
Machine Learning(13)- Random Forest
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
引言

Random Forest Algorithm 是另一个非常流行的 Machine Learning 技术,主要应用于 Regression 和 Classication.
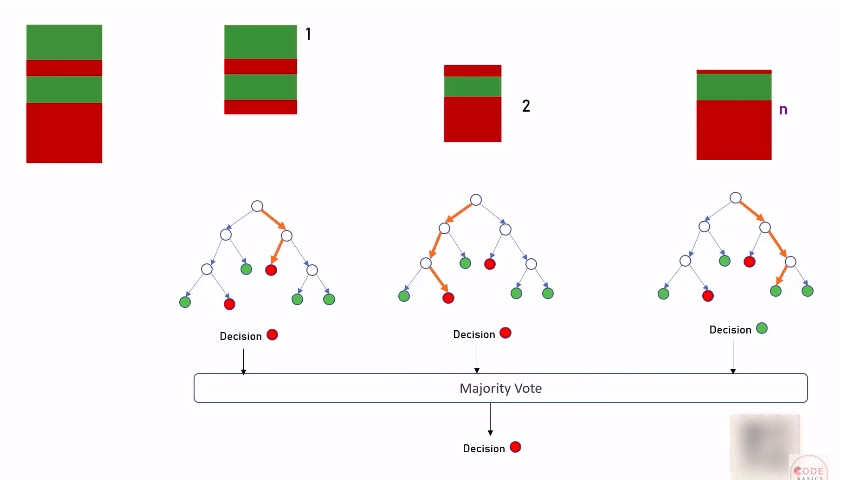
Random Forest 的名字其实是来自于上一节学习的 Decision Tree,它是基于一个数据集, 根据不同的规则划分, 一级一级创建成一颗树的形式.
这里要学的 Random Forest 的内在实现就是把一个数据集拆分成 n 个 tree, n 是可以调节的参数, 用以创建更准确的模型。
正文
引入数据集
下面以手写数字的分类为例,来学习 Random Forest
from sklearn.datasets import load_digits
digits = load_digits()拆分测试数据和训练数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size = 0.2)用 RandomForest 训练模型
// 引入 RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=40)
model.fit(X_train, y_train)
// 输出
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=40, n_jobs=None,
oob_score=False, random_state=None, verbose=0,
warm_start=False) 查看模型准确度
可以通过微调参数寻找更好的准确度, 参数 n_estimators 就是代表分多少棵树来创建模型。
model.score(X_test, y_test) // 0.9805555555555555本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



