
Pandas 基础 (18) - Period and PeriodIndex
0 / 0 / 创建于 7年前
 Rachel 的个人博客
Rachel 的个人博客
这节依然是时间相关的知识, 前面是侧重于时间点的一些方法, 这节要介绍的是关于时间段的相关知识.
创建一个 period 对象:
import pandas as pd
y = pd.Period('2016')
y输出:
Period('2016', 'A-DEC')A 代表 Annual | 年度的
DEC 代表 December | 12月
整体表示已经创建了一个 2016年的时间段对象, 并赋值给变量 y, 现在就可以调用这个对象的方法:
求2016年的起始时间:
y.start_time输出:
Timestamp('2016-01-01 00:00:00')2016年的结束时间:
y.end_time输出:
Timestamp('2016-12-31 23:59:59.999999999')创建 2019年1月的时间段对象, 注意, 这里具体到月份了:
m = pd.Period('2019-01')
m输出:
Period('2019-01', 'M')求 2019年1月的起始时间:
m.start_time输出:
Timestamp('2019-01-01 00:00:00')2019年1月的结束时间:
m.end_time输出:
Timestamp('2019-01-31 23:59:59.999999999')还可以对月份做加减操作:
m + 1输出:
Period('2019-02', 'M')从2019年1月往后推12个月:
m + 12 输出:
Period('2020-01', 'M')从输出可以看出 Pandas 对日历的精准掌握.
创建以天为单位的时间段对象:
d = pd.Period('2019-2-12')
d输出:
Period('2019-02-12', 'D')查看起始时间:
d.start_time输出:
Timestamp('2019-02-12 00:00:00')查看结束时间:
d.end_time输出:
Timestamp('2019-02-12 23:59:59.999999999')对天进行加运算:
d + 3输出:
Period('2019-02-15', 'D')创建以小时为单位的时间段对象:
h = pd.Period('2019-2-12 23')
h输出:
Period('2019-02-12 23:00', 'H')这里插播一条意外, 如果我按照如下格式写时间:
h = pd.Period('2019-2-12 23:09:7')
h得到的就是以秒为单位的时间段对象:
Period('2019-02-12 23:09:07', 'S')那么如果我固执地还想要以小时为单位的时间段对象呢? 那么就可以用参数 freq 的值加以限制:
h = pd.Period('2019-2-12 23:09:7', freq='H')
h这样就得到了以小时为单位的时间段对象:
Period('2019-02-12 23:00', 'H')同样可以进行加减运算:
h+3输出:
Period('2019-02-13 02:00', 'H')也可以用这种方式推移时间, 得到效果跟加运算是一样的:
h+pd.offsets.Hour(3)输出:
Period('2019-02-13 02:00', 'H')我们在做数据分析的时候还经常遇到以季度为时间节点的分析需求, 我们可以这样创建以季度为单位的时间段对象:
q = pd.Period('2019Q1')
q输出:
Period('2019Q1', 'Q-DEC')同样可以进行加减运算:
q+1输出:
Period('2019Q2', 'Q-DEC')查看起始时间:
q.start_time输出:
Timestamp('2019-01-01 00:00:00')查看结束时间:
q.end_time输出:
Timestamp('2019-03-31 23:59:59.999999999')通过上面的方式查看的起始时间和结束时间都是精确到秒的, 但是从实际的角度出发, 通常我们如果需要按季度做一些分析, 应该只要精确到月就可以了, 可以通过如下方式做转换:
q.asfreq('M', how='start')输出:
Period('2019-01', 'M')以及精确到月的结束时间:
q.asfreq('M', how='end')输出:
Period('2019-03', 'M')以季度为单位创建时间段对象:
idx = pd.period_range('2011', '2018', freq='Q')
idx输出:
PeriodIndex(['2011Q1', '2011Q2', '2011Q3', '2011Q4', '2012Q1', '2012Q2',
'2012Q3', '2012Q4', '2013Q1', '2013Q2', '2013Q3', '2013Q4',
'2014Q1', '2014Q2', '2014Q3', '2014Q4', '2015Q1', '2015Q2',
'2015Q3', '2015Q4', '2016Q1', '2016Q2', '2016Q3', '2016Q4',
'2017Q1', '2017Q2', '2017Q3', '2017Q4', '2018Q1'],
dtype='period[Q-DEC]', freq='Q-DEC')这样活得的就是一个 list, 其中的每个元素都是一个 period 对象, 因此都可以调用我们之前所讲到的方法, 比如起始时间:
idx[0].start_time输出:
Timestamp('2011-01-01 00:00:00')以及结束时间:
idx[0].end_time输出:
Timestamp('2011-03-31 23:59:59.999999999')period_range() 函数还可以通过如下方式传参, 以设定取值范围:
idx = pd.period_range('2011', periods=10, freq='Q')
idx输出:
PeriodIndex(['2011Q1', '2011Q2', '2011Q3', '2011Q4', '2012Q1', '2012Q2',
'2012Q3', '2012Q4', '2013Q1', '2013Q2'],
dtype='period[Q-DEC]', freq='Q-DEC')继续, 看下面这个例子:
import numpy as np
ps = pd.Series(np.random.randn(len(idx)), idx)
ps结构稍显复杂, 解释一下, 首先利用 numpy 的 random.randn()函数生成一些随机浮点数, 在这里是传入了 idx 的长度作为参数, 所以就会生成 10个随机的浮点数, 并且是以数组的形式返回. 然后是用 Pandas 的 Series()函数给这个数组加上索引, (按照我前面讲过的方法, 按下 shift+tab 就可以查看任意函数的用法, 这里 Series() 函数的第一个参数刚好是数组, 第二个参数就是索引), 索引的值, 就是我们上面生成的 period 对象:
2011Q1 -0.108024
2011Q2 -0.535832
2011Q3 1.258304
2011Q4 -0.490206
2012Q1 -1.517975
2012Q2 0.329804
2012Q3 -0.017833
2012Q4 -1.739612
2013Q1 -0.349370
2013Q2 0.341614
Freq: Q-DEC, dtype: float64查看数组的索引:
ps.index输出:
PeriodIndex(['2011Q1', '2011Q2', '2011Q3', '2011Q4', '2012Q1', '2012Q2',
'2012Q3', '2012Q4', '2013Q1', '2013Q2'],
dtype='period[Q-DEC]', freq='Q-DEC')按年份查看数据:
ps['2011']输出:
2011Q1 -0.108024
2011Q2 -0.535832
2011Q3 1.258304
2011Q4 -0.490206
Freq: Q-DEC, dtype: float64跨年查看数据:
ps['2011':'2013']输出:
2011Q1 -0.108024
2011Q2 -0.535832
2011Q3 1.258304
2011Q4 -0.490206
2012Q1 -1.517975
2012Q2 0.329804
2012Q3 -0.017833
2012Q4 -1.739612
2013Q1 -0.349370
2013Q2 0.341614
Freq: Q-DEC, dtype: float64如果觉得 Q1, Q2 这种形式不符合人的阅读习惯, 还可以将其转为正常的日期格式:
pst = ps.to_timestamp()
pst输出:
2011-01-01 -0.108024
2011-04-01 -0.535832
2011-07-01 1.258304
2011-10-01 -0.490206
2012-01-01 -1.517975
2012-04-01 0.329804
2012-07-01 -0.017833
2012-10-01 -1.739612
2013-01-01 -0.349370
2013-04-01 0.341614
Freq: QS-OCT, dtype: float64再开查看一下改变后的索引:
pst.index输出:
DatetimeIndex(['2011-01-01', '2011-04-01', '2011-07-01', '2011-10-01',
'2012-01-01', '2012-04-01', '2012-07-01', '2012-10-01',
'2013-01-01', '2013-04-01'],
dtype='datetime64[ns]', freq='QS-OCT')当然, 还可以再转回去:
pst.to_period()输出:
2011Q1 -0.108024
2011Q2 -0.535832
2011Q3 1.258304
2011Q4 -0.490206
2012Q1 -1.517975
2012Q2 0.329804
2012Q3 -0.017833
2012Q4 -1.739612
2013Q1 -0.349370
2013Q2 0.341614
Freq: Q-DEC, dtype: float64再来举一个现实的例子, 请看下图, 上面是我们从 csv 文件直接导过来的数据格式, 但是我们希望转换成下面的格式, 首先是让季度时间段作为索引列, 并且加上每个季度的起始时间和结束时间:
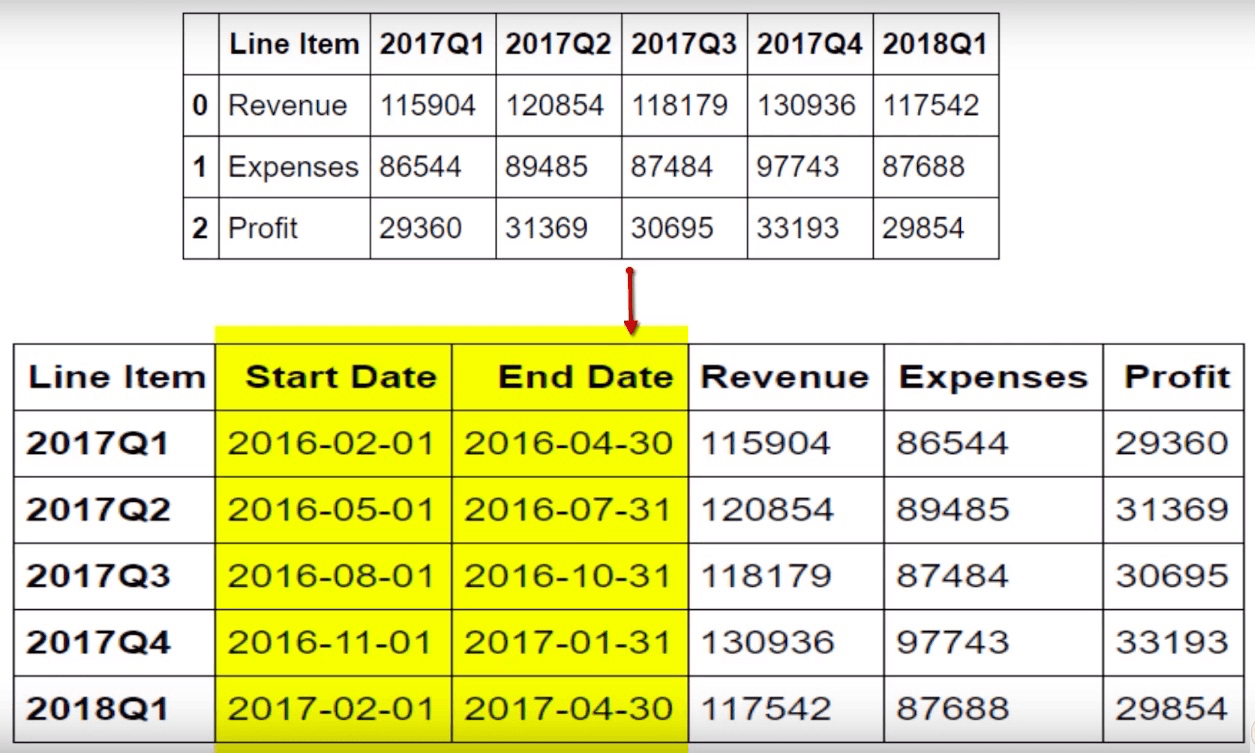
首先我把 csv 文件的截图放在这里, 大家需要手动敲一下:
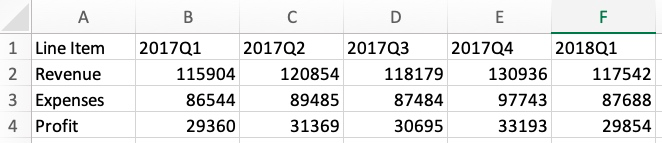
引入文件:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/18_ts_period/wmt.csv')
df输出:
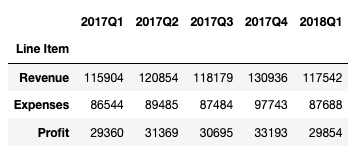
设置索引列:
df.set_index('Line Item', inplace=True)
df输出:
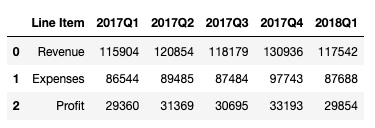
转换索引列:
df = df.T
df输出:
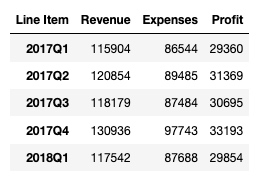
获取这个数据表的索引 list:
df.index输出:
Index(['2017Q1', '2017Q2', '2017Q3', '2017Q4', '2018Q1'], dtype='object')利用 Pandas 的 PeriodIndex()函数, 索引 list 的数据格式改为 period 对象的 list:
df.index = pd.PeriodIndex(df.index, freq = 'Q')
df.index输出:
PeriodIndex(['2017Q1', '2017Q2', '2017Q3', '2017Q4', '2018Q1'], dtype='period[Q-DEC]', freq='Q-DEC')转换为 period 对象就是为了可以调用 start_time()和 end_time()函数.
接下来就是为 df 增加两个字段:
df['start time'] = df.index.map(lambda x: x.start_time)
df输出:
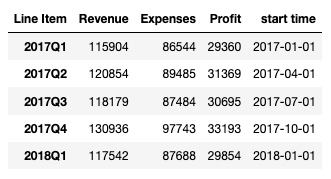
df['end time'] = df.index.map(lambda x: x.end_time)
df输出:
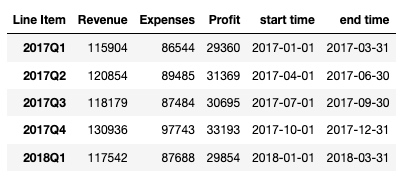
以上, 就是这一节的全部内容, 方法零零碎碎的看着有点多, 我觉得也不用一下都记到吧, 主要就是先照着敲一遍, 大概有个印象.
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



