
Machine Learning (1) - Linear Regression
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
Pandas 是学习 Machine Learning 的利器,这里假设你已经对 Pandas 基础 有所了解。
这一节主要以预测一个地区的房价为例,学习 ML 的模型之一 Linear Regression:
1. 引入需要用的包以及数据文件
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/1_linear_reg/homeprices.csv')
df输出:
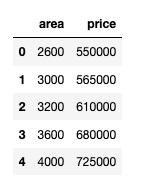
2. 训练 Linear Regression 模型
reg = linear_model.LinearRegression() // 初始化数据模型
// 训练这个模型,第一个参数是已知的数据,第二个参数是未来要预测的值
reg.fit(df[['area']], df.price) 现在就可以用模型来预测值
reg.predict([[5000]])输出:
array([859554.79452055])这里大概介绍一下 Linear Regression 的建模公式:
y = m * x + b
m 和 b 就是模型的系数, 通过提供大量的 x 和 y 的值,来求出最佳的 m 和 b 的值,这也就是训练模型的过程。
m 被称作 Coefficients
b 被称作 Intercept
通过下面两个命令就可以查看 Linear Regression 模型的 m 和 b 的值:reg.coef_ // m 的值 reg.intercept_ // b 的值
3. 输出图形数据:
%matplotlib inline
plt.xlabel('area(sqr ft)', fontsize=20) // x 轴
plt.ylabel('price(US$)', fontsize=20) // y 轴
plt.scatter(df.area, df.price, color='red', marker='+') // 以 “点” 输出已知数据
plt.plot(df.area, reg.predict(df[['area']]), color='blue') // 以 “线” 输出预测的数据,第二个参数是根据模型预测的值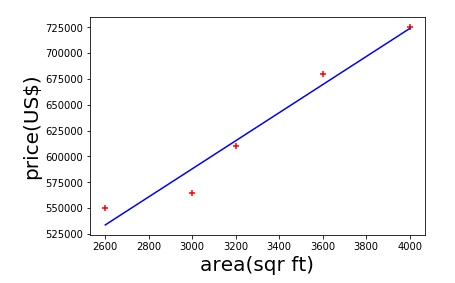
上面这条线,就是我们最终得到的 Linear Regression 模型,得到这条线,我们就可以轻松预测任何尺寸的房价,也就相当于模型训练完成。
4. 应用模型
下面就用前面训练好的模型来快速预测房价:
先建一个新的 csv 文件,里面填充一些房子的面积值:
df_new = pd.read_csv('/Users/rachel/Sites/py-master/ML/1_linear_reg/areas.csv')
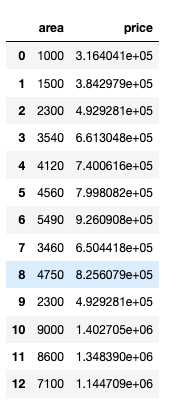
df_new.head()输出(大家可以按照这个输出格式,随便建一个侧表来做测试):

用训练好的模型 reg 做房价预测
p = reg.predict(df_new[['area']])
p
// 输出
array([ 316404.10958904, 384297.94520548, 492928.08219178,
661304.79452055, 740061.64383562, 799808.21917808,
926090.75342466, 650441.78082192, 825607.87671233,
492928.08219178, 1402705.47945205, 1348390.4109589 ,
1144708.90410959])
// 用预测出来的房价数据完善原表
df_new['price'] = p
df_new
// 输出完善好的数据到 prediction.csv 文件
//至于这个文件生成在哪里, 还是去终端看下, 你此时的 jupyter notebook 运行在哪里
df_new.to_csv('prediction.csv', index = False)输出:
今天开始第二次机器学习,对一些知识点有了更深入的了解,把之前的笔记完善一下。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



