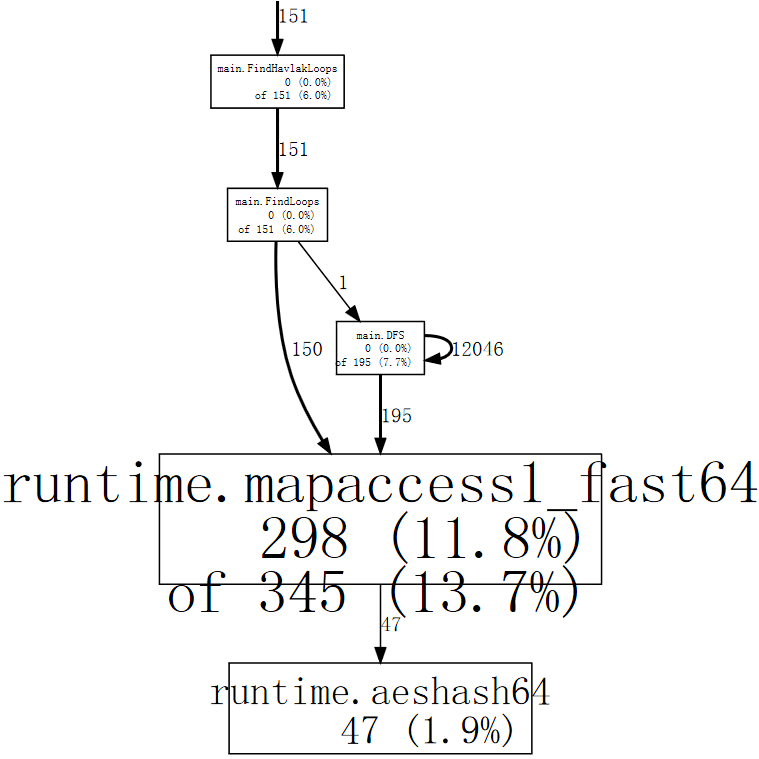
如果脖子歪着斜一点, 我们可以看到对 runtime.mapaccess1_fast64 的调用是由 main.FindLoops 和 main.DFS 进行的.
现在, 我们对总体情况有了一个大概了解了, 是时候放大特定功能了. 首先看看 main.DFS, 因为它是一个较短的函数:
(pprof) list DFS
Total: 2525 samples
ROUTINE ====================== main.DFS in /home/rsc/g/benchgraffiti/havlak/havlak1.go
119 697 Total samples (flat / cumulative)
3 3 240: func DFS(currentNode *BasicBlock, nodes []*UnionFindNode, number map[*BasicBlock]int, last []int, current int) int {
1 1 241: nodes[current].Init(currentNode, current)
1 37 242: number[currentNode] = current
. . 243:
1 1 244: lastid := current
89 89 245: for _, target := range currentNode.OutEdges {
9 152 246: if number[target] == unvisited {
7 354 247: lastid = DFS(target, nodes, number, last, lastid+1)
. . 248: }
. . 249: }
7 59 250: last[number[currentNode]] = lastid
1 1 251: return lastid
(pprof)清单显示了 DFS 函数的源代码 (确实, 对于与正则表达式 DFS 匹配的每个函数). 前三列是在运行该行时获取的样本数, 在运行该行或从该行调用的代码中获取的样本数以及文件中的行号. 相关的命令 disasm 显示了该函数的反汇编而不是源列表; 如果有足够的样本, 这可以帮助您了解哪些指令很昂贵. weblist 命令混合了两种模式: 它显示 源列表, 单击一行可显示反汇编.
由于我们已经知道将时间投入到由哈希运行时函数实现的映射查找中,因此我们最关心第二列。正如递归遍历所预期的那样,大部分时间都花在对 DFS 的递归调用中(第 247 行)。不包括递归,似乎是时候进入对第 242、246 和 250 行上的 number 映射的访问了。对于特定的查找,映射不是最有效的选择。就像在编译器中一样,基本块结构具有分配给它们的唯一序列号。除了使用 map[* BasicBlock]int 之外,我们还可以使用 []int,即按块号索引的切片。当数组或切片可以使用时,没有理由使用映射。
将 number 从映射更改为切片需要在程序中编辑七行并将其运行时间减少了近两倍:
$ make havlak2
go build havlak2.go
$ ./xtime ./havlak2
# of loops: 76000 (including 1 artificial root node)
16.55u 0.11s 16.69r 1321008kB ./havlak2
$(可参阅 havlak1 和 havlak2)
我们可以再次运行分析器以确认 main.DFS 不再是运行时间的主要部分:
$ make havlak2.prof
./havlak2 -cpuprofile=havlak2.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak2 havlak2.prof
Welcome to pprof! For help, type 'help'.
(pprof)
(pprof) top5
Total: 1652 samples
197 11.9% 11.9% 382 23.1% scanblock
189 11.4% 23.4% 1549 93.8% main.FindLoops
130 7.9% 31.2% 152 9.2% sweepspan
104 6.3% 37.5% 896 54.2% runtime.mallocgc
98 5.9% 43.5% 100 6.1% flushptrbuf
(pprof)main.DFS 不再出现在配置文件中,其余的程序运行时也已删除。现在,该程序将大部分时间都花在分配内存和垃圾回收上(runtime.mallocgc 既分配并运行定期垃圾回收,也占54.2%的时间)。为了找出为什么垃圾收集器运行如此之多,我们必须找出正在分配内存的内容。一种方法是向程序添加内存配置文件。我们将安排如果提供 -memprofile 标志,则程序在循环查找一次迭代后停止,写入内存配置文件并退出:
var memprofile = flag.String("memprofile", "", "write memory profile to this file")
...
FindHavlakLoops(cfgraph, lsgraph)
if *memprofile != "" {
f, err := os.Create(*memprofile)
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(f)
f.Close()
return
}我们使用 -memprofile 标志调用程序以编写配置文件:
$ make havlak3.mprof
go build havlak3.go
./havlak3 -memprofile=havlak3.mprof
$(可参阅 与 havlak2 的区别)
我们使用 go tool pprof 完全相同. 现在我们正在检查的样本是内存分配, 而不是时钟计数.
$ go tool pprof havlak3 havlak3.mprof
Adjusting heap profiles for 1-in-524288 sampling rate
Welcome to pprof! For help, type 'help'.
(pprof) top5
Total: 82.4 MB
56.3 68.4% 68.4% 56.3 68.4% main.FindLoops
17.6 21.3% 89.7% 17.6 21.3% main.(*CFG).CreateNode
8.0 9.7% 99.4% 25.6 31.0% main.NewBasicBlockEdge
0.5 0.6% 100.0% 0.5 0.6% itab
0.0 0.0% 100.0% 0.5 0.6% fmt.init
(pprof)命令 go tool pprof 报告说 FindLoops 已分配了约 86.3 MB 的使用中的 56.3 MB; CreateNode 占另外 17.6 MB。为了减少开销,内存分析器仅记录分配的每半兆字节大约一个块的信息 ("1-in-524288 采样率”),因此这些是实际计数的近似值。
为了找到内存分配, 我们可以列出这些函数.
(pprof) list FindLoops
Total: 82.4 MB
ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go
56.3 56.3 Total MB (flat / cumulative)
...
1.9 1.9 268: nonBackPreds := make([]map[int]bool, size)
5.8 5.8 269: backPreds := make([][]int, size)
. . 270:
1.9 1.9 271: number := make([]int, size)
1.9 1.9 272: header := make([]int, size, size)
1.9 1.9 273: types := make([]int, size, size)
1.9 1.9 274: last := make([]int, size, size)
1.9 1.9 275: nodes := make([]*UnionFindNode, size, size)
. . 276:
. . 277: for i := 0; i < size; i++ {
9.5 9.5 278: nodes[i] = new(UnionFindNode)
. . 279: }
...
. . 286: for i, bb := range cfgraph.Blocks {
. . 287: number[bb.Name] = unvisited
29.5 29.5 288: nonBackPreds[i] = make(map[int]bool)
. . 289: }
...看起来当前的瓶颈与最后一个瓶颈相同: 使用集合中较简单的数据结构就足够了. FindLoops 分配了约 29.5 MB 的集合.
顺带一句, 如果我们使用 --inuse_objects 标志来运行 go tool pprof, 它将报告分配计数而不是大小:
$ go tool pprof --inuse_objects havlak3 havlak3.mprof
Adjusting heap profiles for 1-in-524288 sampling rate
Welcome to pprof! For help, type 'help'.
(pprof) list FindLoops
Total: 1763108 objects
ROUTINE ====================== main.FindLoops in /home/rsc/g/benchgraffiti/havlak/havlak3.go
720903 720903 Total objects (flat / cumulative)
...
. . 277: for i := 0; i < size; i++ {
311296 311296 278: nodes[i] = new(UnionFindNode)
. . 279: }
. . 280:
. . 281: // Step a:
. . 282: // - initialize all nodes as unvisited.
. . 283: // - depth-first traversal and numbering.
. . 284: // - unreached BB's are marked as dead.
. . 285: //
. . 286: for i, bb := range cfgraph.Blocks {
. . 287: number[bb.Name] = unvisited
409600 409600 288: nonBackPreds[i] = make(map[int]bool)
. . 289: }
...
(pprof)由于 ~200,000 个集合占 29.5 MB 内存,因此看起来初始地图分配大约需要 150 个字节。当使用集合来保存键值对,这是合理的,但是当映射被用作简单集的替代者时(如此处所示),这是不合理的。
除了使用集合,我们还可以使用简单的切片来列出元素。除了使用地图的一种情况外,该算法不可能插入重复元素。在剩下的一种情况下,我们可以编写append内置函数的简单变体:
func appendUnique(a []int, x int) []int {
for _, y := range a {
if x == y {
return a
}
}
return append(a, x)
}除了编写该功能之外,更改 Go 程序以使用切片而不是集合仅需要更改几行代码。
$ make havlak4
go build havlak4.go
$ ./xtime ./havlak4
# of loops: 76000 (including 1 artificial root node)
11.84u 0.08s 11.94r 810416kB ./havlak4
$(可参阅 与 havlak3 的区别)
现在的速度比开始时快 2.11 倍。让我们再次查看 CPU 配置文件。
$ make havlak4.prof
./havlak4 -cpuprofile=havlak4.prof
# of loops: 76000 (including 1 artificial root node)
$ go tool pprof havlak4 havlak4.prof
Welcome to pprof! For help, type 'help'.
(pprof) top10
Total: 1173 samples
205 17.5% 17.5% 1083 92.3% main.FindLoops
138 11.8% 29.2% 215 18.3% scanblock
88 7.5% 36.7% 96 8.2% sweepspan
76 6.5% 43.2% 597 50.9% runtime.mallocgc
75 6.4% 49.6% 78 6.6% runtime.settype_flush
74 6.3% 55.9% 75 6.4% flushptrbuf
64 5.5% 61.4% 64 5.5% runtime.memmove
63 5.4% 66.8% 524 44.7% runtime.growslice
51 4.3% 71.1% 51 4.3% main.DFS
50 4.3% 75.4% 146 12.4% runtime.MCache_Alloc
(pprof)现在,内存分配和后续的垃圾回收 (runtime.mallocgc) 占了我们运行时间的 50.9%。查看系统为何进行垃圾收集的另一种方法是查看导致收集的分配,这些分配大部分时间花费在 mallocgc中:
(pprof) web mallocgc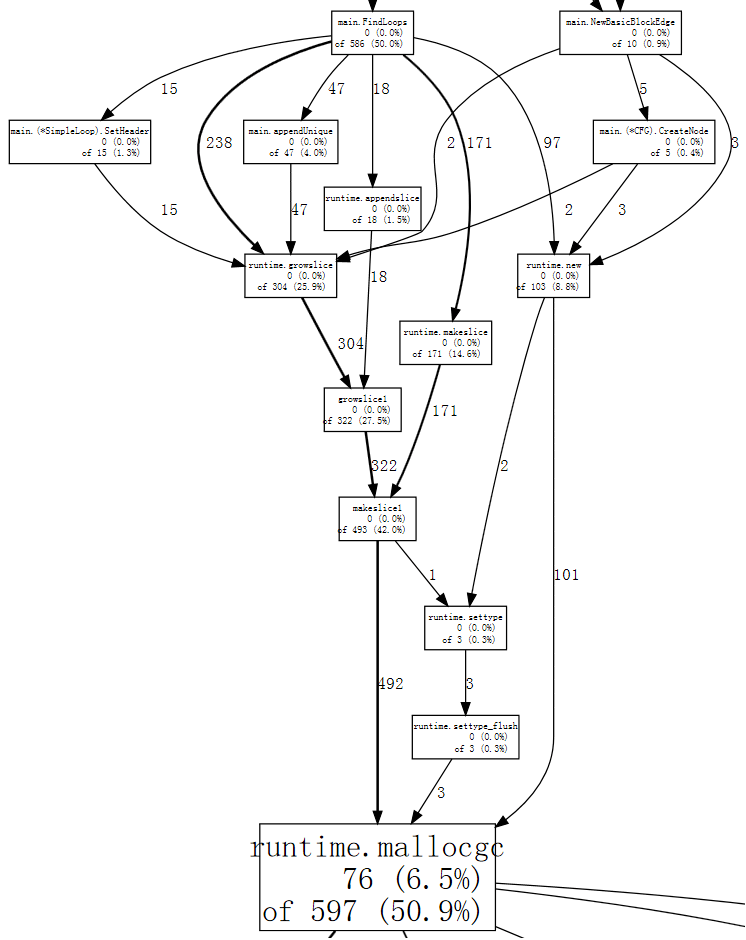
很难说出该集合中发生了什么,因为有很多节点,而小样本数却掩盖了大样本。我们可以告诉 go tool pprof 忽略那些不占样本至少10%的节点:
$ go tool pprof --nodefraction=0.1 havlak4 havlak4.prof
Welcome to pprof! For help, type 'help'.
(pprof) web mallocgc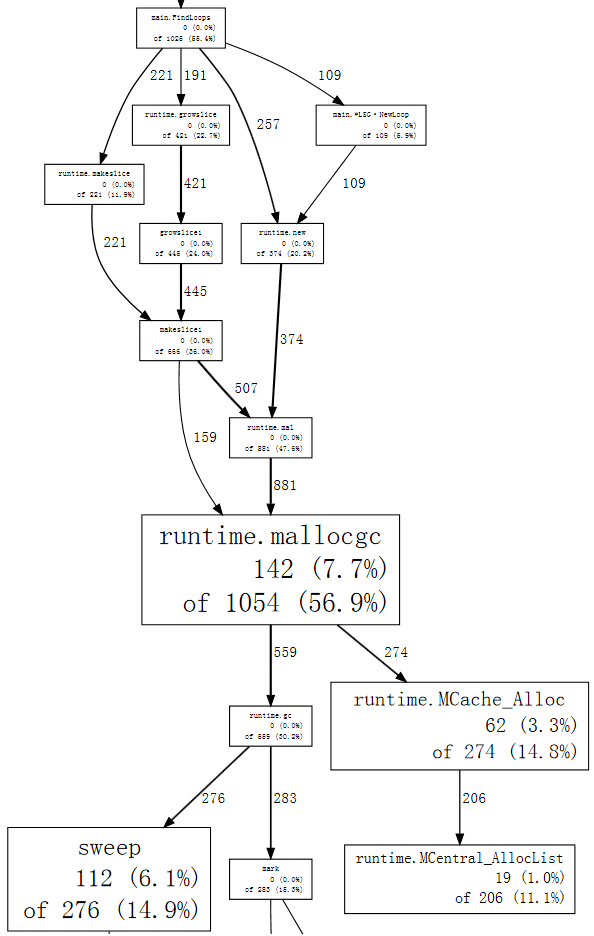
我们现在可以轻松地沿粗箭头移动,以查看 FindLoops 正在触发大多数垃圾收集。如果我们列出 FindLoops,我们可以看到其中的大部分都在开头:
(pprof) list FindLoops
...
. . 270: func FindLoops(cfgraph *CFG, lsgraph *LSG) {
. . 271: if cfgraph.Start == nil {
. . 272: return
. . 273: }
. . 274:
. . 275: size := cfgraph.NumNodes()
. . 276:
. 145 277: nonBackPreds := make([][]int, size)
. 9 278: backPreds := make([][]int, size)
. . 279:
. 1 280: number := make([]int, size)
. 17 281: header := make([]int, size, size)
. . 282: types := make([]int, size, size)
. . 283: last := make([]int, size, size)
. . 284: nodes := make([]*UnionFindNode, size, size)
. . 285:
. . 286: for i := 0; i < size; i++ {
2 79 287: nodes[i] = new(UnionFindNode)
. . 288: }
...
(pprof)每次调用 FindLoops 时,它都会分配一些可观的簿记结构。由于基准测试调用了 FindLoops 50 次,这些加起来会产生大量垃圾,因此垃圾收集器需要大量工作。
拥有垃圾收集语言并不意味着您可以忽略内存分配问题。在这种情况下,一种简单的解决方案是引入缓存,以便对 FindLoops 的每个调用在可能的情况下都重用上一个调用的存储空间。 (实际上,在 Hundt 的论文中,他解释说 Java 程序只需要进行此更改即可获得合理的性能,但是他在其他垃圾收集的实现中没有进行相同的更改。)
我们将添加全局 cache 结构:
var cache struct {
size int
nonBackPreds [][]int
backPreds [][]int
number []int
header []int
types []int
last []int
nodes []*UnionFindNode
}然后让 FindLoops 进行咨询以代替分配:
if cache.size < size {
cache.size = size
cache.nonBackPreds = make([][]int, size)
cache.backPreds = make([][]int, size)
cache.number = make([]int, size)
cache.header = make([]int, size)
cache.types = make([]int, size)
cache.last = make([]int, size)
cache.nodes = make([]*UnionFindNode, size)
for i := range cache.nodes {
cache.nodes[i] = new(UnionFindNode)
}
}
nonBackPreds := cache.nonBackPreds[:size]
for i := range nonBackPreds {
nonBackPreds[i] = nonBackPreds[i][:0]
}
backPreds := cache.backPreds[:size]
for i := range nonBackPreds {
backPreds[i] = backPreds[i][:0]
}
number := cache.number[:size]
header := cache.header[:size]
types := cache.types[:size]
last := cache.last[:size]
nodes := cache.nodes[:size]当然,这样的全局变量是不好的工程实践:这意味着并发调用 FindLoops 现在是不安全的。目前,我们正在进行尽可能小的更改,以了解对程序性能至关重要的方面。此更改很简单,并且反映了 Java 实现中的代码。 Go 程序的最终版本将使用单独的 LoopFinder 实例来跟踪此内存,从而恢复了并发使用的可能性。
$ make havlak5
go build havlak5.go
$ ./xtime ./havlak5
# of loops: 76000 (including 1 artificial root node)
8.03u 0.06s 8.11r 770352kB ./havlak5
$(可参阅 与 havlak4 的区别)
我们还可以做更多的工作来清理程序并使它更快,但是它们都不要求我们没有显示过的分析技术。内部循环中使用的工作清单可以在迭代和对 FindLoops 的调用之间重用,并且可以与在此过程中生成的单独的 "节点池" 组合。同样,循环图存储可以在每次迭代中重用,而不是重新分配。除了这些性能变化外,最终版本 是使用惯用的Go风格并使用数据结构和方法编写的。样式更改对运行时间影响很小:算法和约束条件不变。
最终版本的运行时间为 2.29 秒, 使用的内存为 351MB:
$ make havlak6
go build havlak6.go
$ ./xtime ./havlak6
# of loops: 76000 (including 1 artificial root node)
2.26u 0.02s 2.29r 360224kB ./havlak6
$这比我们开始使用的程序快 11 倍. 即使我们禁用了对生成的循环图的重用, 以便唯一的缓存内存是通过循环查找博布尔值, 程序仍然比初始版本快 6.7x 倍, 并且使用的内存少 1.5x 倍.
$ ./xtime ./havlak6 -reuseloopgraph=false
# of loops: 76000 (including 1 artificial root node)
3.69u 0.06s 3.76r 797120kB ./havlak6 -reuseloopgraph=false
$当然, 将此 Go 程序与原始 C++ 程序进行比较不再那么公平, 后者使用效率低下的数据结构, 如 set 这里用 vector 会更适合. 为了进行健全性检查, 我们将最终的 Go 程序翻译成 等效的 C++ 代码. 它的执行时间类似于 Go 程序的执行时间:
$ make havlak6cc
g++ -O3 -o havlak6cc havlak6.cc
$ ./xtime ./havlak6cc
# of loops: 76000 (including 1 artificial root node)
1.99u 0.19s 2.19r 387936kB ./havlak6ccGo 程序的运行几乎与 C++ 程序一样快. 由于 C++ 程序使用自动删除和分配而不是显式缓存, 因此 C++ 程序更短并更易编写, 但不是想象中那么容易:
$ wc havlak6.cc; wc havlak6.go
401 1220 9040 havlak6.cc
461 1441 9467 havlak6.go
$(可参阅 havlak6.cc 和 havlak6.go)
基准测试和测量的程序一样好. 我们使用了 go tool pprof 来研究效率低下的 Go 程序, 然后将其性能提高了一个量级, 并将内存使用量减少了 3.7 倍. 随后与等效优化的 C++ 程序进行比较表明, 当程序员真正注意到内部循环会产生多少无用功时, Go 可以与 C++ 一较高下.
程序源码 x86-64 二进制文件, 以及用于撰写本文的配置文件在这里 Github 上的 benchgraffiti 项目.
综上所述, go test 已包含以下概要分析标志: 定义一个 基准测试 就可以了. 还有一个用于分析数据的标准 HTTP 接口. 在 HTTP 服务器中添加
import _ "net/http/pprof"将在 /debug/pprof 下安装一些 URLs 的处理程序. 然后你就可以使用单个参数运行 go tool pprof, 它将下载并检查你的实时配置文件.
go tool pprof http://localhost:6060/debug/pprof/profile # 30-second CPU profile
go tool pprof http://localhost:6060/debug/pprof/heap # heap profile
go tool pprof http://localhost:6060/debug/pprof/block # goroutine blocking profile协程块配置文件将在以后的章节中介绍. 敬请关注.
本译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。







 关于 LearnKu
关于 LearnKu




{kind=link}
推荐文章: