
Machine Learning (3) - 介绍两种保存和读取模型的方式
0 / 0 / 创建于 7年前 /
 Rachel 的个人博客
Rachel 的个人博客
引言
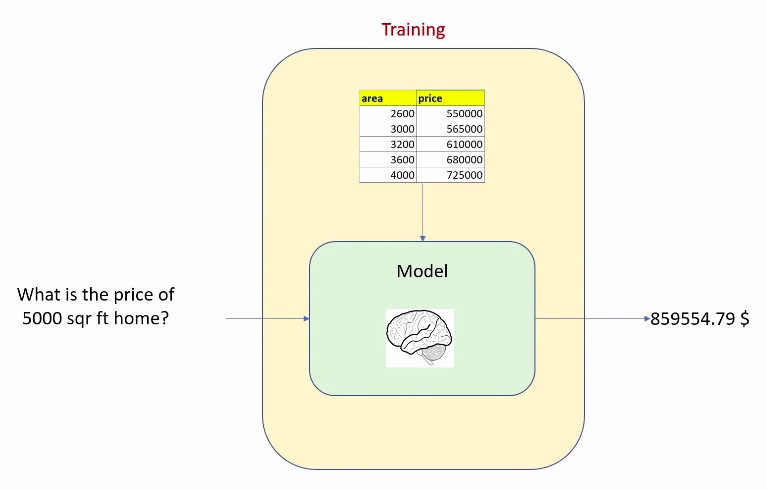
Machine Learning 两步曲:
- 训练模型
- 用训练好的模型帮助我们解决问题
在实际应用中,模型训练需要大量的数据。这个训练过程也许会花费比较多的时间。所以,一旦训练好以后,就需要把它 保存 起来,方便后面随时调用。
保存模型的两种方式
保存模型的方式有两种,分别是 pickle 和 sklearn joblib。
准备模型
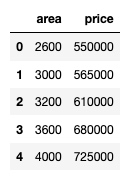
引入数据
import pandas as pd
df = pd.read_csv('/Users/rachel/Downloads/py-master/ML/1_linear_reg/homeprices.csv')
df输出:
训练模型
model = linear_model.LinearRegression()
model.fit(df[['area']], df.price)
// 用模型进行预测
model.predict([[3500]])用 pickle 保存模型
// 引入包
import pickle
// 将模型写入 model_pickle 文件
with open('model_pickle', 'wb') as f:
pickle.dump(model, f)
// 从 model_pickle 文件中读取模型
with open('model_pickle', 'rb') as f:
mp = pickle.load(f)
// 用模型进行预测
mp.predict([[3500]])用 sklearn joblib 保存模型
// 引入包
from sklearn.externals import joblib
// 将模型写入 model_joblib 文件
joblib.dump(model, 'model_joblib')
// 从 model_joblib 文件中读取模型
mj = joblib.load('model_joblib')
// 用模型进行预测
mj.predict([[3500]])本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



