
酷帅吊炸天的 Pandas 常用操作命令汇总
0 / 3 / 创建于 6年前 /
 Rachel 的个人博客
Rachel 的个人博客
非常庆幸自己在有意无意中学习了 Pandas 基础,开始学的时候是觉得它很有意思,功能很强大。然鹅,除了做练习,并没有实际应用。最近工作需要写爬虫,数据处理我就用了 Pandas, 这时才深深体会到其酷帅吊炸天的威力,一句话,只有我用不到的功能,没有它不支持的功能,函数多到爆,每个函数又有辣么多的参数可以用,感动到哭晕在厕所。。。。。。
所以除了之前整理的一些用法,我把这次工作中学到的新函数和用法整理如下:
查看 dataframe 信息,可以查看每一列的具体信息:
df.info()删除 NaN 所在的行:
删除表中全部为 NaN 的行
df.dropna(axis=0,how='all') 删除表中含有任何 NaN 的行
df.dropna(axis=0,how='any') #drop all rows that have any NaN values删除NaN所在的列:
删除表中全部为 NaN 的列
df.dropna(axis=1,how='all') 删除表中含有任何 NaN 的列
df.dropna(axis=1,how='any') #drop all rows that have any NaN values去掉值不合适的行
首先把值改为 NaN, 注意,这里需要先引入 numpy
df.content= df.content.replace({'<p></p>': np.NaN}, regex=True)然后再把值有 NaN 的行删掉
df = df.dropna(axis=0,how='any') 删除所有含有某个字符的行
df=df[ ~ df['price'].str.contains('-')] 更改某一列字符串的部分值
df.piclist= df.piclist.replace({'/uploads': 'http://www.zgmlxc.com.cn/uploads'}, regex=True)
df.head()效果: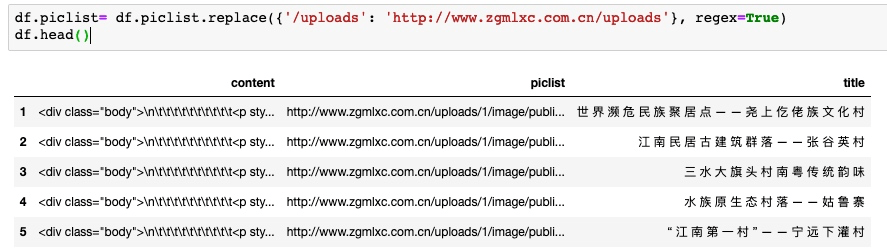
截取字符串的部分值
df["litpic"]= df["piclist"].str.split(",", n=0, expand = True)[0]通过 str.split 函数将字符串按逗号分隔,然后取其中第0列的值
修改某一列的数据类型
df[['price']] = df[['price']].astype(float)模糊更改某一列中还有某个字符的值
df['kind'].loc[df['kind'].str.contains('蛋', na=False)] = 46如上,是更改 kind 列中,把含有 "蛋” 的字符都改为 46,其中, na=False 参数表示忽略 NaN
明确批量更改某一列的值
df.category= df.category.replace({'禽畜肉蛋': 36, '水果':35, '粮油米面': 6, '种子种苗':69, '苗木花草': 69, '农资农机': 54, '水产': 52, '蔬菜': 35}, regex=True)合并列
## 先把列中的整数转为字符串
df['category'] = df['category'].map(lambda x:str(x))
df['kind'] = df['kind'].map(lambda x:str(x))
## 合并
df['attrid'] = df['category'].str.cat(df['kind'], sep=',')数据筛选
必须同时满足条件
outfile = df1[(df1[u'设计井别']=='11') & (df1[u'投产井别']=='11') &(df1[u'目前井别']=='11')]满足其一即可的筛选
outfile = df1[(df1[u'设计井别']=='11') | (df1[u'投产井别']=='11') | (df1[u'目前井别']=='11')]删除 appID 为 278 和 382,以及 appPlatform 为 2 的行
df[(True-df['appID'].isin([278,382]))&(True-df['appPlatform'].isin([2]))]删除 ‘成交金额’ 大于 1000 的行
df[df['成交金额'] > 10000]本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




df.dropna(axis=0,how='all')这个命名很怪,为什么不叫dropNa@lovecn 的确, 各种命名形式混着来, 还比如 isin, astype.
这里解释说是遵循 python 的命名规范:
https://stackoverflow.com/questions/414990...
df.content= df.content.replace({'
': np.NaN}, regex=True) 有content这个方法吗?