
Pandas 基础 (10) - Pivot table 做格式转换
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
Pivot allows you to transform or reshape data.
Pivot 可以帮助我们改变数据的格式, 如下图:
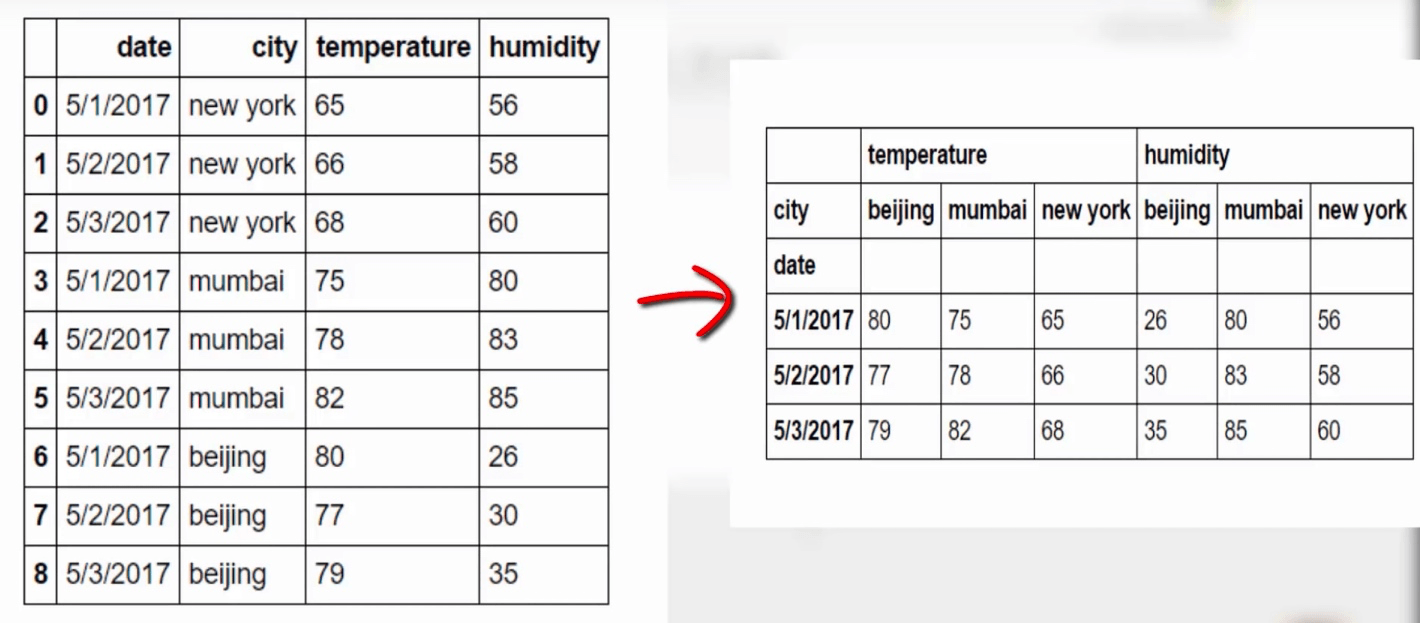
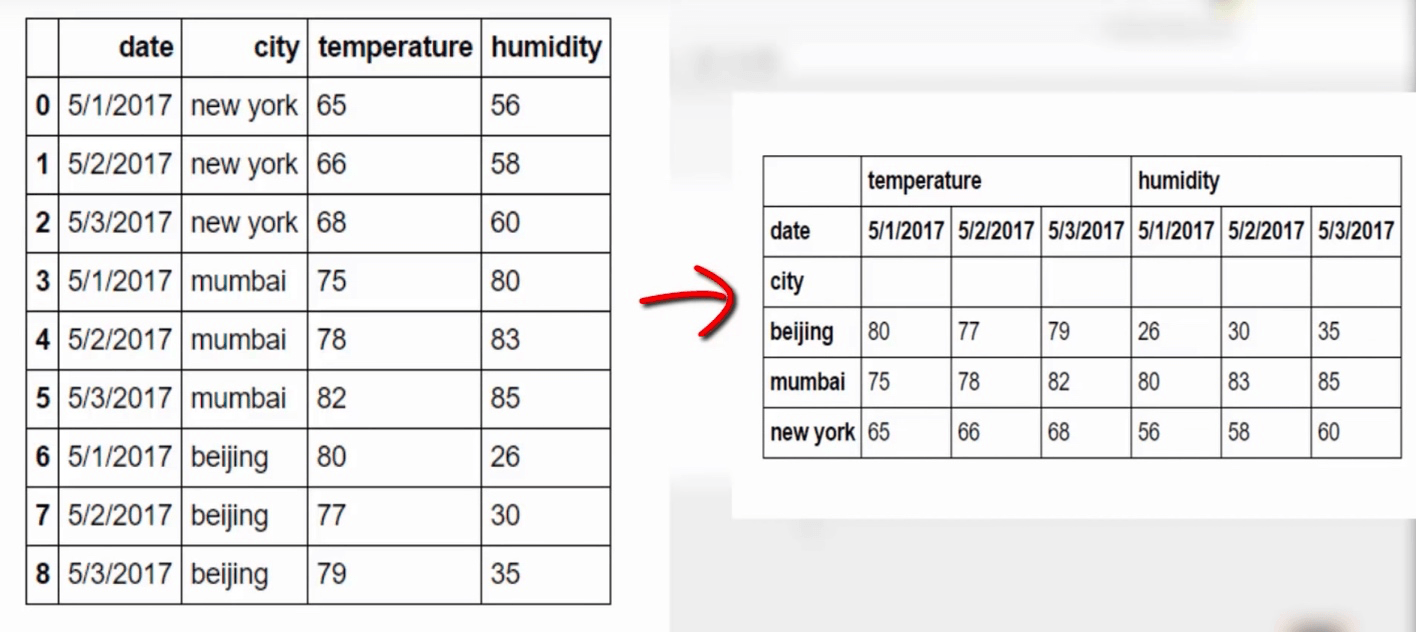
具体实现, 首先引入一个 csv 文件:
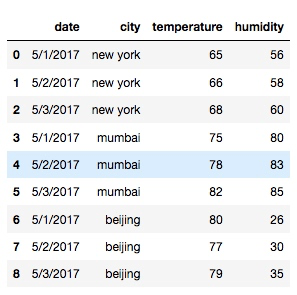
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/10_pivot/weather.csv')输出:
格式转换, 设置 'date' 为索引列, 也就让'date' 做每一行的输出依据, 然后设置'city' 为每一列输出的依据:
df.pivot(index='date', columns='city')还可以给出第三个参数, 指定输出的内容:
df.pivot(index='date', columns='city', values='humidity')下面来看下 pivot table:
pivot table is used to summarize and aggregate data inside dataframe.
pivot table 可以用来很好地总结整合数据. 下面通过一个例子来看一下:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/10_pivot/weather2.csv')输出:
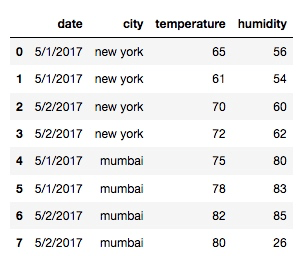
从这个输出可以看出目前的数据结构很乱, 这时, 我们就可以用 pivot table 来做整合:
df.pivot_table(index='city', columns='date')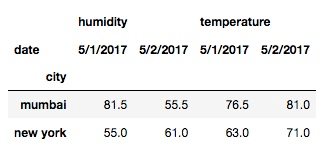
从结果可以看出, 这样整合之后, 取的是每天每个城市每个事件的平均值.
对于 pivot_table() 函数, 我们还可以通过第三个参数 'aggfun' 来做很多的变化, 下面分别来看下:
取和:
df.pivot_table(index='city', columns='date', aggfunc='sum')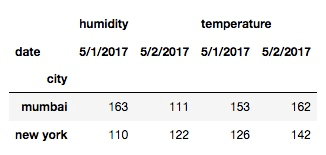
取数据的条数:
df.pivot_table(index='city', columns='date', aggfunc='count')求差异:
df.pivot_table(index='city', columns='date', aggfunc='diff')求平均值, 其实如果不加这个参数, 默认也是求平均值:
df.pivot_table(index='city', columns='date', aggfunc='mean')横向纵向分别求和的平均值:
df.pivot_table(index='city', columns='date', margins=True)最后一点, 对数据进行分组整理:
首先, 引入一个文件做例子:
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/10_pivot/weather3.csv')输出:
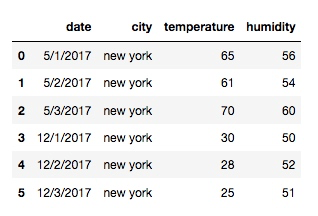
然后, 我们想实现的是把数据按照月份分组:
df.pivot_table(index=pd.Grouper(freq='M', key='date'), columns='city')但是按照上面的代码运行, 会报错, 提示 'date' 列不是时间格式, 所以需要先把'date' 列的格式改成时间:
df['date'] = pd.to_datetime(df['date'])最后输出结果:
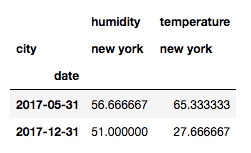
以上就是关于 pivot 的常用方法.
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



