
Machine Learning(14) - K Fold Cross Validation
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
引言
我们前面学了那么多种 Machine Learning 的模型,那么当我们拿到一个具体问题的时候,难免就会有疑惑,我究竟用哪个模型才是合适的呢?这节要讲的 Cross Validation 就是用来解决这个问题的,它可以用来评估模型的表现。
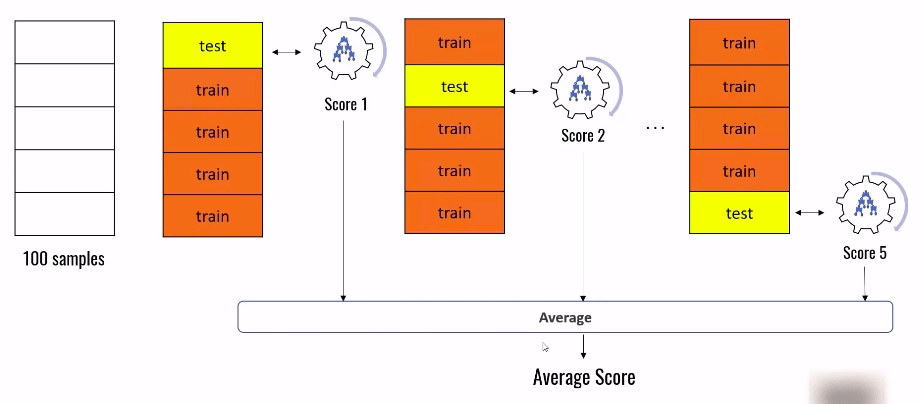
K Fold Cross Validation 的工作原理就是将一个数据集分成 K 份,遍历 这 K 份数据,每次都是用其中的 1 份做测试,剩下的 K-1 份训练数据,然后将每次求得的 score 取平均值。
正文
下面我们就以 ”手写数字“ 的数据集为例,看下具体用法:
引入数据集
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits()分别用 3 中模型处理模型,并测试其准确度
from sklearn.model_selection import train_test_split
// 将数据集分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.3)
lr = LogisticRegression()
lr.fit(X_train, y_train)
lr.score(X_test, y_test) // 输出模型准确度 0.9592592592592593
svm = SVC()
svm.fit(X_train, y_train)
svm.score(X_test, y_test) // 输出模型准确度 0.5074074074074074
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
rf.score(X_test, y_test) // 输出模型准确度 0.9481481481481482这里要说明的是,train_test_split() 函数对测试数据和训练数据的分配是随机的,也就是说没执行一次,得到的分类都会不同。数据的不同,也会直接影响到模型的表现。
这里大家可以尝试多执行几次
train_test_split()函数,会发现score的值都会有所变化。
K fold
下面就引入我们上面所说的 K Fold 的概念:
from sklearn.model_selection import KFold
kf = KFold(n_splits = 3) // 会将处理的数据集分成 3 份
kf
// 输出
KFold(n_splits=3, random_state=None, shuffle=False)
// 先用一个简单的数组做例子,来开下 KFold() 函数的效果
for train_index, test_index in kf.split([1, 2, 3, 4, 5, 6, 7, 8, 9]):
print(train_index, test_index)
// 输出
[3 4 5 6 7 8] [0 1 2]
[0 1 2 6 7 8] [3 4 5]
[0 1 2 3 4 5] [6 7 8]以上输出可以清楚地看出 KFold() 函数的作用,因为我们设置了参数 n_splits=3,所以它将数据平均地分成 3 份,每一份的数据组合都是不同的,并且保证每个数字都有出现在前后两个数组(训练数据集和测试数据集)中的机会。
定义模型准确度的函数
下面我们把测试模型,测试模型的过程封装成函数,方便后面使用:
def get_score(model, X_train, X_test, y_train, y_test):
model.fit(X_train, y_train)
return model.score(X_test, y_test)用手写数字集正式操练
这里引用的是 StratifiedKFold,它的本质功能同前面的 KFold,区别是它在将数据分组的时候,会将数据打乱来分,准确性更高。
from sklearn.model_selection import StratifiedKFold
folds = StratifiedKFold(n_splits = 3)
// 为 3 个模型的预测值创建 3 个数组
scores_l = []
scores_svm = []
scores_rf = []
// 把手写数字的数据集分成 3 份,然后遍历 3 次
for train_index, test_index in folds.split(digits.data, digits.target):
// 取出每一次的训练数据和测试数据
X_train, X_test, y_train, y_test = digits.data[train_index], digits.data[test_index], digits.target[train_index], digits.target[test_index]
// 把每一次得出模型准确度的值放进对应的数组
scores_l.append(get_score(LogisticRegression(), X_train, X_test, y_train, y_test))
scores_svm.append(get_score(SVC(), X_train, X_test, y_train, y_test))
scores_rf.append(get_score(RandomForestClassifier(n_estimators = 40), X_train, X_test, y_train, y_test))
// 输出每种模型的准确度值的数组
scores_l
// 输出
[0.8964941569282137, 0.9515859766277128, 0.9115191986644408]
scores_svm
// 输出
[0.41068447412353926, 0.41569282136894825, 0.4273789649415693]
scores_rf
// 输出
[0.9398998330550918, 0.9449081803005008, 0.9131886477462438]用 cross_val_score 函数轻松实现
以上复杂的操作过程,其实是在讲 cross_val_score 的实现原理,实际上,我们用 cross_val_score 就可以轻松实现上面的过程:
from sklearn.model_selection import cross_val_score
cross_val_score(LogisticRegression(), digits.data, digists.target)
// 输出
array([0.89534884, 0.94991653, 0.90939597])
cross_val_score(SVC(), digits.data, digists.target)
// 输出
array([0.39368771, 0.41068447, 0.45973154])
cross_val_score(RandomForestClassifier(n_estimators = 40), digits.data, digists.target)
// 输出
array([0.93189369, 0.94156928, 0.92281879])使用 cross_val_score 不仅可以轻松测试每个模型的准确度,还可以对某个模型进行参数微调,比如上面对 RandomForestClassifier,就可以给它增加参数 n_estimators = 40 来调节它的准确度。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



