
Pandas 基础 (2) - Dataframe 基础
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
上一节我们已经对 Dataframe 的概念做了一个简单的介绍, 这一节将具体看下它的一些基本用法:
首先, 准备一个 excel 文件, 大致内容如下, 并保存成 .csv 格式.
然后, 在 jupyter notebook 里执行如下代码:
#引入 pandas 模型
import pandas as pd
# 读取 csv 文件
df = pd.read_csv('weather_data.csv')
# 打印
df在 jupyter notebook 里的表现形式大概如下: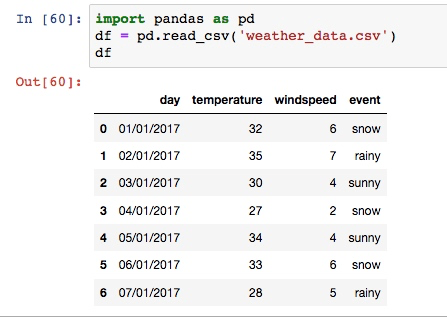
就这么简单, 我们就把一个 csv 文件转换成 dataframe 格式了. 这里大家在操作中可能遇到的一个报错就是找不到文件. 这是路径问题, 解决方法很简单, 打开你运行 jupyter 的终端窗口, 找到如下路径, 把你的 csv 文件丢进去就可以啦.
OK, 上面介绍了如何将外部文件转换成 dataframe. 下面介绍从 python dictionary 转换成 dataframe:
# python dictionary
weather_data = {
'day': ['1/1/2017', '1/2/2017', '1/3/2017', '1/4/2017', '1/5/2017', '1/6/2017'],
'temperature': [32, 35, 27, 25, 24, 30],
'windspeed': [6, 7, 2, 5, 4, 6],
'event': ['Rain', 'Sunny', 'Snow', 'Snow', 'Rain', 'Sunny']
}
# 转换
df = pd.DataFrame(weather_data)
打印
df运行结果: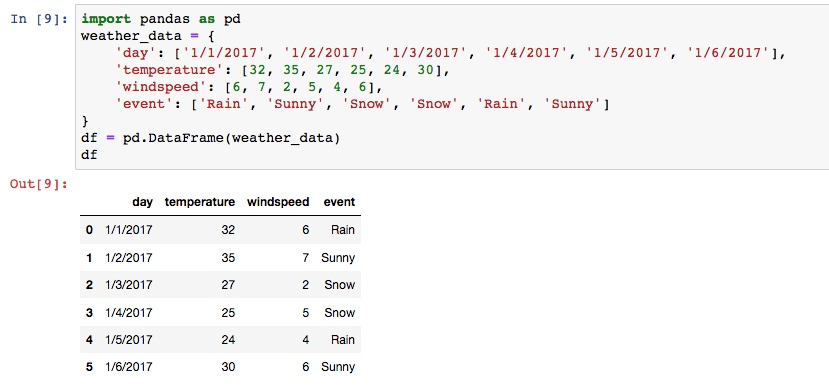
可以说, 两种方式都非常的简便, 下面就基于上面的数据看一下 dataframe 有哪些属性可以供我们使用.
df.shape输出:
(6, 4)
这里是查看这个 dataframe 的行数和列数, 显然, 我们这个例子中, 有 6 行, 4 列. 那么我们还可以把这个结果同时赋值给两个变量, 再分别查看这两个变量的值:
rows, columns = df.shape
rows输出:
6
columns输出:
4
# 查看前5行数据
df.head()
# 查看后5行数据
df.tail()
# 查看后 3 行数据
df.tail(3)
# 查看 第 2,3,4 行的数据
df[2:5]
# 查看所有数据
df[:]
# 查看所有列
df.columns
# 查看某一列方法一, 只适用于列名中间没有空格的
df.day
# 查看某一列方法二, 适用于所有列名
df['event']
# 查看某一列的类型, 这里输出的结果是 pandas.core.series.Series, 表示每一列都是一个 series
type(df['event'])
# 查看两个列以上的数据, 注意这里要用两个中括号
df[['event', 'day']]以上就是 dataframe 的一些基本属性. 下面介绍一些操作命令
# 求某一列里的最大值
df['temperature'].max()
# 求某一列的平均值
df.temperature.mean()
# 查看 temperature 大于 30 的数据
df[df.temperature>30]
# 查看 temperature 等于最大值的数据
df[df.temperature==df.temperature.max()]
# 只查看 temperature 等于最大值的日期, 有下面两种写法
df['day'][df.temperature==df.temperature.max()]
df.day[df.temperature==df.temperature.max()]
# 查看 temperature 等于最大值的日期和温度
df[['day', 'temperature']][df.temperature==df.temperature.max()]
# 查看目前的索引
df.index
# 设置索引, 这里注意必须加上第二个参数, 以确保真正更改到 df 的索引
df.set_index('day', inplace=True)
# 基于上面把 'day' 设为索引, 就可以具体查看某一行的数据
df.loc['1/4/2017']
# 重置索引
df.reset_index(inplace=True)
# 把索引设置为 'event', 这里要说明两个问题, 第一, 更新索引必须在重置索引的前提下, 否则 'day'列就消失了, 第二, 任何列都可以被设置为索引
df.set_index('event', inplace=True)最后再介绍一个命令, 这里就是会输出所有数字内容的列, 并且罗列出一些基本常用的运算结果.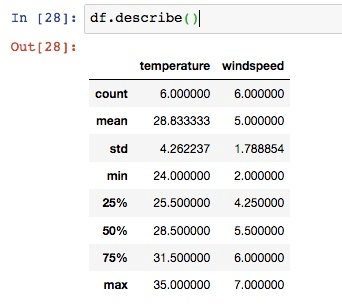
OK, 以上就是对 dataframe 的基本用法的介绍.
大家如果有任何问题或者意见或者不同看法, 欢迎留言呦. 期待跟大家一起学习讨论.
See you!!!
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



