
Machine Learning(16) - 关于 K Means Clustering 的练习题
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
题目
取 Iris 花 petal 花瓣的 width 和 height 作为数据集,用 Unsupervised 的方法将其做分类,然后与其 target 的值做对比,以检验分类的结果是否正确。
解题
引入需要的包和数据集
import pandas as pd
from sklearn import datasets
// 引入 iris 数据
iris = datasets.load_iris()
// 查看 Iris 的属性
dir(iris)
// 输出
['DESCR', 'data', 'feature_names', 'filename', 'target', 'target_names']把 iris 数据转为 dataframe
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df.head()输出:
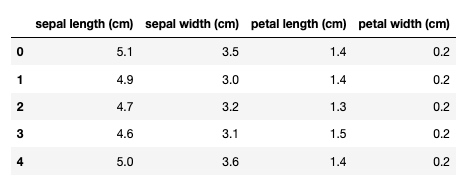
去掉不需要的字段
df.drop(['sepal length (cm)', 'sepal width (cm)'], axis='columns', inplace=True)
df.head()输出:
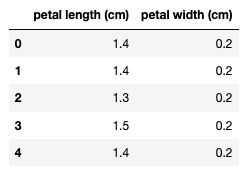
以图表的形式输出目标数据集
from matplotlib import pyplot as plt
plt.scatter(df['petal length (cm)'], df['petal width (cm)'])输出:
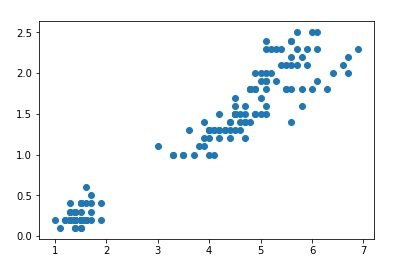
求出最佳 K 值
from sklearn.cluster import KMeans
k_rng = range(1, 10)
sse = []
for k in k_rng:
km = KMeans(n_clusters=k)
km.fit_predict(df[['petal width (cm)', 'petal length (cm)']])
sse.append(km.inertia_)
sse
// 输出
[550.8953333333334,
86.39021984551397,
31.371358974358973,
19.48300089968511,
13.916908757908757,
11.03633387775173,
9.191170634920635,
7.672362403043182,
6.456494541406307]
plt.xlabel('K')
plt.ylabel('SEE')
plt.plot(k_rng, sse)输出:
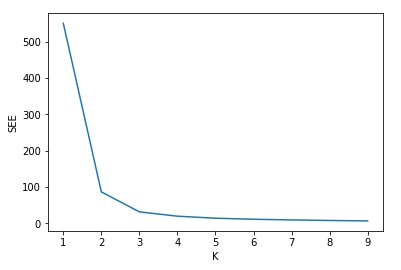
通过上面的分析,将数据集分成 3 份
km = KMeans(n_clusters=3)
km
// 输出
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
cluster = km.fit_predict(df[['petal width (cm)', 'petal length (cm)']])
df['cluster'] = cluster
df.head()输出:
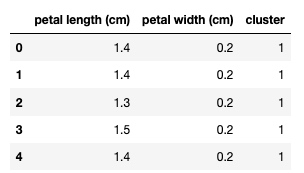
df1 = df[df.cluster == 0]
df2 = df[df.cluster == 1]
df3 = df[df.cluster == 2]
plt.scatter(df1['petal length (cm)'], df1['petal width (cm)'], color = 'red')
plt.scatter(df2['petal length (cm)'], df2['petal width (cm)'], color = 'blue')
plt.scatter(df3['petal length (cm)'], df3['petal width (cm)'], color = 'green')输出:
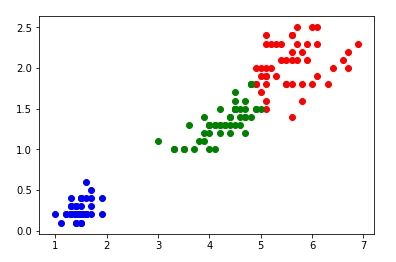
与数据集原本的 target 对比,查看分类是否正确
df_new = pd.DataFrame(iris.data, columns = iris.feature_names)
df_new['target'] = iris.target
df_new.drop(['sepal length (cm)', 'sepal width (cm)'], axis = 'columns', inplace=True)
df_new.head()输出
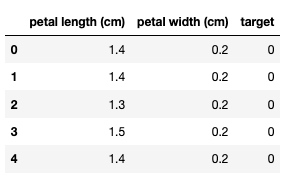
df_new1 = df_new[df_new.target == 0]
df_new2 = df_new[df_new.target == 1]
df_new3 = df_new[df_new.target == 2]
plt.scatter(df_new1['petal length (cm)'], df_new1['petal width (cm)'], color='red')
plt.scatter(df_new2['petal length (cm)'], df_new2['petal width (cm)'], color='blue')
plt.scatter(df_new3['petal length (cm)'], df_new3['petal width (cm)'], color='green')下面是用数据集原本的 target 做的分类,与我们上面用 unsupervised 的方法得到的结果是一致的:
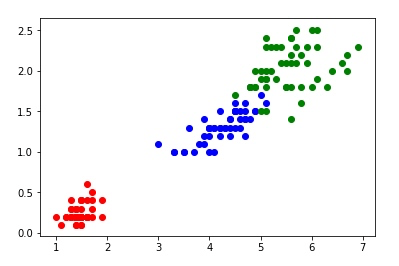
以上,是对练习题的解题,因为上一小节已经对每步操作都做了详细的解释,所以这里没有过多重复,单纯贴上解题过程,如果有不明白的,可以查看上节的说明。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: