
Pandas 基础 (9) - 组合方法 merge
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
首先, 还是以天气为例, 准备如下数据:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'temperature': [21, 24, 32],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')输出:
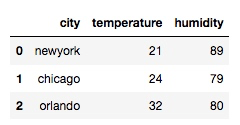
上面的例子就是以 'city' 为基准对两个 dataframe 进行合并, 但是两组数据都是高度一致, 下面调整一下:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'humidity': [89, 79, 80],
})
df = pd.merge(df1, df2, on='city')输出:
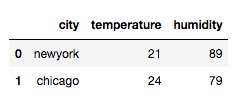
从输出我们看出, 通过 merge 合并, 会取两个数据的交集.
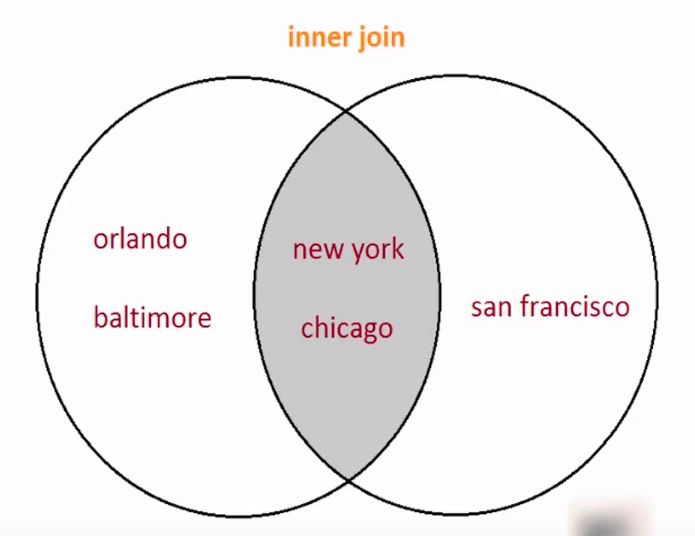
那么, 我们应该可以设想到, 可以通过调整参数, 来达到不同的取值范围.
取并集:
df = pd.merge(df1, df2, on='city', how='outer')输出:
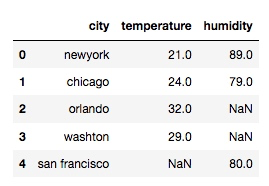
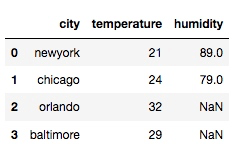
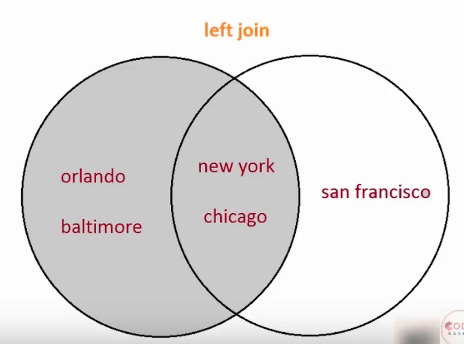
左对齐:
df = pd.merge(df1, df2, on='city', how='left')输出:
右对齐:
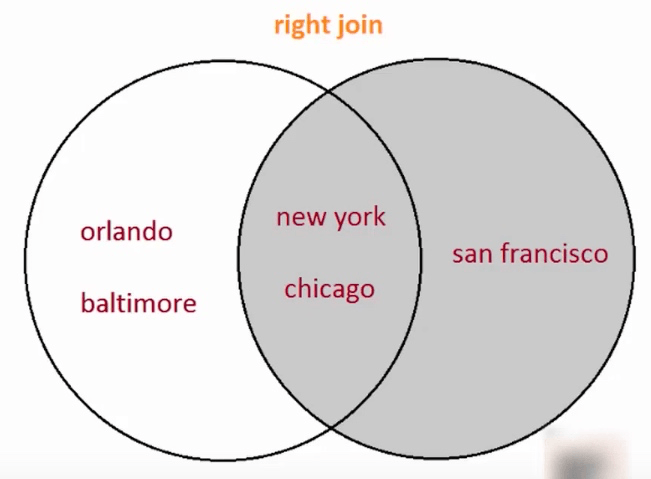
df = pd.merge(df1, df2, on='city', how='right')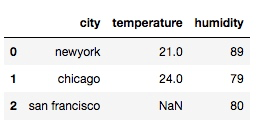
另外, 在我们取并集的时候, 我们有时可能会想要知道, 某个数据是来自哪边, 可以通过 indicator 参数来获取:
df = pd.merge(df1, df2, on='city', how='outer', indicator=True)输出:
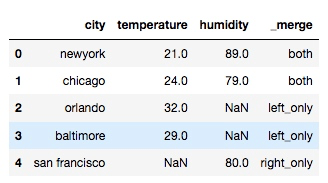
在上面的例子中, 被合并的数据的列名是没有冲突的, 所以合并的很顺利, 那么如果两组数据有相同的列名, 又会是什么样呢? 看下面的例子:
df1 = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando', 'baltimore'],
'temperature': [21, 24, 32, 29],
'humidity': [89, 79, 80, 69],
})
df2 = pd.DataFrame({
'city': ['newyork', 'chicago', 'san francisco'],
'temperature': [30, 32, 28],
'humidity': [80, 60, 70],
})
df = pd.merge(df1, df2, on='city')输出:

我们发现, 相同的列名被自动加上了 'x', 'y' 作为区分, 为了更直观地观察数据, 我们也可以自定义这个区分的标志:
df3 = pd.merge(df1, df2, on='city', suffixes=['_left', '_right'])输出:

以上, 就是关于 merge 合并的相关内容。
注:Panas 系列 均是参考 Pandas Time Series Analysis 系列教程,个人觉得讲得很好。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



